 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-aligned Space-time Tokens for Few-shot Action Recognition
Jul 25, 2024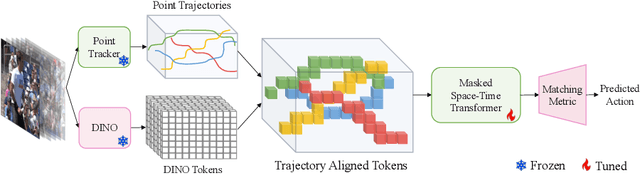
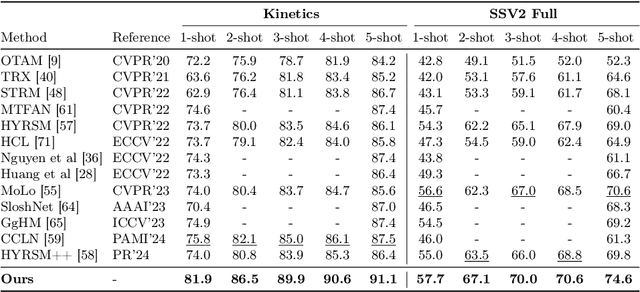
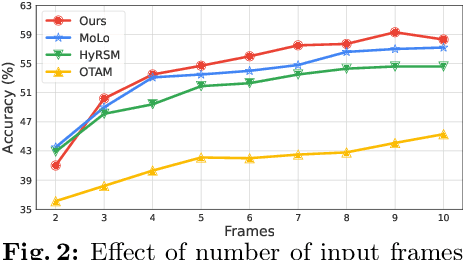
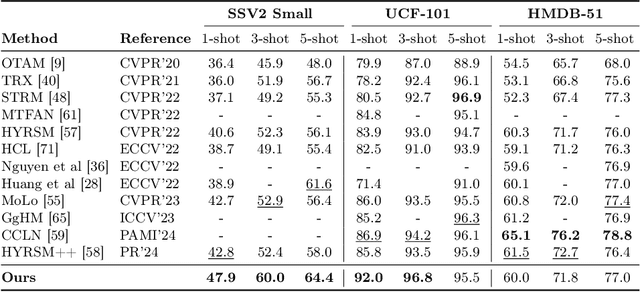
We propose a simple yet effective approach for few-shot action recognition, emphasizing the disentanglement of motion and appearance representations. By harnessing recent progress in tracking, specifically point trajectories and self-supervised representation learning, we build trajectory-aligned tokens (TATs) that capture motion and appearance information. This approach significantly reduces the data requirements while retaining essential information. To process these representations, we use a Masked Space-time Transformer that effectively learns to aggregate information to facilitate few-shot action recognition. We demonstrate state-of-the-art results on few-shot action recognition across multiple datasets. Our project page is available at https://www.cs.umd.edu/~pulkit/tats
Explaining the Implicit Neural Canvas: Connecting Pixels to Neurons by Tracing their Contributions
Jan 18, 2024The many variations of Implicit Neural Representations (INRs), where a neural network is trained as a continuous representation of a signal, have tremendous practical utility for downstream tasks including novel view synthesis, video compression, and image superresolution. Unfortunately, the inner workings of these networks are seriously under-studied. Our work, eXplaining the Implicit Neural Canvas (XINC), is a unified framework for explaining properties of INRs by examining the strength of each neuron's contribution to each output pixel. We call the aggregate of these contribution maps the Implicit Neural Canvas and we use this concept to demonstrate that the INRs which we study learn to ''see'' the frames they represent in surprising ways. For example, INRs tend to have highly distributed representations. While lacking high-level object semantics, they have a significant bias for color and edges, and are almost entirely space-agnostic. We arrive at our conclusions by examining how objects are represented across time in video INRs, using clustering to visualize similar neurons across layers and architectures, and show that this is dominated by motion. These insights demonstrate the general usefulness of our analysis framework. Our project page is available at https://namithap10.github.io/xinc.
