 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarve to Perceive: Taming Lazy Perception in VLMs with Constrained Visual Bandwidth
May 18, 2026Vision-Language Models (VLMs) deployed as situated agents in high-resolution visual environments require active perception -- the ability to dynamically decide where to look through operations like zooming, cropping, and panning. However, current training paradigms produce models that mimic the surface form of such operations without functionally depending on their outputs, a phenomenon we term lazy perception. We trace this to a fundamental learning asymmetry: when coarse global views combined with language priors suffice for moderate accuracy, the model has no incentive to learn harder multi-step visual search. If a model can succeed without actively looking, it will never learn to look. This motivates Starve to Perceive, a training paradigm that constrains visual bandwidth -- restricting each observation to a tight token budget so that no single view suffices for task completion, making active perception the only viable strategy. Despite requiring no auxiliary losses, reward shaping, or architectural changes -- serving as a minimal, plug-in modification to standard post-training pipelines -- models trained under perceptual starvation achieve substantial gains of 5% average relative improvement across diverse benchmarks.
RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time
Apr 14, 2026Most reward models for visual generation reduce rich human judgments to a single unexplained score, discarding the reasoning that underlies preference. We show that teaching reward models to produce explicit, multi-dimensional critiques before scoring transforms them from passive evaluators into active optimization tools, improving generators in two complementary ways: at training time, structured rationales provide interpretable, fine-grained rewards for reinforcement learning; at test time, a Generate-Critique-Refine loop turns critiques into targeted prompt revisions that improve outputs without any parameter updates. To train such a reward model without costly rationale annotations, we introduce Preference-Anchored Rationalization (PARROT), a principled framework that recovers high-quality rationales from readily available preference data through anchored generation, consistency filtering, and distillation. The resulting model, RationalRewards (8B), achieves state-of-the-art preference prediction among open-source reward models, competitive with Gemini-2.5-Pro, while using 10-20x less training data than comparable baselines. As an RL reward, it consistently improves text-to-image and image-editing generators beyond scalar alternatives. Most strikingly, its test-time critique-and-refine loop matches or exceeds RL-based fine-tuning on several benchmarks, suggesting that structured reasoning can unlock latent capabilities in existing generators that suboptimal prompts fail to elicit.
Context Forcing: Consistent Autoregressive Video Generation with Long Context
Feb 05, 2026Recent approaches to real-time long video generation typically employ streaming tuning strategies, attempting to train a long-context student using a short-context (memoryless) teacher. In these frameworks, the student performs long rollouts but receives supervision from a teacher limited to short 5-second windows. This structural discrepancy creates a critical \textbf{student-teacher mismatch}: the teacher's inability to access long-term history prevents it from guiding the student on global temporal dependencies, effectively capping the student's context length. To resolve this, we propose \textbf{Context Forcing}, a novel framework that trains a long-context student via a long-context teacher. By ensuring the teacher is aware of the full generation history, we eliminate the supervision mismatch, enabling the robust training of models capable of long-term consistency. To make this computationally feasible for extreme durations (e.g., 2 minutes), we introduce a context management system that transforms the linearly growing context into a \textbf{Slow-Fast Memory} architecture, significantly reducing visual redundancy. Extensive results demonstrate that our method enables effective context lengths exceeding 20 seconds -- 2 to 10 times longer than state-of-the-art methods like LongLive and Infinite-RoPE. By leveraging this extended context, Context Forcing preserves superior consistency across long durations, surpassing state-of-the-art baselines on various long video evaluation metrics.
Visual-Aware CoT: Achieving High-Fidelity Visual Consistency in Unified Models
Dec 22, 2025Recently, the introduction of Chain-of-Thought (CoT) has largely improved the generation ability of unified models. However, it is observed that the current thinking process during generation mainly focuses on the text consistency with the text prompt, ignoring the \textbf{visual context consistency} with the visual reference images during the multi-modal generation, e.g., multi-reference generation. The lack of such consistency results in the failure in maintaining key visual features (like human ID, object attribute, style). To this end, we integrate the visual context consistency into the reasoning of unified models, explicitly motivating the model to sustain such consistency by 1) Adaptive Visual Planning: generating structured visual check list to figure out the visual element of needed consistency keeping, and 2) Iterative Visual Correction: performing self-reflection with the guidance of check lists and refining the generated result in an iterative manner. To achieve this, we use supervised finetuning to teach the model how to plan the visual checking, conduct self-reflection and self-refinement, and use flow-GRPO to further enhance the visual consistency through a customized visual checking reward. The experiments show that our method outperforms both zero-shot unified models and those with text CoTs in multi-modal generation, demonstrating higher visual context consistency.
