 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
Nov 17, 2023We present Emu Video, a text-to-video generation model that factorizes the generation into two steps: first generating an image conditioned on the text, and then generating a video conditioned on the text and the generated image. We identify critical design decisions--adjusted noise schedules for diffusion, and multi-stage training--that enable us to directly generate high quality and high resolution videos, without requiring a deep cascade of models as in prior work. In human evaluations, our generated videos are strongly preferred in quality compared to all prior work--81% vs. Google's Imagen Video, 90% vs. Nvidia's PYOCO, and 96% vs. Meta's Make-A-Video. Our model outperforms commercial solutions such as RunwayML's Gen2 and Pika Labs. Finally, our factorizing approach naturally lends itself to animating images based on a user's text prompt, where our generations are preferred 96% over prior work.
Make-An-Animation: Large-Scale Text-conditional 3D Human Motion Generation
May 16, 2023Text-guided human motion generation has drawn significant interest because of its impactful applications spanning animation and robotics. Recently, application of diffusion models for motion generation has enabled improvements in the quality of generated motions. However, existing approaches are limited by their reliance on relatively small-scale motion capture data, leading to poor performance on more diverse, in-the-wild prompts. In this paper, we introduce Make-An-Animation, a text-conditioned human motion generation model which learns more diverse poses and prompts from large-scale image-text datasets, enabling significant improvement in performance over prior works. Make-An-Animation is trained in two stages. First, we train on a curated large-scale dataset of (text, static pseudo-pose) pairs extracted from image-text datasets. Second, we fine-tune on motion capture data, adding additional layers to model the temporal dimension. Unlike prior diffusion models for motion generation, Make-An-Animation uses a U-Net architecture similar to recent text-to-video generation models. Human evaluation of motion realism and alignment with input text shows that our model reaches state-of-the-art performance on text-to-motion generation.
Text-Conditional Contextualized Avatars For Zero-Shot Personalization
Apr 14, 2023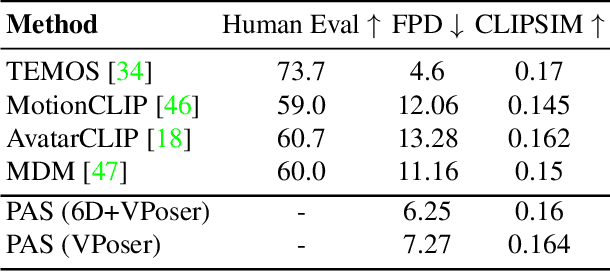
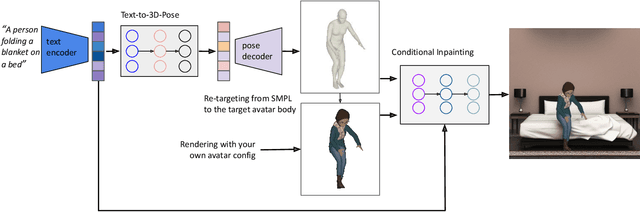
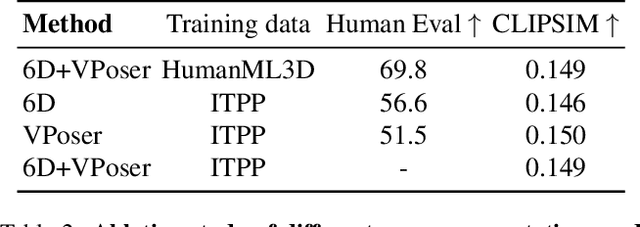
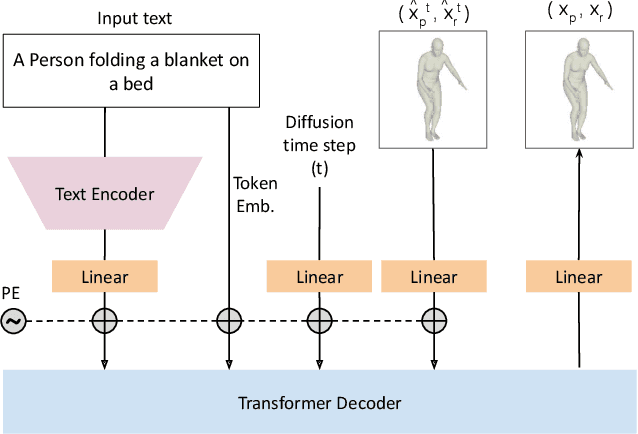
Recent large-scale text-to-image generation models have made significant improvements in the quality, realism, and diversity of the synthesized images and enable users to control the created content through language. However, the personalization aspect of these generative models is still challenging and under-explored. In this work, we propose a pipeline that enables personalization of image generation with avatars capturing a user's identity in a delightful way. Our pipeline is zero-shot, avatar texture and style agnostic, and does not require training on the avatar at all - it is scalable to millions of users who can generate a scene with their avatar. To render the avatar in a pose faithful to the given text prompt, we propose a novel text-to-3D pose diffusion model trained on a curated large-scale dataset of in-the-wild human poses improving the performance of the SOTA text-to-motion models significantly. We show, for the first time, how to leverage large-scale image datasets to learn human 3D pose parameters and overcome the limitations of motion capture datasets.