Prototypical Metric Transfer Learning for Continuous Speech Keyword Spotting With Limited Training Data
Jan 12, 2019
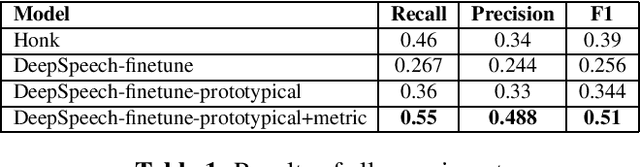
Continuous Speech Keyword Spotting (CSKS) is the problem of spotting keywords in recorded conversations, when a small number of instances of keywords are available in training data. Unlike the more common Keyword Spotting, where an algorithm needs to detect lone keywords or short phrases like "Alexa", "Cortana", "Hi Alexa!", "Whatsup Octavia?" etc. in speech, CSKS needs to filter out embedded words from a continuous flow of speech, ie. spot "Anna" and "github" in "I know a developer named Anna who can look into this github issue." Apart from the issue of limited training data availability, CSKS is an extremely imbalanced classification problem. We address the limitations of simple keyword spotting baselines for both aforementioned challenges by using a novel combination of loss functions (Prototypical networks' loss and metric loss) and transfer learning. Our method improves F1 score by over 10%.
LeukoNet: DCT-based CNN architecture for the classification of normal versus Leukemic blasts in B-ALL Cancer
Nov 04, 2018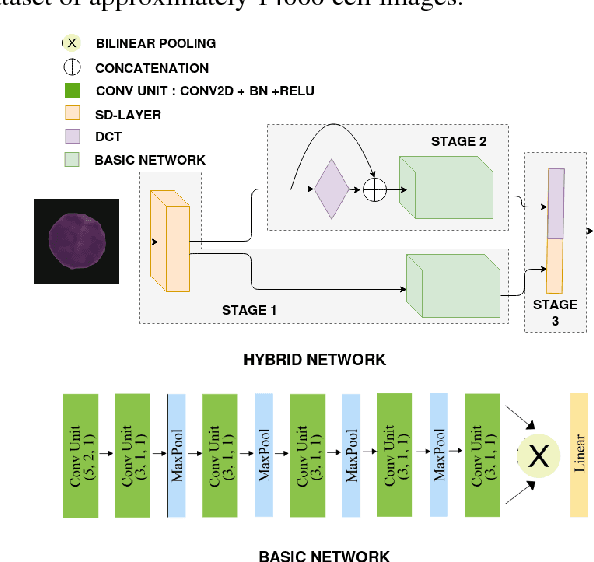
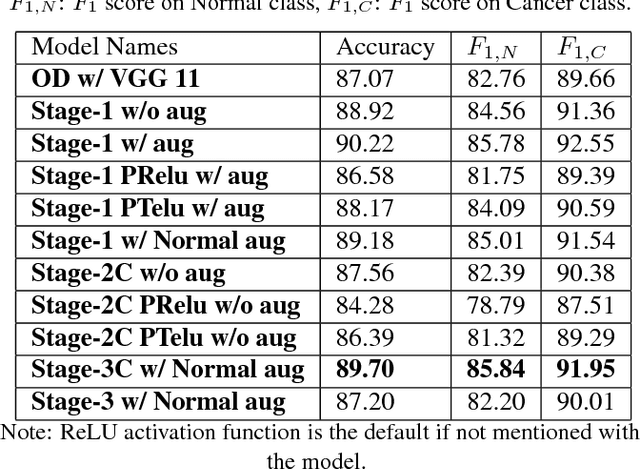
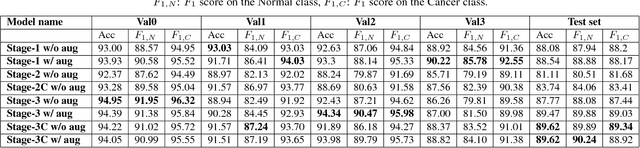
Acute lymphoblastic leukemia (ALL) constitutes approximately 25% of the pediatric cancers. In general, the task of identifying immature leukemic blasts from normal cells under the microscope is challenging because morphologically the images of the two cells appear similar. In this paper, we propose a deep learning framework for classifying immature leukemic blasts and normal cells. The proposed model combines the Discrete Cosine Transform (DCT) domain features extracted via CNN with the Optical Density (OD) space features to build a robust classifier. Elaborate experiments have been conducted to validate the proposed LeukoNet classifier.
