 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs
May 26, 2025
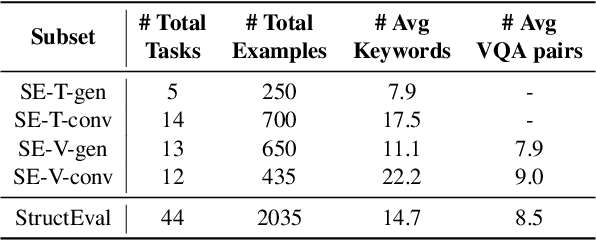

As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs' capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: 1) generation tasks, producing structured output from natural language prompts, and 2) conversion tasks, translating between structured formats. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps, even state-of-the-art models like o1-mini achieve only 75.58 average score, with open-source alternatives lagging approximately 10 points behind. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.
QuickVideo: Real-Time Long Video Understanding with System Algorithm Co-Design
May 22, 2025



Long-video understanding has emerged as a crucial capability in real-world applications such as video surveillance, meeting summarization, educational lecture analysis, and sports broadcasting. However, it remains computationally prohibitive for VideoLLMs, primarily due to two bottlenecks: 1) sequential video decoding, the process of converting the raw bit stream to RGB frames can take up to a minute for hour-long video inputs, and 2) costly prefilling of up to several million tokens for LLM inference, resulting in high latency and memory use. To address these challenges, we propose QuickVideo, a system-algorithm co-design that substantially accelerates long-video understanding to support real-time downstream applications. It comprises three key innovations: QuickDecoder, a parallelized CPU-based video decoder that achieves 2-3 times speedup by splitting videos into keyframe-aligned intervals processed concurrently; QuickPrefill, a memory-efficient prefilling method using KV-cache pruning to support more frames with less GPU memory; and an overlapping scheme that overlaps CPU video decoding with GPU inference. Together, these components infernece time reduce by a minute on long video inputs, enabling scalable, high-quality video understanding even on limited hardware. Experiments show that QuickVideo generalizes across durations and sampling rates, making long video processing feasible in practice.
General-Reasoner: Advancing LLM Reasoning Across All Domains
May 21, 2025



Reinforcement learning (RL) has recently demonstrated strong potential in enhancing the reasoning capabilities of large language models (LLMs). Particularly, the "Zero" reinforcement learning introduced by Deepseek-R1-Zero, enables direct RL training of base LLMs without relying on an intermediate supervised fine-tuning stage. Despite these advancements, current works for LLM reasoning mainly focus on mathematical and coding domains, largely due to data abundance and the ease of answer verification. This limits the applicability and generalization of such models to broader domains, where questions often have diverse answer representations, and data is more scarce. In this paper, we propose General-Reasoner, a novel training paradigm designed to enhance LLM reasoning capabilities across diverse domains. Our key contributions include: (1) constructing a large-scale, high-quality dataset of questions with verifiable answers curated by web crawling, covering a wide range of disciplines; and (2) developing a generative model-based answer verifier, which replaces traditional rule-based verification with the capability of chain-of-thought and context-awareness. We train a series of models and evaluate them on a wide range of datasets covering wide domains like physics, chemistry, finance, electronics etc. Our comprehensive evaluation across these 12 benchmarks (e.g. MMLU-Pro, GPQA, SuperGPQA, TheoremQA, BBEH and MATH AMC) demonstrates that General-Reasoner outperforms existing baseline methods, achieving robust and generalizable reasoning performance while maintaining superior effectiveness in mathematical reasoning tasks.
ACECODER: Acing Coder RL via Automated Test-Case Synthesis
Feb 03, 2025Most progress in recent coder models has been driven by supervised fine-tuning (SFT), while the potential of reinforcement learning (RL) remains largely unexplored, primarily due to the lack of reliable reward data/model in the code domain. In this paper, we address this challenge by leveraging automated large-scale test-case synthesis to enhance code model training. Specifically, we design a pipeline that generates extensive (question, test-cases) pairs from existing code data. Using these test cases, we construct preference pairs based on pass rates over sampled programs to train reward models with Bradley-Terry loss. It shows an average of 10-point improvement for Llama-3.1-8B-Ins and 5-point improvement for Qwen2.5-Coder-7B-Ins through best-of-32 sampling, making the 7B model on par with 236B DeepSeek-V2.5. Furthermore, we conduct reinforcement learning with both reward models and test-case pass rewards, leading to consistent improvements across HumanEval, MBPP, BigCodeBench, and LiveCodeBench (V4). Notably, we follow the R1-style training to start from Qwen2.5-Coder-base directly and show that our RL training can improve model on HumanEval-plus by over 25\% and MBPP-plus by 6\% for merely 80 optimization steps. We believe our results highlight the huge potential of reinforcement learning in coder models.
MEGA-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks
Oct 14, 2024



