 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Jan 26, 2026Knowledge distillation improves large language model (LLM) reasoning by compressing the knowledge of a teacher LLM to train smaller LLMs. On-policy distillation advances this approach by having the student sample its own trajectories while a teacher LLM provides dense token-level supervision, addressing the distribution mismatch between training and inference in off-policy distillation methods. However, on-policy distillation typically requires a separate, often larger, teacher LLM and does not explicitly leverage ground-truth solutions available in reasoning datasets. Inspired by the intuition that a sufficiently capable LLM can rationalize external privileged reasoning traces and teach its weaker self (i.e., the version without access to privileged information), we introduce On-Policy Self-Distillation (OPSD), a framework where a single model acts as both teacher and student by conditioning on different contexts. The teacher policy conditions on privileged information (e.g., verified reasoning traces) while the student policy sees only the question; training minimizes the per-token divergence between these distributions over the student's own rollouts. We demonstrate the efficacy of our method on multiple mathematical reasoning benchmarks, achieving 4-8x token efficiency compared to reinforcement learning methods such as GRPO and superior performance over off-policy distillation methods.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
TLDR: Token-Level Detective Reward Model for Large Vision Language Models
Oct 07, 2024



Although reward models have been successful in improving multimodal large language models, the reward models themselves remain brutal and contain minimal information. Notably, existing reward models only mimic human annotations by assigning only one binary feedback to any text, no matter how long the text is. In the realm of multimodal language models, where models are required to process both images and texts, a naive reward model may learn implicit biases toward texts and become less grounded in images. In this paper, we propose a $\textbf{T}$oken-$\textbf{L}$evel $\textbf{D}$etective $\textbf{R}$eward Model ($\textbf{TLDR}$) to provide fine-grained annotations to each text token. We first introduce a perturbation-based method to generate synthetic hard negatives and their token-level labels to train TLDR models. Then we show the rich usefulness of TLDR models both in assisting off-the-shelf models to self-correct their generations, and in serving as a hallucination evaluation tool. Finally, we show that TLDR models can significantly speed up human annotation by 3 times to acquire a broader range of high-quality vision language data.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
SceneTextGen: Layout-Agnostic Scene Text Image Synthesis with Diffusion Models
Jun 03, 2024



While diffusion models have significantly advanced the quality of image generation, their capability to accurately and coherently render text within these images remains a substantial challenge. Conventional diffusion-based methods for scene text generation are typically limited by their reliance on an intermediate layout output. This dependency often results in a constrained diversity of text styles and fonts, an inherent limitation stemming from the deterministic nature of the layout generation phase. To address these challenges, this paper introduces SceneTextGen, a novel diffusion-based model specifically designed to circumvent the need for a predefined layout stage. By doing so, SceneTextGen facilitates a more natural and varied representation of text. The novelty of SceneTextGen lies in its integration of three key components: a character-level encoder for capturing detailed typographic properties, coupled with a character-level instance segmentation model and a word-level spotting model to address the issues of unwanted text generation and minor character inaccuracies. We validate the performance of our method by demonstrating improved character recognition rates on generated images across different public visual text datasets in comparison to both standard diffusion based methods and text specific methods.
Animated Stickers: Bringing Stickers to Life with Video Diffusion
Feb 08, 2024



We introduce animated stickers, a video diffusion model which generates an animation conditioned on a text prompt and static sticker image. Our model is built on top of the state-of-the-art Emu text-to-image model, with the addition of temporal layers to model motion. Due to the domain gap, i.e. differences in visual and motion style, a model which performed well on generating natural videos can no longer generate vivid videos when applied to stickers. To bridge this gap, we employ a two-stage finetuning pipeline: first with weakly in-domain data, followed by human-in-the-loop (HITL) strategy which we term ensemble-of-teachers. It distills the best qualities of multiple teachers into a smaller student model. We show that this strategy allows us to specifically target improvements to motion quality while maintaining the style from the static image. With inference optimizations, our model is able to generate an eight-frame video with high-quality, interesting, and relevant motion in under one second.
LEGO: Learning EGOcentric Action Frame Generation via Visual Instruction Tuning
Dec 06, 2023

