 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOCATEdit: Graph Laplacian Optimized Cross Attention for Localized Text-Guided Image Editing
Mar 27, 2025Text-guided image editing aims to modify specific regions of an image according to natural language instructions while maintaining the general structure and the background fidelity. Existing methods utilize masks derived from cross-attention maps generated from diffusion models to identify the target regions for modification. However, since cross-attention mechanisms focus on semantic relevance, they struggle to maintain the image integrity. As a result, these methods often lack spatial consistency, leading to editing artifacts and distortions. In this work, we address these limitations and introduce LOCATEdit, which enhances cross-attention maps through a graph-based approach utilizing self-attention-derived patch relationships to maintain smooth, coherent attention across image regions, ensuring that alterations are limited to the designated items while retaining the surrounding structure. \method consistently and substantially outperforms existing baselines on PIE-Bench, demonstrating its state-of-the-art performance and effectiveness on various editing tasks. Code can be found on https://github.com/LOCATEdit/LOCATEdit/
VideoAgent: Self-Improving Video Generation
Oct 15, 2024



Video generation has been used to generate visual plans for controlling robotic systems. Given an image observation and a language instruction, previous work has generated video plans which are then converted to robot controls to be executed. However, a major bottleneck in leveraging video generation for control lies in the quality of the generated videos, which often suffer from hallucinatory content and unrealistic physics, resulting in low task success when control actions are extracted from the generated videos. While scaling up dataset and model size provides a partial solution, integrating external feedback is both natural and essential for grounding video generation in the real world. With this observation, we propose VideoAgent for self-improving generated video plans based on external feedback. Instead of directly executing the generated video plan, VideoAgent first refines the generated video plans using a novel procedure which we call self-conditioning consistency, utilizing feedback from a pretrained vision-language model (VLM). As the refined video plan is being executed, VideoAgent collects additional data from the environment to further improve video plan generation. Experiments in simulated robotic manipulation from MetaWorld and iTHOR show that VideoAgent drastically reduces hallucination, thereby boosting success rate of downstream manipulation tasks. We further illustrate that VideoAgent can effectively refine real-robot videos, providing an early indicator that robotics can be an effective tool in grounding video generation in the physical world.
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation
Jun 24, 2024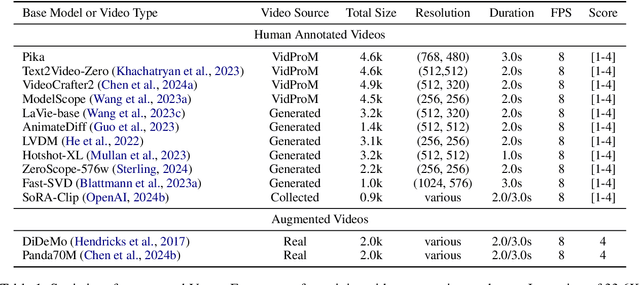

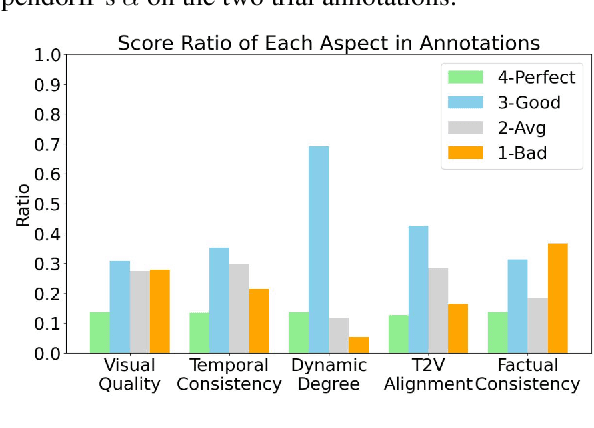

The recent years have witnessed great advances in video generation. However, the development of automatic video metrics is lagging significantly behind. None of the existing metric is able to provide reliable scores over generated videos. The main barrier is the lack of large-scale human-annotated dataset. In this paper, we release VideoFeedback, the first large-scale dataset containing human-provided multi-aspect score over 37.6K synthesized videos from 11 existing video generative models. We train VideoScore (initialized from Mantis) based on VideoFeedback to enable automatic video quality assessment. Experiments show that the Spearman correlation between VideoScore and humans can reach 77.1 on VideoFeedback-test, beating the prior best metrics by about 50 points. Further result on other held-out EvalCrafter, GenAI-Bench, and VBench show that VideoScore has consistently much higher correlation with human judges than other metrics. Due to these results, we believe VideoScore can serve as a great proxy for human raters to (1) rate different video models to track progress (2) simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.