 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Autoencoders are Scalable Image Tokenizers
Jan 30, 2025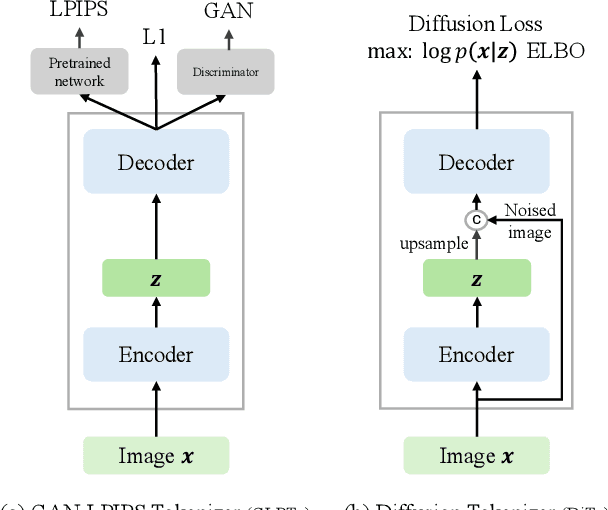



Tokenizing images into compact visual representations is a key step in learning efficient and high-quality image generative models. We present a simple diffusion tokenizer (DiTo) that learns compact visual representations for image generation models. Our key insight is that a single learning objective, diffusion L2 loss, can be used for training scalable image tokenizers. Since diffusion is already widely used for image generation, our insight greatly simplifies training such tokenizers. In contrast, current state-of-the-art tokenizers rely on an empirically found combination of heuristics and losses, thus requiring a complex training recipe that relies on non-trivially balancing different losses and pretrained supervised models. We show design decisions, along with theoretical grounding, that enable us to scale DiTo for learning competitive image representations. Our results show that DiTo is a simpler, scalable, and self-supervised alternative to the current state-of-the-art image tokenizer which is supervised. DiTo achieves competitive or better quality than state-of-the-art in image reconstruction and downstream image generation tasks.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Trajectory-aligned Space-time Tokens for Few-shot Action Recognition
Jul 25, 2024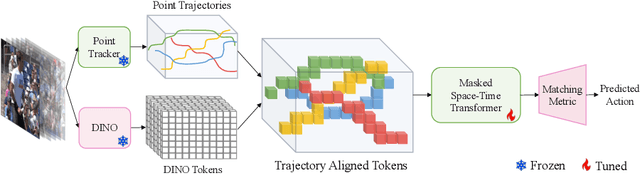
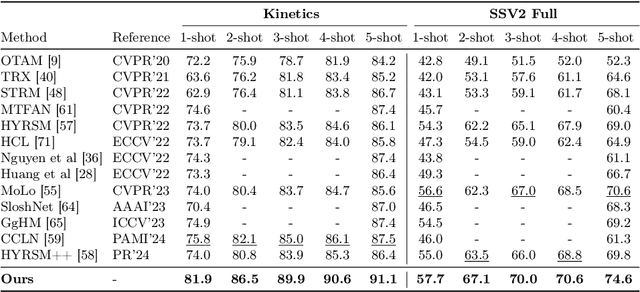
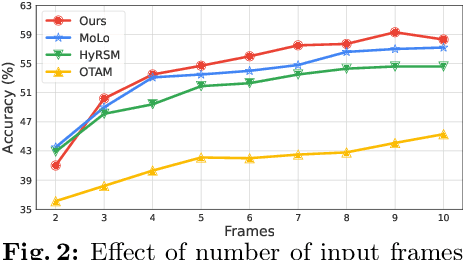
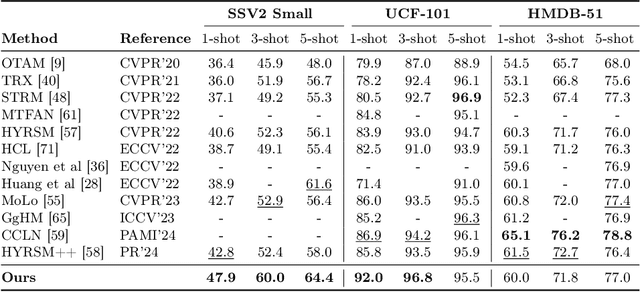
We propose a simple yet effective approach for few-shot action recognition, emphasizing the disentanglement of motion and appearance representations. By harnessing recent progress in tracking, specifically point trajectories and self-supervised representation learning, we build trajectory-aligned tokens (TATs) that capture motion and appearance information. This approach significantly reduces the data requirements while retaining essential information. To process these representations, we use a Masked Space-time Transformer that effectively learns to aggregate information to facilitate few-shot action recognition. We demonstrate state-of-the-art results on few-shot action recognition across multiple datasets. Our project page is available at https://www.cs.umd.edu/~pulkit/tats
UVIS: Unsupervised Video Instance Segmentation
Jun 11, 2024