U-SegNet: Fully Convolutional Neural Network based Automated Brain tissue segmentation Tool
Jun 12, 2018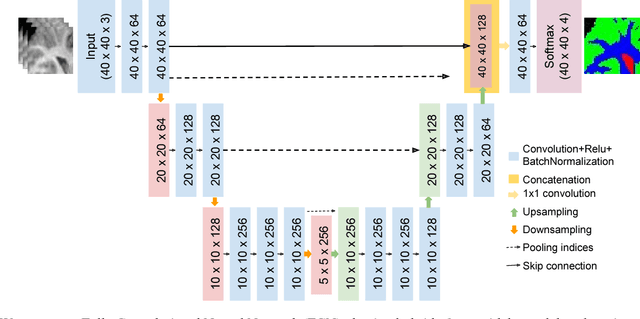
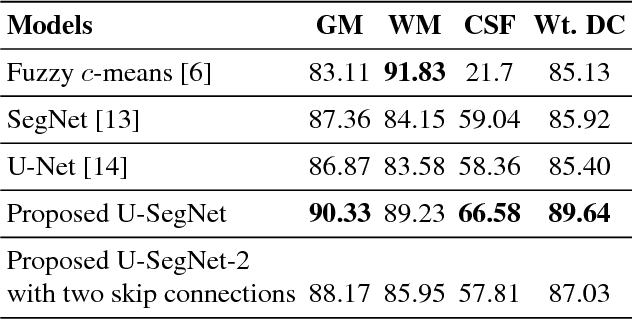

Automated brain tissue segmentation into white matter (WM), gray matter (GM), and cerebro-spinal fluid (CSF) from magnetic resonance images (MRI) is helpful in the diagnosis of neuro-disorders such as epilepsy, Alzheimer's, multiple sclerosis, etc. However, thin GM structures at the periphery of cortex and smooth transitions on tissue boundaries such as between GM and WM, or WM and CSF pose difficulty in building a reliable segmentation tool. This paper proposes a Fully Convolutional Neural Network (FCN) tool, that is a hybrid of two widely used deep learning segmentation architectures SegNet and U-Net, for improved brain tissue segmentation. We propose a skip connection inspired from U-Net, in the SegNet architetcure, to incorporate fine multiscale information for better tissue boundary identification. We show that the proposed U-SegNet architecture, improves segmentation performance, as measured by average dice ratio, to 89.74% on the widely used IBSR dataset consisting of T-1 weighted MRI volumes of 18 subjects.
Anatomical labeling of brain CT scan anomalies using multi-context nearest neighbor relation networks
Jan 22, 2018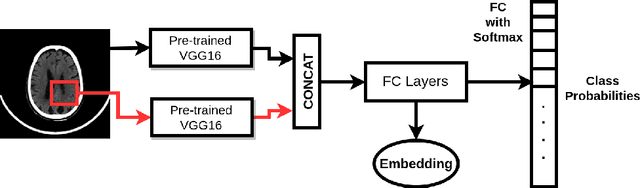
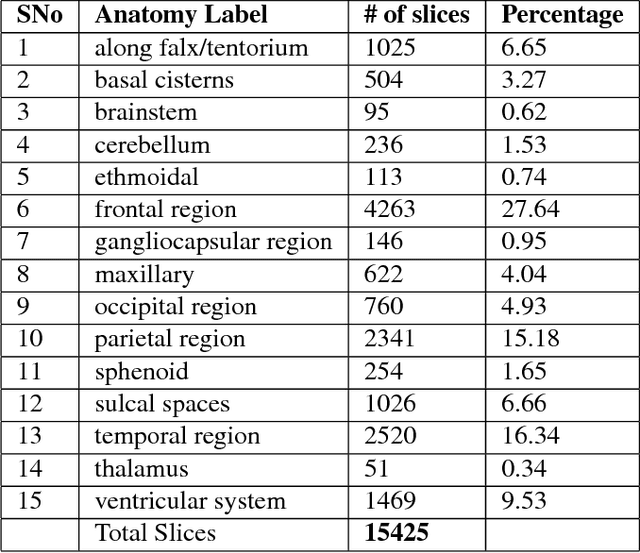
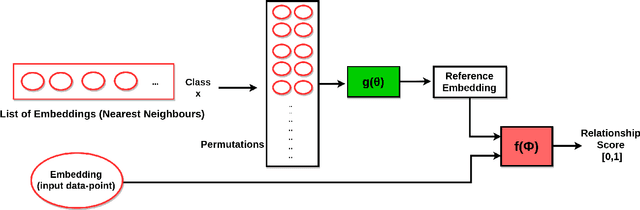
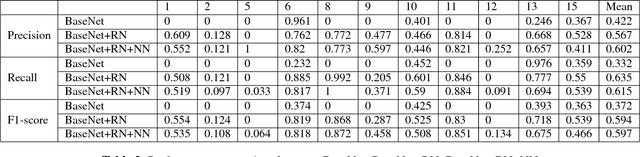
This work is an endeavor to develop a deep learning methodology for automated anatomical labeling of a given region of interest (ROI) in brain computed tomography (CT) scans. We combine both local and global context to obtain a representation of the ROI. We then use Relation Networks (RNs) to predict the corresponding anatomy of the ROI based on its relationship score for each class. Further, we propose a novel strategy employing nearest neighbors approach for training RNs. We train RNs to learn the relationship of the target ROI with the joint representation of its nearest neighbors in each class instead of all data-points in each class. The proposed strategy leads to better training of RNs along with increased performance as compared to training baseline RN network.