UFVideo: Towards Unified Fine-Grained Video Cooperative Understanding with Large Language Models
Dec 12, 2025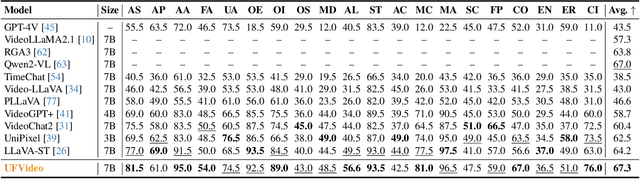
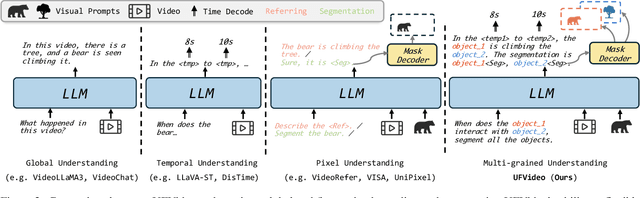
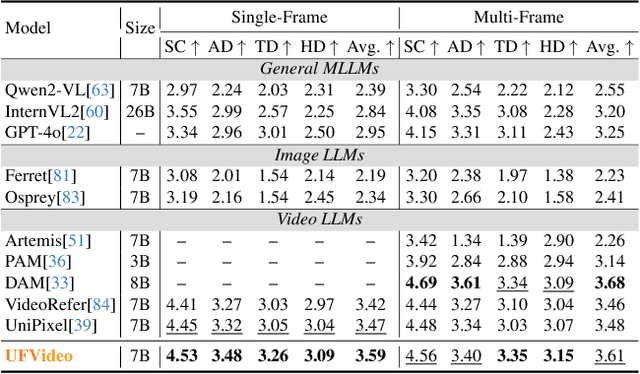
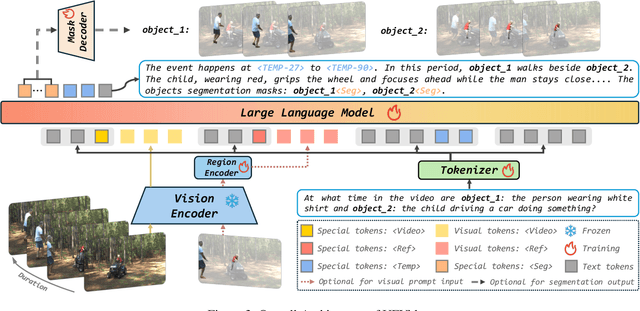
With the advancement of multi-modal Large Language Models (LLMs), Video LLMs have been further developed to perform on holistic and specialized video understanding. However, existing works are limited to specialized video understanding tasks, failing to achieve a comprehensive and multi-grained video perception. To bridge this gap, we introduce UFVideo, the first Video LLM with unified multi-grained cooperative understanding capabilities. Specifically, we design unified visual-language guided alignment to flexibly handle video understanding across global, pixel and temporal scales within a single model. UFVideo dynamically encodes the visual and text inputs of different tasks and generates the textual response, temporal localization, or grounded mask. Additionally, to evaluate challenging multi-grained video understanding tasks, we construct the UFVideo-Bench consisting of three distinct collaborative tasks within the scales, which demonstrates UFVideo's flexibility and advantages over GPT-4o. Furthermore, we validate the effectiveness of our model across 9 public benchmarks covering various common video understanding tasks, providing valuable insights for future Video LLMs.
