 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Equivalent Contrastive Learning for Radio Signal Recognition
Apr 13, 2026Robust radio signal recognition is fundamental to spectrum management, electromagnetic space security, and intelligent wireless applications, yet existing deep-learning methods rely heavily on large labeled datasets and struggle to capture the multi-domain characteristics inherent in real-world signals. To address these limitations, we propose an unsupervised equivalent contrastive learning method that leverages four information-lossless equivalent transformations, spanning the time, instantaneous, frequency, and time-frequency domains, to construct multi-view and semantically consistent representations of each signal. An equivalent contrastive learning strategy then aligns these complementary views to learn discriminative and transferable embeddings without requiring labeled data. Once pre-training is completed, the resulting model can be directly fine-tuned on downstream tasks using only raw signal samples, without reapplying any equivalent transformations, which reduces computational overhead and simplifies deployment. Extensive experiments on four public datasets demonstrate that the proposed method consistently outperforms state-of-the-art contrastive baselines under linear evaluation, few-shot semi-supervised learning, and cross-domain transfer settings. Notably, the learned representations yield substantial gains in few-shot regimes and challenging channel conditions, confirming the effectiveness of multi-domain equivalent modeling in enhancing robustness and generalization. This work establishes a principled pathway for exploiting massive unlabeled radio data and provides a foundation for future self-supervised learning frameworks in wireless systems.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
T-ADD: Enhancing DOA Estimation Robustness Against Adversarial Attacks
Dec 11, 2025Deep learning has achieved remarkable success in direction-of-arrival (DOA) estimation. However, recent studies have shown that adversarial perturbations can severely compromise the performance of such models. To address this vulnerability, we propose Transformer-based Adversarial Defense for DOA estimation (T-ADD), a transformer-based defense method designed to counter adversarial attacks. To achieve a balance between robustness and estimation accuracy, we formulate the adversarial defense as a joint reconstruction task and introduce a tailored joint loss function. Experimental results demonstrate that, compared with three state-of-the-art adversarial defense methods, the proposed T-ADD significantly mitigates the adverse effects of widely used adversarial attacks, leading to notable improvements in the adversarial robustness of the DOA model.
WK-Pnet: FM-Based Positioning via Wavelet Packet Decomposition and Knowledge Distillation
Apr 10, 2025



Accurate and efficient positioning in complex environments is critical for applications where traditional satellite-based systems face limitations, such as indoors or urban canyons. This paper introduces WK-Pnet, an FM-based indoor positioning framework that combines wavelet packet decomposition (WPD) and knowledge distillation. WK-Pnet leverages WPD to extract rich time-frequency features from FM signals, which are then processed by a deep learning model for precise position estimation. To address computational demands, we employ knowledge distillation, transferring insights from a high-capacity model to a streamlined student model, achieving substantial reductions in complexity without sacrificing accuracy. Experimental results across diverse environments validate WK-Pnet's superior positioning accuracy and lower computational requirements, making it a viable solution for positioning in real-time resource-constraint applications.