We present MEGA-Bench, an evaluation suite that scales multimodal evaluation to over 500 real-world tasks, to address the highly heterogeneous daily use cases of end users. Our objective is to optimize for a set of high-quality data samples that cover a highly diverse and rich set of multimodal tasks, while enabling cost-effective and accurate model evaluation. In particular, we collected 505 realistic tasks encompassing over 8,000 samples from 16 expert annotators to extensively cover the multimodal task space. Instead of unifying these problems into standard multi-choice questions (like MMMU, MMBench, and MMT-Bench), we embrace a wide range of output formats like numbers, phrases, code, \LaTeX, coordinates, JSON, free-form, etc. To accommodate these formats, we developed over 40 metrics to evaluate these tasks. Unlike existing benchmarks, MEGA-Bench offers a fine-grained capability report across multiple dimensions (e.g., application, input type, output format, skill), allowing users to interact with and visualize model capabilities in depth. We evaluate a wide variety of frontier vision-language models on MEGA-Bench to understand their capabilities across these dimensions.
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation
Jun 24, 2024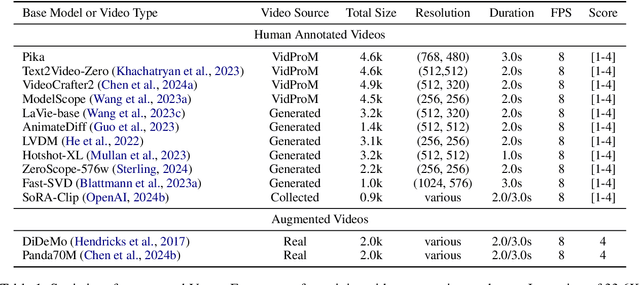