Video instance segmentation requires classifying, segmenting, and tracking every object across video frames. Unlike existing approaches that rely on masks, boxes, or category labels, we propose UVIS, a novel Unsupervised Video Instance Segmentation (UVIS) framework that can perform video instance segmentation without any video annotations or dense label-based pretraining. Our key insight comes from leveraging the dense shape prior from the self-supervised vision foundation model DINO and the openset recognition ability from the image-caption supervised vision-language model CLIP. Our UVIS framework consists of three essential steps: frame-level pseudo-label generation, transformer-based VIS model training, and query-based tracking. To improve the quality of VIS predictions in the unsupervised setup, we introduce a dual-memory design. This design includes a semantic memory bank for generating accurate pseudo-labels and a tracking memory bank for maintaining temporal consistency in object tracks. We evaluate our approach on three standard VIS benchmarks, namely YoutubeVIS-2019, YoutubeVIS-2021, and Occluded VIS. Our UVIS achieves 21.1 AP on YoutubeVIS-2019 without any video annotations or dense pretraining, demonstrating the potential of our unsupervised VIS framework.
InstanceDiffusion: Instance-level Control for Image Generation
Feb 05, 2024Text-to-image diffusion models produce high quality images but do not offer control over individual instances in the image. We introduce InstanceDiffusion that adds precise instance-level control to text-to-image diffusion models. InstanceDiffusion supports free-form language conditions per instance and allows flexible ways to specify instance locations such as simple single points, scribbles, bounding boxes or intricate instance segmentation masks, and combinations thereof. We propose three major changes to text-to-image models that enable precise instance-level control. Our UniFusion block enables instance-level conditions for text-to-image models, the ScaleU block improves image fidelity, and our Multi-instance Sampler improves generations for multiple instances. InstanceDiffusion significantly surpasses specialized state-of-the-art models for each location condition. Notably, on the COCO dataset, we outperform previous state-of-the-art by 20.4% AP$_{50}^\text{box}$ for box inputs, and 25.4% IoU for mask inputs.
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
Nov 17, 2023We present Emu Video, a text-to-video generation model that factorizes the generation into two steps: first generating an image conditioned on the text, and then generating a video conditioned on the text and the generated image. We identify critical design decisions--adjusted noise schedules for diffusion, and multi-stage training--that enable us to directly generate high quality and high resolution videos, without requiring a deep cascade of models as in prior work. In human evaluations, our generated videos are strongly preferred in quality compared to all prior work--81% vs. Google's Imagen Video, 90% vs. Nvidia's PYOCO, and 96% vs. Meta's Make-A-Video. Our model outperforms commercial solutions such as RunwayML's Gen2 and Pika Labs. Finally, our factorizing approach naturally lends itself to animating images based on a user's text prompt, where our generations are preferred 96% over prior work.
SelfEval: Leveraging the discriminative nature of generative models for evaluation
Nov 17, 2023