Deep Learning-Based Wideband Spectrum Sensing with Dual-Representation Inputs and Subband Shuffling Augmentation
Apr 10, 2025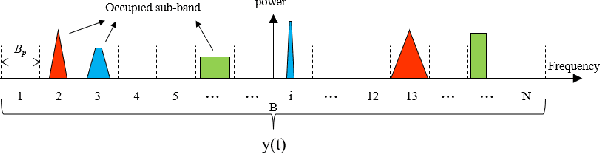
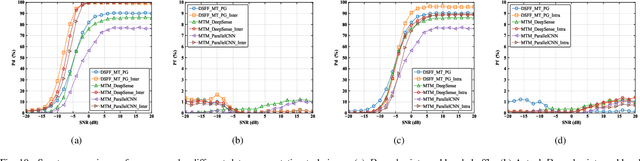
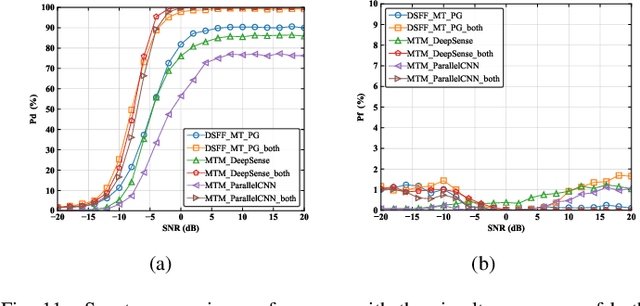
The widespread adoption of mobile communication technology has led to a severe shortage of spectrum resources, driving the development of cognitive radio technologies aimed at improving spectrum utilization, with spectrum sensing being the key enabler. This paper presents a novel deep learning-based wideband spectrum sensing framework that leverages multi-taper power spectral inputs to achieve high-precision and sample-efficient sensing. To enhance sensing accuracy, we incorporate a feature fusion strategy that combines multiple power spectrum representations. To tackle the challenge of limited sample sizes, we propose two data augmentation techniques designed to expand the training set and improve the network's detection probability. Comprehensive simulation results demonstrate that our method outperforms existing approaches, particularly in low signal-to-noise ratio conditions, achieving higher detection probabilities and lower false alarm rates. The method also exhibits strong robustness across various scenarios, highlighting its significant potential for practical applications in wireless communication systems.
DS-Pnet: FM-Based Positioning via Downsampling
Apr 10, 2025



In this paper we present DS-Pnet, a novel framework for FM signal-based positioning that addresses the challenges of high computational complexity and limited deployment in resource-constrained environments. Two downsampling methods-IQ signal downsampling and time-frequency representation downsampling-are proposed to reduce data dimensionality while preserving critical positioning features. By integrating with the lightweight MobileViT-XS neural network, the framework achieves high positioning accuracy with significantly reduced computational demands. Experiments on real-world FM signal datasets demonstrate that DS-Pnet achieves superior performance in both indoor and outdoor scenarios, with space and time complexity reductions of approximately 87% and 99.5%, respectively, compared to an existing method, FM-Pnet. Despite the high compression, DS-Pnet maintains robust positioning accuracy, offering an optimal balance between efficiency and precision.
MoCha: Towards Movie-Grade Talking Character Synthesis
Mar 30, 2025
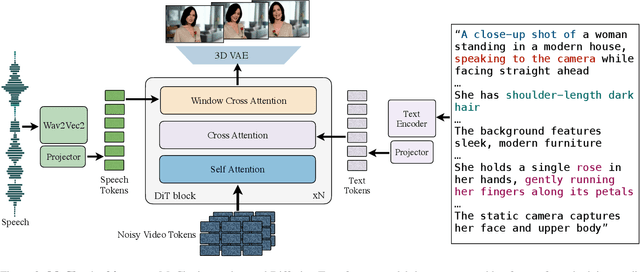

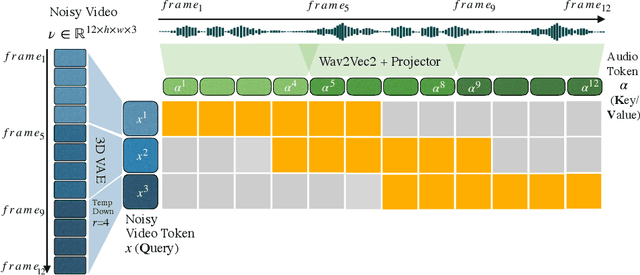
Recent advancements in video generation have achieved impressive motion realism, yet they often overlook character-driven storytelling, a crucial task for automated film, animation generation. We introduce Talking Characters, a more realistic task to generate talking character animations directly from speech and text. Unlike talking head, Talking Characters aims at generating the full portrait of one or more characters beyond the facial region. In this paper, we propose MoCha, the first of its kind to generate talking characters. To ensure precise synchronization between video and speech, we propose a speech-video window attention mechanism that effectively aligns speech and video tokens. To address the scarcity of large-scale speech-labeled video datasets, we introduce a joint training strategy that leverages both speech-labeled and text-labeled video data, significantly improving generalization across diverse character actions. We also design structured prompt templates with character tags, enabling, for the first time, multi-character conversation with turn-based dialogue-allowing AI-generated characters to engage in context-aware conversations with cinematic coherence. Extensive qualitative and quantitative evaluations, including human preference studies and benchmark comparisons, demonstrate that MoCha sets a new standard for AI-generated cinematic storytelling, achieving superior realism, expressiveness, controllability and generalization.
