 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARM: An AutoRegressive Large Multimodal Model with Unified Discrete Representations
Jun 09, 2026This paper introduces ARM, a discrete representation-based AutoRegressive Model that unifies image understanding, generation, and editing within a next-token prediction framework. ARM is built on three efforts: first, we train a discrete semantic visual tokenizer that maps images into compact token sequences. Our tokenizer is supervised with multiple objectives that jointly promote semantic discriminability, language alignment and faithful reconstruction, thereby supporting diverse tasks in a shared latent space. With this, we train a 7B autoregressive model over large-scale text and image token sequences, seamlessly developing vision-language perception and generation capabilities. Finally, to further improve preference-aligned behavior for text-to-image generation and instruction-guided editing, ARM applies reinforcement learning (RL) to optimize task-level objectives such as visual quality, instruction adherence, and edit consistency. Surprisingly, the results show that RL not only substantially improves performance on the target tasks (e.g., raising WISE overall from 0.50 to 0.56, GEdit-Bench-EN G_O from 5.75 to 6.68), but also induces cross-task synergy between text-to-image generation and editing. Collectively, these findings highlight autoregressive modeling, when paired with strong representations and preference optimization, as a scalable foundation for multimodal intelligence. Code: https://github.com/wdrink/ARM.
TeCoNeRV: Leveraging Temporal Coherence for Compressible Neural Representations for Videos
Feb 18, 2026Implicit Neural Representations (INRs) have recently demonstrated impressive performance for video compression. However, since a separate INR must be overfit for each video, scaling to high-resolution videos while maintaining encoding efficiency remains a significant challenge. Hypernetwork-based approaches predict INR weights (hyponetworks) for unseen videos at high speeds, but with low quality, large compressed size, and prohibitive memory needs at higher resolutions. We address these fundamental limitations through three key contributions: (1) an approach that decomposes the weight prediction task spatially and temporally, by breaking short video segments into patch tubelets, to reduce the pretraining memory overhead by 20$\times$; (2) a residual-based storage scheme that captures only differences between consecutive segment representations, significantly reducing bitstream size; and (3) a temporal coherence regularization framework that encourages changes in the weight space to be correlated with video content. Our proposed method, TeCoNeRV, achieves substantial improvements of 2.47dB and 5.35dB PSNR over the baseline at 480p and 720p on UVG, with 36% lower bitrates and 1.5-3$\times$ faster encoding speeds. With our low memory usage, we are the first hypernetwork approach to demonstrate results at 480p, 720p and 1080p on UVG, HEVC and MCL-JCV. Our project page is available at https://namithap10.github.io/teconerv/ .
Towards Understanding Best Practices for Quantization of Vision-Language Models
Jan 21, 2026Large language models (LLMs) deliver impressive results for a variety of tasks, but state-of-the-art systems require fast GPUs with large amounts of memory. To reduce both the memory and latency of these systems, practitioners quantize their learned parameters, typically at half precision. A growing body of research focuses on preserving the model performance with more aggressive bit widths, and some work has been done to apply these strategies to other models, like vision transformers. In our study we investigate how a variety of quantization methods, including state-of-the-art GPTQ and AWQ, can be applied effectively to multimodal pipelines comprised of vision models, language models, and their connectors. We address how performance on captioning, retrieval, and question answering can be affected by bit width, quantization method, and which portion of the pipeline the quantization is used for. Results reveal that ViT and LLM exhibit comparable importance in model performance, despite significant differences in parameter size, and that lower-bit quantization of the LLM achieves high accuracy at reduced bits per weight (bpw). These findings provide practical insights for efficient deployment of MLLMs and highlight the value of exploration for understanding component sensitivities in multimodal models. Our code is available at https://github.com/gautomdas/mmq.