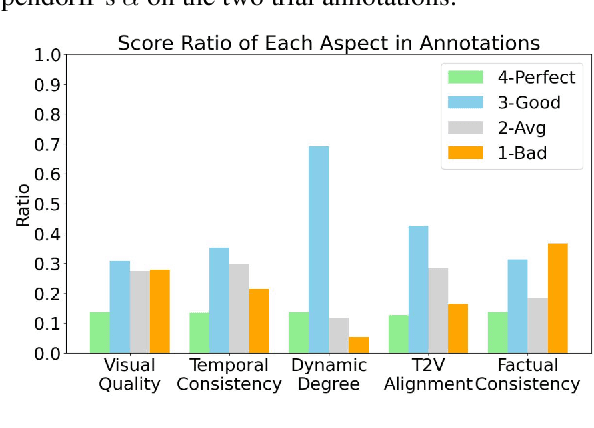

The recent years have witnessed great advances in video generation. However, the development of automatic video metrics is lagging significantly behind. None of the existing metric is able to provide reliable scores over generated videos. The main barrier is the lack of large-scale human-annotated dataset. In this paper, we release VideoFeedback, the first large-scale dataset containing human-provided multi-aspect score over 37.6K synthesized videos from 11 existing video generative models. We train VideoScore (initialized from Mantis) based on VideoFeedback to enable automatic video quality assessment. Experiments show that the Spearman correlation between VideoScore and humans can reach 77.1 on VideoFeedback-test, beating the prior best metrics by about 50 points. Further result on other held-out EvalCrafter, GenAI-Bench, and VBench show that VideoScore has consistently much higher correlation with human judges than other metrics. Due to these results, we believe VideoScore can serve as a great proxy for human raters to (1) rate different video models to track progress (2) simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.
WildVision: Evaluating Vision-Language Models in the Wild with Human Preferences
Jun 16, 2024Recent breakthroughs in vision-language models (VLMs) emphasize the necessity of benchmarking human preferences in real-world multimodal interactions. To address this gap, we launched WildVision-Arena (WV-Arena), an online platform that collects human preferences to evaluate VLMs. We curated WV-Bench by selecting 500 high-quality samples from 8,000 user submissions in WV-Arena. WV-Bench uses GPT-4 as the judge to compare each VLM with Claude-3-Sonnet, achieving a Spearman correlation of 0.94 with the WV-Arena Elo. This significantly outperforms other benchmarks like MMVet, MMMU, and MMStar. Our comprehensive analysis of 20K real-world interactions reveals important insights into the failure cases of top-performing VLMs. For example, we find that although GPT-4V surpasses many other models like Reka-Flash, Opus, and Yi-VL-Plus in simple visual recognition and reasoning tasks, it still faces challenges with subtle contextual cues, spatial reasoning, visual imagination, and expert domain knowledge. Additionally, current VLMs exhibit issues with hallucinations and safety when intentionally provoked. We are releasing our chat and feedback data to further advance research in the field of VLMs.
GenAI Arena: An Open Evaluation Platform for Generative Models
Jun 06, 2024Generative AI has made remarkable strides to revolutionize fields such as image and video generation. These advancements are driven by innovative algorithms, architecture, and data. However, the rapid proliferation of generative models has highlighted a critical gap: the absence of trustworthy evaluation metrics. Current automatic assessments such as FID, CLIP, FVD, etc often fail to capture the nuanced quality and user satisfaction associated with generative outputs. This paper proposes an open platform GenAI-Arena to evaluate different image and video generative models, where users can actively participate in evaluating these models. By leveraging collective user feedback and votes, GenAI-Arena aims to provide a more democratic and accurate measure of model performance. It covers three arenas for text-to-image generation, text-to-video generation, and image editing respectively. Currently, we cover a total of 27 open-source generative models. GenAI-Arena has been operating for four months, amassing over 6000 votes from the community. We describe our platform, analyze the data, and explain the statistical methods for ranking the models. To further promote the research in building model-based evaluation metrics, we release a cleaned version of our preference data for the three tasks, namely GenAI-Bench. We prompt the existing multi-modal models like Gemini, GPT-4o to mimic human voting. We compute the correlation between model voting with human voting to understand their judging abilities. Our results show existing multimodal models are still lagging in assessing the generated visual content, even the best model GPT-4o only achieves a Pearson correlation of 0.22 in the quality subscore, and behaves like random guessing in others.
MANTIS: Interleaved Multi-Image Instruction Tuning
May 02, 2024



The recent years have witnessed a great array of large multimodal models (LMMs) to effectively solve single-image vision language tasks. However, their abilities to solve multi-image visual language tasks is yet to be improved. The existing multi-image LMMs (e.g. OpenFlamingo, Emu, Idefics, etc) mostly gain their multi-image ability through pre-training on hundreds of millions of noisy interleaved image-text data from web, which is neither efficient nor effective. In this paper, we aim at building strong multi-image LMMs via instruction tuning with academic-level resources. Therefore, we meticulously construct Mantis-Instruct containing 721K instances from 14 multi-image datasets. We design Mantis-Instruct to cover different multi-image skills like co-reference, reasoning, comparing, temporal understanding. We combine Mantis-Instruct with several single-image visual-language datasets to train our model Mantis to handle any interleaved image-text inputs. We evaluate the trained Mantis on five multi-image benchmarks and eight single-image benchmarks. Though only requiring academic-level resources (i.e. 36 hours on 16xA100-40G), Mantis-8B can achieve state-of-the-art performance on all the multi-image benchmarks and beats the existing best multi-image LMM Idefics2-8B by an average of 9 absolute points. We observe that Mantis performs equivalently well on the held-in and held-out evaluation benchmarks. We further evaluate Mantis on single-image benchmarks and demonstrate that Mantis can maintain a strong single-image performance on par with CogVLM and Emu2. Our results are particularly encouraging as it shows that low-cost instruction tuning is indeed much more effective than intensive pre-training in terms of building multi-image LMMs.
VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation
Dec 22, 2023



In the rapidly advancing field of conditional image generation research, challenges such as limited explainability lie in effectively evaluating the performance and capabilities of various models. This paper introduces VIESCORE, a Visual Instruction-guided Explainable metric for evaluating any conditional image generation tasks. VIESCORE leverages general knowledge from Multimodal Large Language Models (MLLMs) as the backbone and does not require training or fine-tuning. We evaluate VIESCORE on seven prominent tasks in conditional image tasks and found: (1) VIESCORE (GPT4-v) achieves a high Spearman correlation of 0.3 with human evaluations, while the human-to-human correlation is 0.45. (2) VIESCORE (with open-source MLLM) is significantly weaker than GPT-4v in evaluating synthetic images. (3) VIESCORE achieves a correlation on par with human ratings in the generation tasks but struggles in editing tasks. With these results, we believe VIESCORE shows its great potential to replace human judges in evaluating image synthesis tasks.