 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-aligned Space-time Tokens for Few-shot Action Recognition
Jul 25, 2024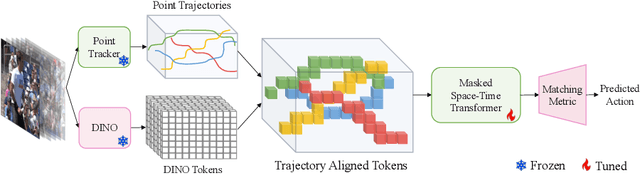
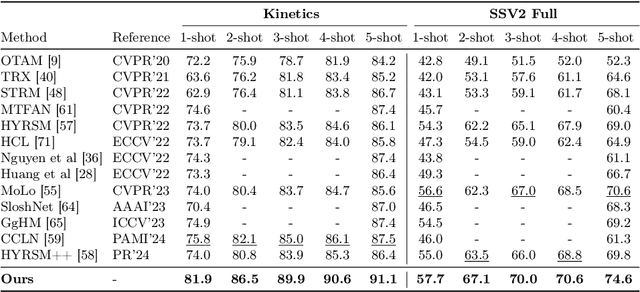
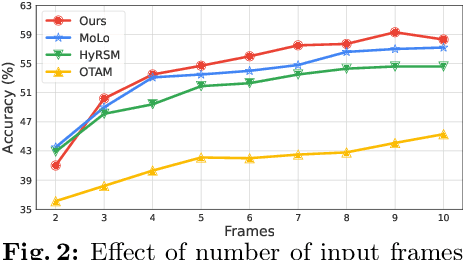
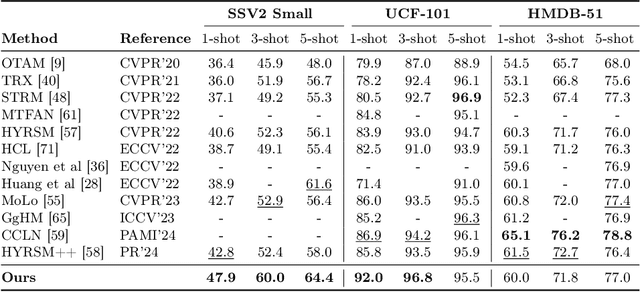
We propose a simple yet effective approach for few-shot action recognition, emphasizing the disentanglement of motion and appearance representations. By harnessing recent progress in tracking, specifically point trajectories and self-supervised representation learning, we build trajectory-aligned tokens (TATs) that capture motion and appearance information. This approach significantly reduces the data requirements while retaining essential information. To process these representations, we use a Masked Space-time Transformer that effectively learns to aggregate information to facilitate few-shot action recognition. We demonstrate state-of-the-art results on few-shot action recognition across multiple datasets. Our project page is available at https://www.cs.umd.edu/~pulkit/tats