RADNET: Radiologist Level Accuracy using Deep Learning for HEMORRHAGE detection in CT Scans
Jan 03, 2018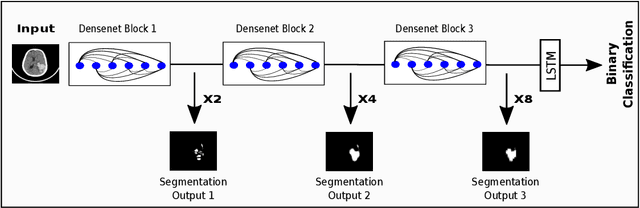
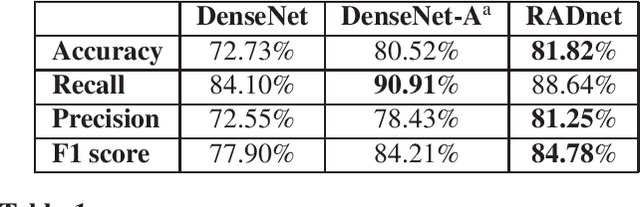
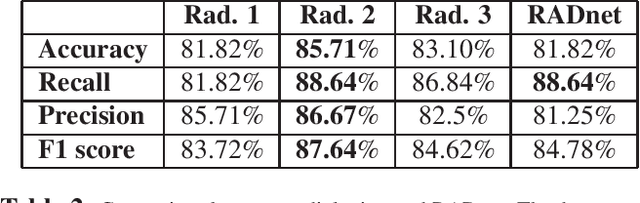
We describe a deep learning approach for automated brain hemorrhage detection from computed tomography (CT) scans. Our model emulates the procedure followed by radiologists to analyse a 3D CT scan in real-world. Similar to radiologists, the model sifts through 2D cross-sectional slices while paying close attention to potential hemorrhagic regions. Further, the model utilizes 3D context from neighboring slices to improve predictions at each slice and subsequently, aggregates the slice-level predictions to provide diagnosis at CT level. We refer to our proposed approach as Recurrent Attention DenseNet (RADnet) as it employs original DenseNet architecture along with adding the components of attention for slice level predictions and recurrent neural network layer for incorporating 3D context. The real-world performance of RADnet has been benchmarked against independent analysis performed by three senior radiologists for 77 brain CTs. RADnet demonstrates 81.82% hemorrhage prediction accuracy at CT level that is comparable to radiologists. Further, RADnet achieves higher recall than two of the three radiologists, which is remarkable.