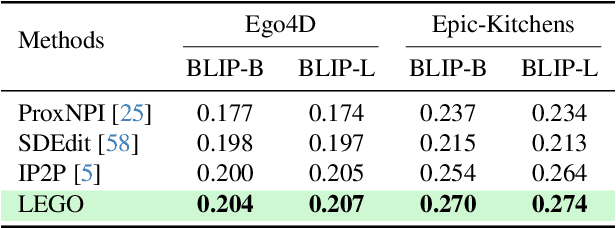

Generating instructional images of human daily actions from an egocentric viewpoint serves a key step towards efficient skill transfer. In this paper, we introduce a novel problem -- egocentric action frame generation. The goal is to synthesize the action frame conditioning on the user prompt question and an input egocentric image that captures user's environment. Notably, existing egocentric datasets lack the detailed annotations that describe the execution of actions. Additionally, the diffusion-based image manipulation models fail to control the state change of an action within the corresponding egocentric image pixel space. To this end, we finetune a visual large language model (VLLM) via visual instruction tuning for curating the enriched action descriptions to address our proposed problem. Moreover, we propose to Learn EGOcentric (LEGO) action frame generation using image and text embeddings from VLLM as additional conditioning. We validate our proposed model on two egocentric datasets -- Ego4D and Epic-Kitchens. Our experiments show prominent improvement over prior image manipulation models in both quantitative and qualitative evaluation. We also conduct detailed ablation studies and analysis to provide insights on our method.
DISGO: Automatic End-to-End Evaluation for Scene Text OCR
Aug 25, 2023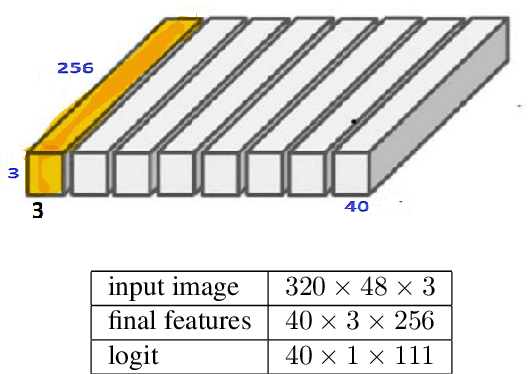


This paper discusses the challenges of optical character recognition (OCR) on natural scenes, which is harder than OCR on documents due to the wild content and various image backgrounds. We propose to uniformly use word error rates (WER) as a new measurement for evaluating scene-text OCR, both end-to-end (e2e) performance and individual system component performances. Particularly for the e2e metric, we name it DISGO WER as it considers Deletion, Insertion, Substitution, and Grouping/Ordering errors. Finally we propose to utilize the concept of super blocks to automatically compute BLEU scores for e2e OCR machine translation. The small SCUT public test set is used to demonstrate WER performance by a modularized OCR system.
Text-Conditional Contextualized Avatars For Zero-Shot Personalization
Apr 14, 2023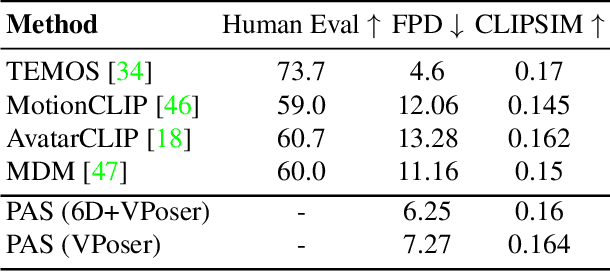
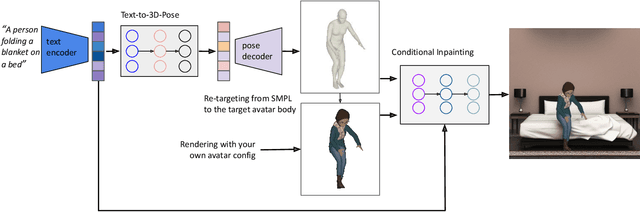
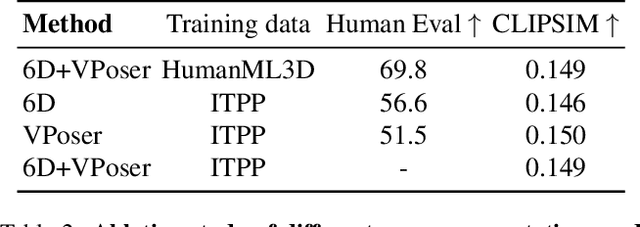
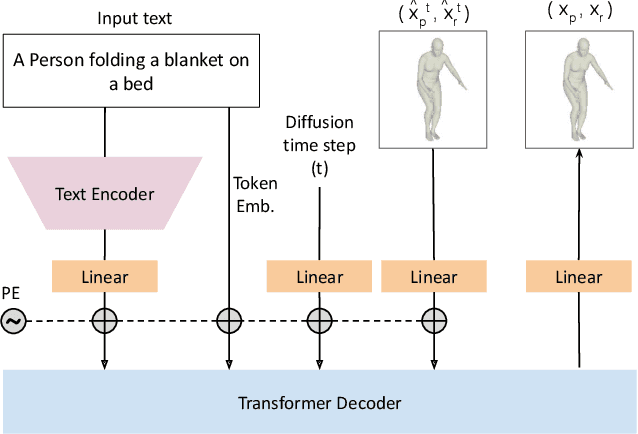
Recent large-scale text-to-image generation models have made significant improvements in the quality, realism, and diversity of the synthesized images and enable users to control the created content through language. However, the personalization aspect of these generative models is still challenging and under-explored. In this work, we propose a pipeline that enables personalization of image generation with avatars capturing a user's identity in a delightful way. Our pipeline is zero-shot, avatar texture and style agnostic, and does not require training on the avatar at all - it is scalable to millions of users who can generate a scene with their avatar. To render the avatar in a pose faithful to the given text prompt, we propose a novel text-to-3D pose diffusion model trained on a curated large-scale dataset of in-the-wild human poses improving the performance of the SOTA text-to-motion models significantly. We show, for the first time, how to leverage large-scale image datasets to learn human 3D pose parameters and overcome the limitations of motion capture datasets.