Implicit Neural Representation Facilitates Unified Universal Vision Encoding
Jan 20, 2026Models for image representation learning are typically designed for either recognition or generation. Various forms of contrastive learning help models learn to convert images to embeddings that are useful for classification, detection, and segmentation. On the other hand, models can be trained to reconstruct images with pixel-wise, perceptual, and adversarial losses in order to learn a latent space that is useful for image generation. We seek to unify these two directions with a first-of-its-kind model that learns representations which are simultaneously useful for recognition and generation. We train our model as a hyper-network for implicit neural representation, which learns to map images to model weights for fast, accurate reconstruction. We further integrate our INR hyper-network with knowledge distillation to improve its generalization and performance. Beyond the novel training design, the model also learns an unprecedented compressed embedding space with outstanding performance for various visual tasks. The complete model competes with state-of-the-art results for image representation learning, while also enabling generative capabilities with its high-quality tiny embeddings. The code is available at https://github.com/tiktok/huvr.
AgentComp: From Agentic Reasoning to Compositional Mastery in Text-to-Image Models
Dec 09, 2025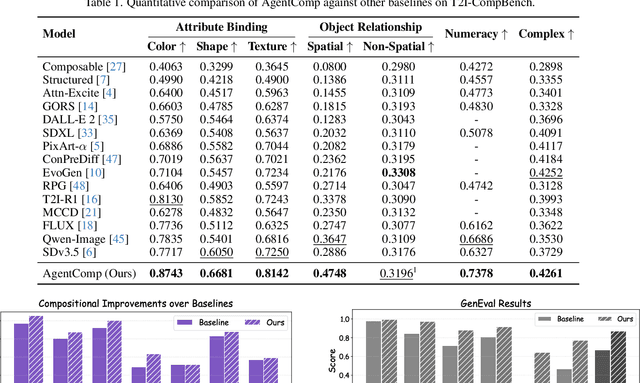

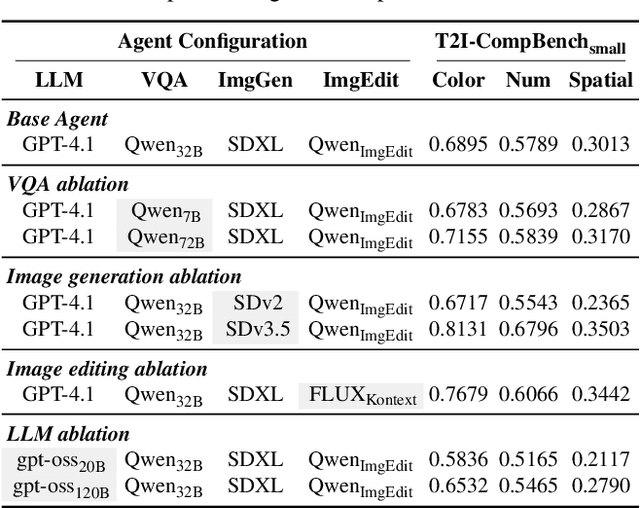
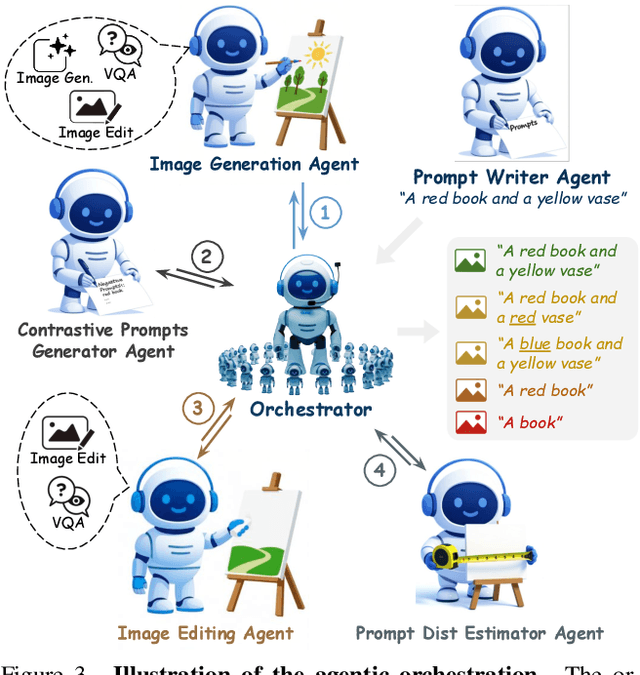
Text-to-image generative models have achieved remarkable visual quality but still struggle with compositionality$-$accurately capturing object relationships, attribute bindings, and fine-grained details in prompts. A key limitation is that models are not explicitly trained to differentiate between compositionally similar prompts and images, resulting in outputs that are close to the intended description yet deviate in fine-grained details. To address this, we propose AgentComp, a framework that explicitly trains models to better differentiate such compositional variations and enhance their reasoning ability. AgentComp leverages the reasoning and tool-use capabilities of large language models equipped with image generation, editing, and VQA tools to autonomously construct compositional datasets. Using these datasets, we apply an agentic preference optimization method to fine-tune text-to-image models, enabling them to better distinguish between compositionally similar samples and resulting in overall stronger compositional generation ability. AgentComp achieves state-of-the-art results on compositionality benchmarks such as T2I-CompBench, without compromising image quality$-$a common drawback in prior approaches$-$and even generalizes to other capabilities not explicitly trained for, such as text rendering.