A Big Data Analysis Framework Using Apache Spark and Deep Learning
Nov 25, 2017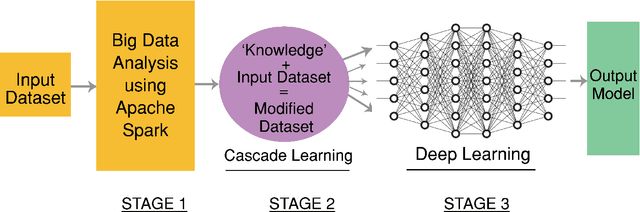
With the spreading prevalence of Big Data, many advances have recently been made in this field. Frameworks such as Apache Hadoop and Apache Spark have gained a lot of traction over the past decades and have become massively popular, especially in industries. It is becoming increasingly evident that effective big data analysis is key to solving artificial intelligence problems. Thus, a multi-algorithm library was implemented in the Spark framework, called MLlib. While this library supports multiple machine learning algorithms, there is still scope to use the Spark setup efficiently for highly time-intensive and computationally expensive procedures like deep learning. In this paper, we propose a novel framework that combines the distributive computational abilities of Apache Spark and the advanced machine learning architecture of a deep multi-layer perceptron (MLP), using the popular concept of Cascade Learning. We conduct empirical analysis of our framework on two real world datasets. The results are encouraging and corroborate our proposed framework, in turn proving that it is an improvement over traditional big data analysis methods that use either Spark or Deep learning as individual elements.
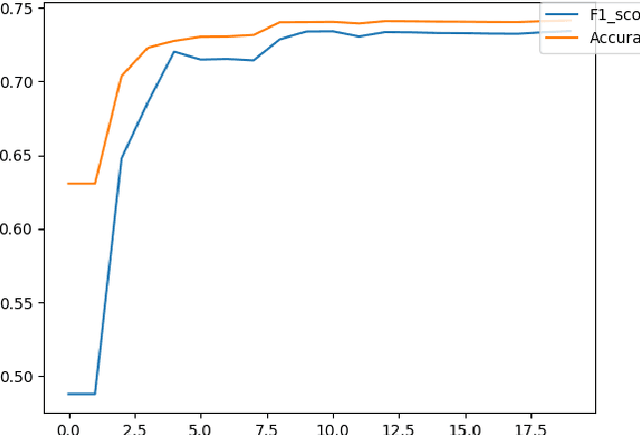
Boosted Cascaded Convnets for Multilabel Classification of Thoracic Diseases in Chest Radiographs
Nov 23, 2017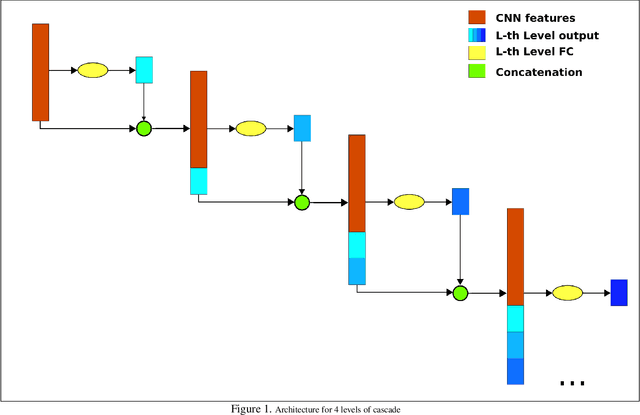
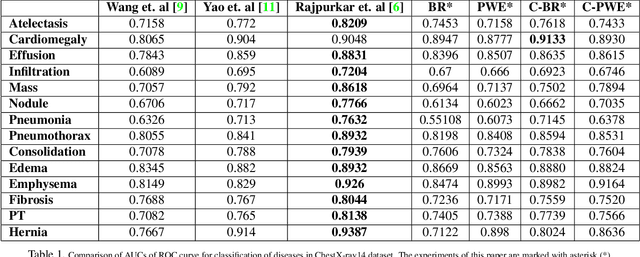
Chest X-ray is one of the most accessible medical imaging technique for diagnosis of multiple diseases. With the availability of ChestX-ray14, which is a massive dataset of chest X-ray images and provides annotations for 14 thoracic diseases; it is possible to train Deep Convolutional Neural Networks (DCNN) to build Computer Aided Diagnosis (CAD) systems. In this work, we experiment a set of deep learning models and present a cascaded deep neural network that can diagnose all 14 pathologies better than the baseline and is competitive with other published methods. Our work provides the quantitative results to answer following research questions for the dataset: 1) What loss functions to use for training DCNN from scratch on ChestX-ray14 dataset that demonstrates high class imbalance and label co occurrence? 2) How to use cascading to model label dependency and to improve accuracy of the deep learning model?