 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsely Annotated Object Detection: A Region-based Semi-supervised Approach
Paper and Code
Jan 12, 2022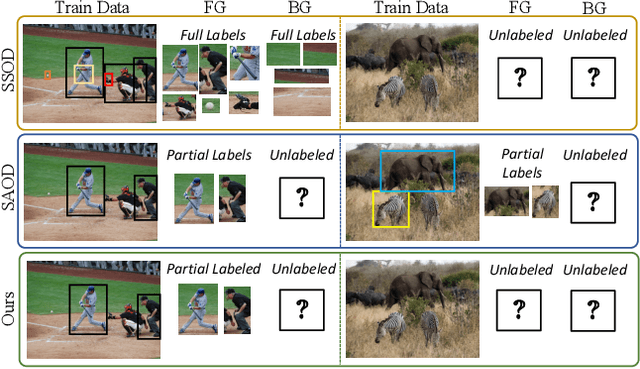
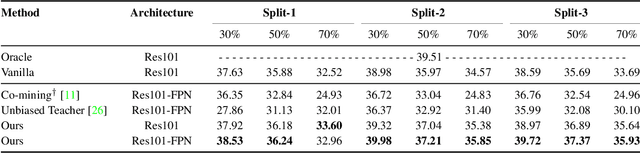


Research shows a noticeable drop in performance of object detectors when the training data has missing annotations, i.e. sparsely annotated data. Contemporary methods focus on proxies for missing ground-truth annotations either in the form of pseudo-labels or by re-weighing gradients for unlabeled boxes during training. In this work, we revisit the formulation of sparsely annotated object detection. We observe that sparsely annotated object detection can be considered a semi-supervised object detection problem at a region level. Building on this insight, we propose a region-based semi-supervised algorithm, that automatically identifies regions containing unlabeled foreground objects. Our algorithm then processes the labeled and un-labeled foreground regions differently, a common practice in semi-supervised methods. To evaluate the effectiveness of the proposed approach, we conduct exhaustive experiments on five splits commonly used by sparsely annotated approaches on the PASCAL-VOC and COCO datasets and achieve state-of-the-art performance. In addition to this, we show that our approach achieves competitive performance on standard semi-supervised setups demonstrating the strength and broad applicability of our approach.