MoCha: Towards Movie-Grade Talking Character Synthesis
Mar 30, 2025
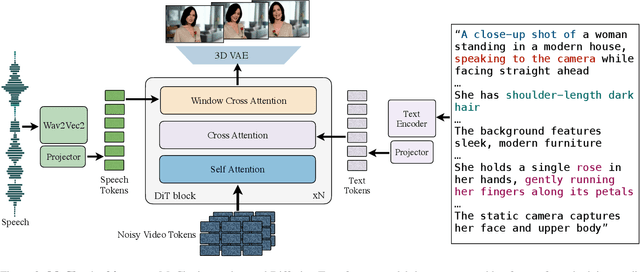

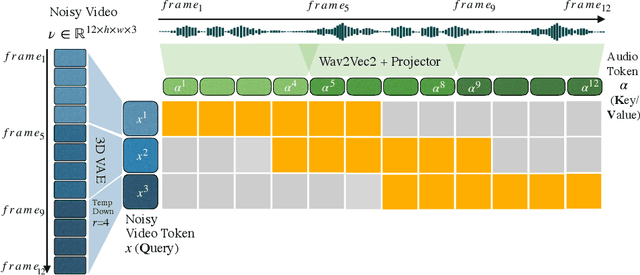
Recent advancements in video generation have achieved impressive motion realism, yet they often overlook character-driven storytelling, a crucial task for automated film, animation generation. We introduce Talking Characters, a more realistic task to generate talking character animations directly from speech and text. Unlike talking head, Talking Characters aims at generating the full portrait of one or more characters beyond the facial region. In this paper, we propose MoCha, the first of its kind to generate talking characters. To ensure precise synchronization between video and speech, we propose a speech-video window attention mechanism that effectively aligns speech and video tokens. To address the scarcity of large-scale speech-labeled video datasets, we introduce a joint training strategy that leverages both speech-labeled and text-labeled video data, significantly improving generalization across diverse character actions. We also design structured prompt templates with character tags, enabling, for the first time, multi-character conversation with turn-based dialogue-allowing AI-generated characters to engage in context-aware conversations with cinematic coherence. Extensive qualitative and quantitative evaluations, including human preference studies and benchmark comparisons, demonstrate that MoCha sets a new standard for AI-generated cinematic storytelling, achieving superior realism, expressiveness, controllability and generalization.
Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers
Mar 14, 2025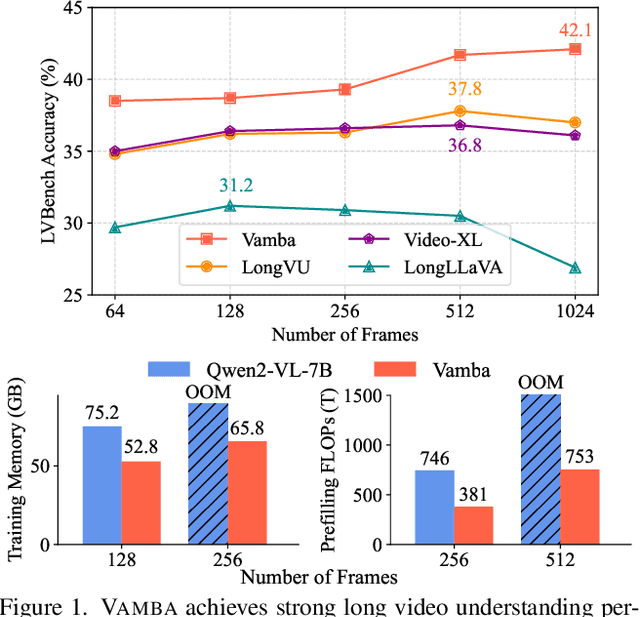
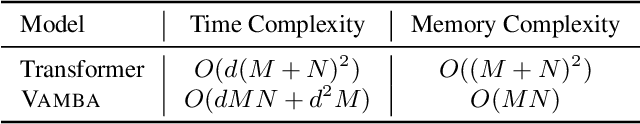
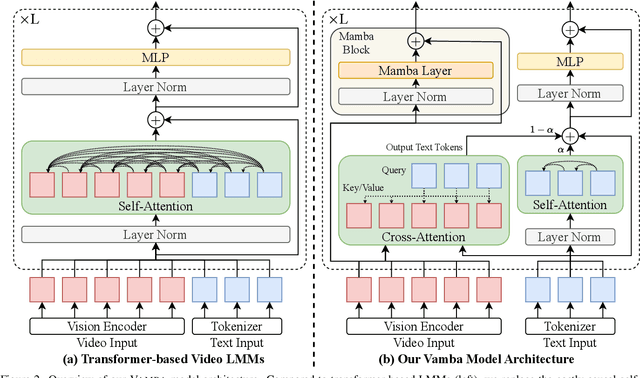
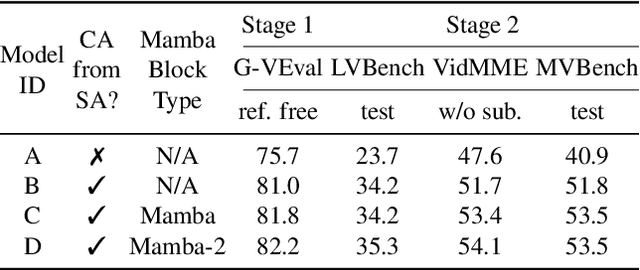
State-of-the-art transformer-based large multimodal models (LMMs) struggle to handle hour-long video inputs due to the quadratic complexity of the causal self-attention operations, leading to high computational costs during training and inference. Existing token compression-based methods reduce the number of video tokens but often incur information loss and remain inefficient for extremely long sequences. In this paper, we explore an orthogonal direction to build a hybrid Mamba-Transformer model (VAMBA) that employs Mamba-2 blocks to encode video tokens with linear complexity. Without any token reduction, VAMBA can encode more than 1024 frames (640$\times$360) on a single GPU, while transformer-based models can only encode 256 frames. On long video input, VAMBA achieves at least 50% reduction in GPU memory usage during training and inference, and nearly doubles the speed per training step compared to transformer-based LMMs. Our experimental results demonstrate that VAMBA improves accuracy by 4.3% on the challenging hour-long video understanding benchmark LVBench over prior efficient video LMMs, and maintains strong performance on a broad spectrum of long and short video understanding tasks.