Towards Multimodal Understanding via Stable Diffusion as a Task-Aware Feature Extractor
Jul 09, 2025Recent advances in multimodal large language models (MLLMs) have enabled image-based question-answering capabilities. However, a key limitation is the use of CLIP as the visual encoder; while it can capture coarse global information, it often can miss fine-grained details that are relevant to the input query. To address these shortcomings, this work studies whether pre-trained text-to-image diffusion models can serve as instruction-aware visual encoders. Through an analysis of their internal representations, we find diffusion features are both rich in semantics and can encode strong image-text alignment. Moreover, we find that we can leverage text conditioning to focus the model on regions relevant to the input question. We then investigate how to align these features with large language models and uncover a leakage phenomenon, where the LLM can inadvertently recover information from the original diffusion prompt. We analyze the causes of this leakage and propose a mitigation strategy. Based on these insights, we explore a simple fusion strategy that utilizes both CLIP and conditional diffusion features. We evaluate our approach on both general VQA and specialized MLLM benchmarks, demonstrating the promise of diffusion models for visual understanding, particularly in vision-centric tasks that require spatial and compositional reasoning. Our project page can be found https://vatsalag99.github.io/mustafar/.
Evolutionary Caching to Accelerate Your Off-the-Shelf Diffusion Model
Jun 18, 2025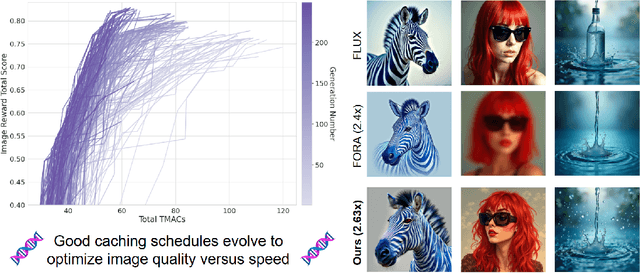

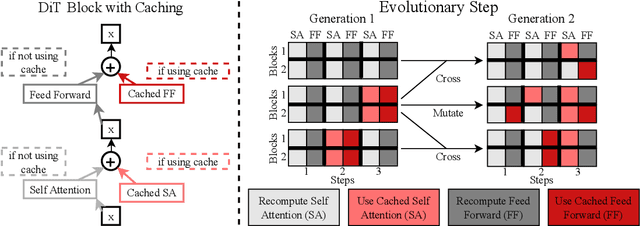
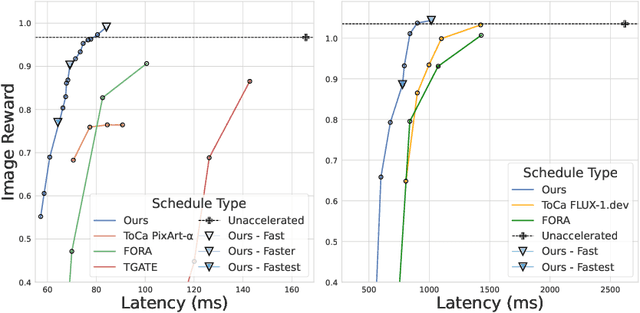
Diffusion-based image generation models excel at producing high-quality synthetic content, but suffer from slow and computationally expensive inference. Prior work has attempted to mitigate this by caching and reusing features within diffusion transformers across inference steps. These methods, however, often rely on rigid heuristics that result in limited acceleration or poor generalization across architectures. We propose Evolutionary Caching to Accelerate Diffusion models (ECAD), a genetic algorithm that learns efficient, per-model, caching schedules forming a Pareto frontier, using only a small set of calibration prompts. ECAD requires no modifications to network parameters or reference images. It offers significant inference speedups, enables fine-grained control over the quality-latency trade-off, and adapts seamlessly to different diffusion models. Notably, ECAD's learned schedules can generalize effectively to resolutions and model variants not seen during calibration. We evaluate ECAD on PixArt-alpha, PixArt-Sigma, and FLUX-1.dev using multiple metrics (FID, CLIP, Image Reward) across diverse benchmarks (COCO, MJHQ-30k, PartiPrompts), demonstrating consistent improvements over previous approaches. On PixArt-alpha, ECAD identifies a schedule that outperforms the previous state-of-the-art method by 4.47 COCO FID while increasing inference speedup from 2.35x to 2.58x. Our results establish ECAD as a scalable and generalizable approach for accelerating diffusion inference. Our project website is available at https://aniaggarwal.github.io/ecad and our code is available at https://github.com/aniaggarwal/ecad.
Utilization of Neighbor Information for Image Classification with Different Levels of Supervision
Mar 18, 2025We propose to bridge the gap between semi-supervised and unsupervised image recognition with a flexible method that performs well for both generalized category discovery (GCD) and image clustering. Despite the overlap in motivation between these tasks, the methods themselves are restricted to a single task -- GCD methods are reliant on the labeled portion of the data, and deep image clustering methods have no built-in way to leverage the labels efficiently. We connect the two regimes with an innovative approach that Utilizes Neighbor Information for Classification (UNIC) both in the unsupervised (clustering) and semisupervised (GCD) setting. State-of-the-art clustering methods already rely heavily on nearest neighbors. We improve on their results substantially in two parts, first with a sampling and cleaning strategy where we identify accurate positive and negative neighbors, and secondly by finetuning the backbone with clustering losses computed by sampling both types of neighbors. We then adapt this pipeline to GCD by utilizing the labelled images as ground truth neighbors. Our method yields state-of-the-art results for both clustering (+3% ImageNet-100, Imagenet200) and GCD (+0.8% ImageNet-100, +5% CUB, +2% SCars, +4% Aircraft).
NeRF-Aug: Data Augmentation for Robotics with Neural Radiance Fields
Nov 04, 2024
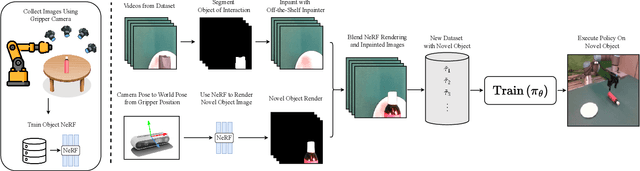


Training a policy that can generalize to unknown objects is a long standing challenge within the field of robotics. The performance of a policy often drops significantly in situations where an object in the scene was not seen during training. To solve this problem, we present NeRF-Aug, a novel method that is capable of teaching a policy to interact with objects that are not present in the dataset. This approach differs from existing approaches by leveraging the speed and photorealism of a neural radiance field for augmentation. NeRF- Aug both creates more photorealistic data and runs 3.83 times faster than existing methods. We demonstrate the effectiveness of our method on 4 tasks with 11 novel objects that have no expert demonstration data. We achieve an average 69.1% success rate increase over existing methods. See video results at https://nerf-aug.github.io.