In this work, we show that text-to-image generative models can be 'inverted' to assess their own text-image understanding capabilities in a completely automated manner. Our method, called SelfEval, uses the generative model to compute the likelihood of real images given text prompts, making the generative model directly applicable to discriminative tasks. Using SelfEval, we repurpose standard datasets created for evaluating multimodal text-image discriminative models to evaluate generative models in a fine-grained manner: assessing their performance on attribute binding, color recognition, counting, shape recognition, spatial understanding. To the best of our knowledge SelfEval is the first automated metric to show a high degree of agreement for measuring text-faithfulness with the gold-standard human evaluations across multiple models and benchmarks. Moreover, SelfEval enables us to evaluate generative models on challenging tasks such as Winoground image-score where they demonstrate competitive performance to discriminative models. We also show severe drawbacks of standard automated metrics such as CLIP-score to measure text faithfulness on benchmarks such as DrawBench, and how SelfEval sidesteps these issues. We hope SelfEval enables easy and reliable automated evaluation for diffusion models.
MOST: Multiple Object localization with Self-supervised Transformers for object discovery
Apr 11, 2023We tackle the challenging task of unsupervised object localization in this work. Recently, transformers trained with self-supervised learning have been shown to exhibit object localization properties without being trained for this task. In this work, we present Multiple Object localization with Self-supervised Transformers (MOST) that uses features of transformers trained using self-supervised learning to localize multiple objects in real world images. MOST analyzes the similarity maps of the features using box counting; a fractal analysis tool to identify tokens lying on foreground patches. The identified tokens are then clustered together, and tokens of each cluster are used to generate bounding boxes on foreground regions. Unlike recent state-of-the-art object localization methods, MOST can localize multiple objects per image and outperforms SOTA algorithms on several object localization and discovery benchmarks on PASCAL-VOC 07, 12 and COCO20k datasets. Additionally, we show that MOST can be used for self-supervised pre-training of object detectors, and yields consistent improvements on fully, semi-supervised object detection and unsupervised region proposal generation.
Sparsely Annotated Object Detection: A Region-based Semi-supervised Approach
Jan 12, 2022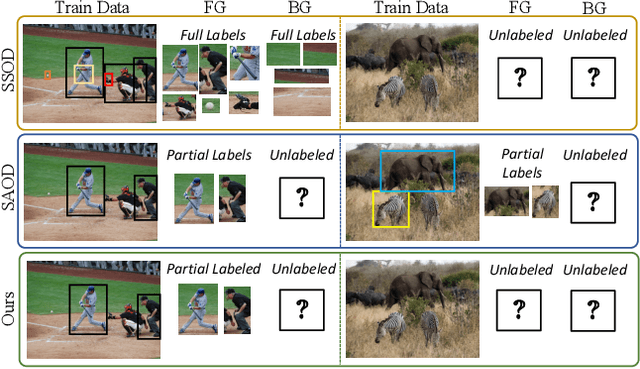
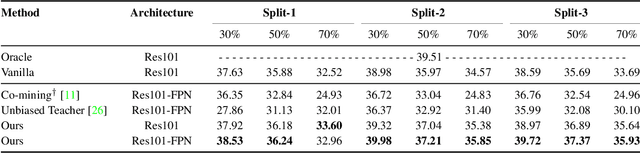


Research shows a noticeable drop in performance of object detectors when the training data has missing annotations, i.e. sparsely annotated data. Contemporary methods focus on proxies for missing ground-truth annotations either in the form of pseudo-labels or by re-weighing gradients for unlabeled boxes during training. In this work, we revisit the formulation of sparsely annotated object detection. We observe that sparsely annotated object detection can be considered a semi-supervised object detection problem at a region level. Building on this insight, we propose a region-based semi-supervised algorithm, that automatically identifies regions containing unlabeled foreground objects. Our algorithm then processes the labeled and un-labeled foreground regions differently, a common practice in semi-supervised methods. To evaluate the effectiveness of the proposed approach, we conduct exhaustive experiments on five splits commonly used by sparsely annotated approaches on the PASCAL-VOC and COCO datasets and achieve state-of-the-art performance. In addition to this, we show that our approach achieves competitive performance on standard semi-supervised setups demonstrating the strength and broad applicability of our approach.
Self-Denoising Neural Networks for Few Shot Learning
Oct 26, 2021
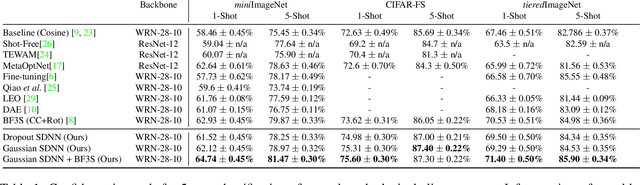
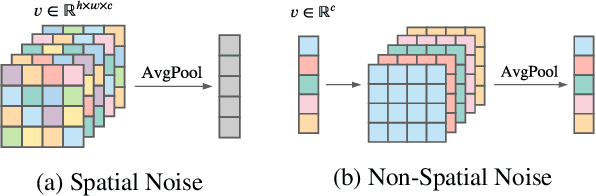

In this paper, we introduce a new architecture for few shot learning, the task of teaching a neural network from as few as one or five labeled examples. Inspired by the theoretical results of Alaine et al that Denoising Autoencoders refine features to lie closer to the true data manifold, we present a new training scheme that adds noise at multiple stages of an existing neural architecture while simultaneously learning to be robust to this added noise. This architecture, which we call a Self-Denoising Neural Network (SDNN), can be applied easily to most modern convolutional neural architectures, and can be used as a supplement to many existing few-shot learning techniques. We empirically show that SDNNs out-perform previous state-of-the-art methods for few shot image recognition using the Wide-ResNet architecture on the \textit{mini}ImageNet, tiered-ImageNet, and CIFAR-FS few shot learning datasets. We also perform a series of ablation experiments to empirically justify the construction of the SDNN architecture. Finally, we show that SDNNs even improve few shot performance on the task of human action detection in video using experiments on the ActEV SDL Surprise Activities challenge.