A Survey on Data-Centric AI: Tabular Learning from Reinforcement Learning and Generative AI Perspective
Feb 12, 2025


Tabular data is one of the most widely used data formats across various domains such as bioinformatics, healthcare, and marketing. As artificial intelligence moves towards a data-centric perspective, improving data quality is essential for enhancing model performance in tabular data-driven applications. This survey focuses on data-driven tabular data optimization, specifically exploring reinforcement learning (RL) and generative approaches for feature selection and feature generation as fundamental techniques for refining data spaces. Feature selection aims to identify and retain the most informative attributes, while feature generation constructs new features to better capture complex data patterns. We systematically review existing generative methods for tabular data engineering, analyzing their latest advancements, real-world applications, and respective strengths and limitations. This survey emphasizes how RL-based and generative techniques contribute to the automation and intelligence of feature engineering. Finally, we summarize the existing challenges and discuss future research directions, aiming to provide insights that drive continued innovation in this field.
InstructSeg: Unifying Instructed Visual Segmentation with Multi-modal Large Language Models
Dec 18, 2024Boosted by Multi-modal Large Language Models (MLLMs), text-guided universal segmentation models for the image and video domains have made rapid progress recently. However, these methods are often developed separately for specific domains, overlooking the similarities in task settings and solutions across these two areas. In this paper, we define the union of referring segmentation and reasoning segmentation at both the image and video levels as Instructed Visual Segmentation (IVS). Correspondingly, we propose InstructSeg, an end-to-end segmentation pipeline equipped with MLLMs for IVS. Specifically, we employ an object-aware video perceiver to extract temporal and object information from reference frames, facilitating comprehensive video understanding. Additionally, we introduce vision-guided multi-granularity text fusion to better integrate global and detailed text information with fine-grained visual guidance. By leveraging multi-task and end-to-end training, InstructSeg demonstrates superior performance across diverse image and video segmentation tasks, surpassing both segmentation specialists and MLLM-based methods with a single model. Our code is available at https://github.com/congvvc/InstructSeg.
VISTA: Enhancing Long-Duration and High-Resolution Video Understanding by Video Spatiotemporal Augmentation
Dec 01, 2024



Current large multimodal models (LMMs) face significant challenges in processing and comprehending long-duration or high-resolution videos, which is mainly due to the lack of high-quality datasets. To address this issue from a data-centric perspective, we propose VISTA, a simple yet effective Video Spatiotemporal Augmentation framework that synthesizes long-duration and high-resolution video instruction-following pairs from existing video-caption datasets. VISTA spatially and temporally combines videos to create new synthetic videos with extended durations and enhanced resolutions, and subsequently produces question-answer pairs pertaining to these newly synthesized videos. Based on this paradigm, we develop seven video augmentation methods and curate VISTA-400K, a video instruction-following dataset aimed at enhancing long-duration and high-resolution video understanding. Finetuning various video LMMs on our data resulted in an average improvement of 3.3% across four challenging benchmarks for long-video understanding. Furthermore, we introduce the first comprehensive high-resolution video understanding benchmark HRVideoBench, on which our finetuned models achieve a 6.5% performance gain. These results highlight the effectiveness of our framework.