Query-Efficient Adversarial Attack Against Vertical Federated Graph Learning
Nov 05, 2024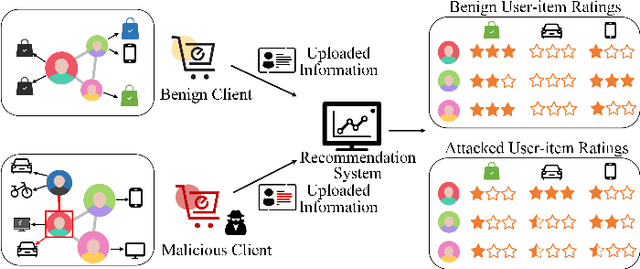
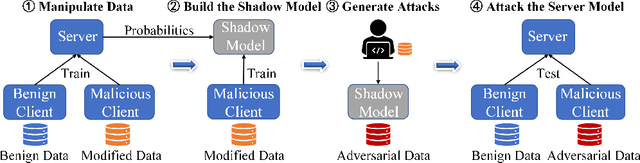
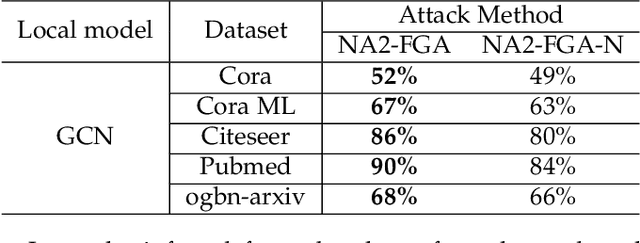
Graph neural network (GNN) has captured wide attention due to its capability of graph representation learning for graph-structured data. However, the distributed data silos limit the performance of GNN. Vertical federated learning (VFL), an emerging technique to process distributed data, successfully makes GNN possible to handle the distributed graph-structured data. Despite the prosperous development of vertical federated graph learning (VFGL), the robustness of VFGL against the adversarial attack has not been explored yet. Although numerous adversarial attacks against centralized GNNs are proposed, their attack performance is challenged in the VFGL scenario. To the best of our knowledge, this is the first work to explore the adversarial attack against VFGL. A query-efficient hybrid adversarial attack framework is proposed to significantly improve the centralized adversarial attacks against VFGL, denoted as NA2, short for Neuron-based Adversarial Attack. Specifically, a malicious client manipulates its local training data to improve its contribution in a stealthy fashion. Then a shadow model is established based on the manipulated data to simulate the behavior of the server model in VFGL. As a result, the shadow model can improve the attack success rate of various centralized attacks with a few queries. Extensive experiments on five real-world benchmarks demonstrate that NA2 improves the performance of the centralized adversarial attacks against VFGL, achieving state-of-the-art performance even under potential adaptive defense where the defender knows the attack method. Additionally, we provide interpretable experiments of the effectiveness of NA2 via sensitive neurons identification and visualization of t-SNE.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Animated Stickers: Bringing Stickers to Life with Video Diffusion
Feb 08, 2024



We introduce animated stickers, a video diffusion model which generates an animation conditioned on a text prompt and static sticker image. Our model is built on top of the state-of-the-art Emu text-to-image model, with the addition of temporal layers to model motion. Due to the domain gap, i.e. differences in visual and motion style, a model which performed well on generating natural videos can no longer generate vivid videos when applied to stickers. To bridge this gap, we employ a two-stage finetuning pipeline: first with weakly in-domain data, followed by human-in-the-loop (HITL) strategy which we term ensemble-of-teachers. It distills the best qualities of multiple teachers into a smaller student model. We show that this strategy allows us to specifically target improvements to motion quality while maintaining the style from the static image. With inference optimizations, our model is able to generate an eight-frame video with high-quality, interesting, and relevant motion in under one second.