Latent-INR: A Flexible Framework for Implicit Representations of Videos with Discriminative Semantics
Aug 05, 2024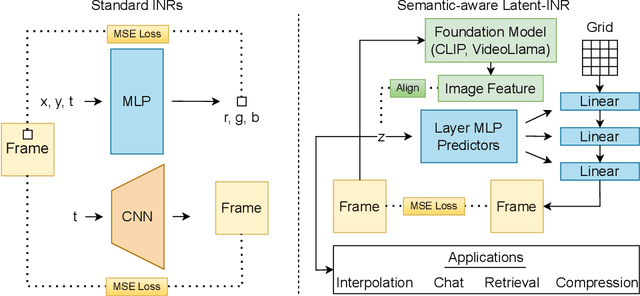
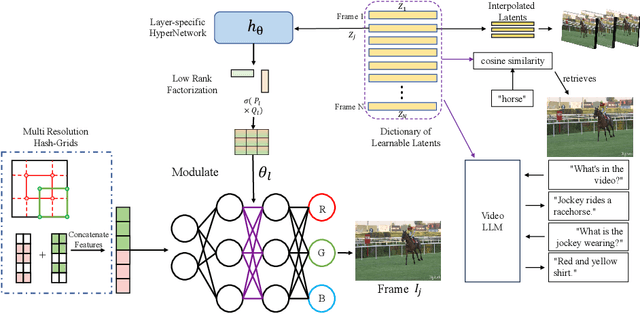
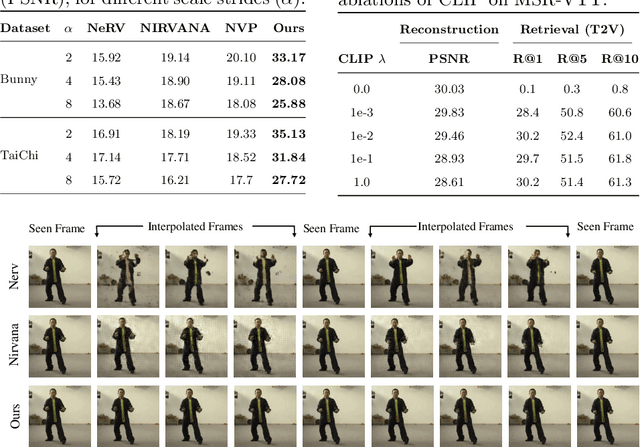
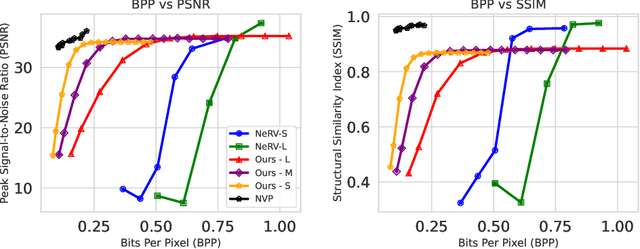
Implicit Neural Networks (INRs) have emerged as powerful representations to encode all forms of data, including images, videos, audios, and scenes. With video, many INRs for video have been proposed for the compression task, and recent methods feature significant improvements with respect to encoding time, storage, and reconstruction quality. However, these encoded representations lack semantic meaning, so they cannot be used for any downstream tasks that require such properties, such as retrieval. This can act as a barrier for adoption of video INRs over traditional codecs as they do not offer any significant edge apart from compression. To alleviate this, we propose a flexible framework that decouples the spatial and temporal aspects of the video INR. We accomplish this with a dictionary of per-frame latents that are learned jointly with a set of video specific hypernetworks, such that given a latent, these hypernetworks can predict the INR weights to reconstruct the given frame. This framework not only retains the compression efficiency, but the learned latents can be aligned with features from large vision models, which grants them discriminative properties. We align these latents with CLIP and show good performance for both compression and video retrieval tasks. By aligning with VideoLlama, we are able to perform open-ended chat with our learned latents as the visual inputs. Additionally, the learned latents serve as a proxy for the underlying weights, allowing us perform tasks like video interpolation. These semantic properties and applications, existing simultaneously with ability to perform compression, interpolation, and superresolution properties, are a first in this field of work.