 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks
Dec 24, 2025We present the surprising finding that a language model's reasoning capabilities can be improved by training on synthetic datasets of chain-of-thought (CoT) traces from more capable models, even when all of those traces lead to an incorrect final answer. Our experiments show this approach can yield better performance on reasoning tasks than training on human-annotated datasets. We hypothesize that two key factors explain this phenomenon: first, the distribution of synthetic data is inherently closer to the language model's own distribution, making it more amenable to learning. Second, these `incorrect' traces are often only partially flawed and contain valid reasoning steps from which the model can learn. To further test the first hypothesis, we use a language model to paraphrase human-annotated traces -- shifting their distribution closer to the model's own distribution -- and show that this improves performance. For the second hypothesis, we introduce increasingly flawed CoT traces and study to what extent models are tolerant to these flaws. We demonstrate our findings across various reasoning domains like math, algorithmic reasoning and code generation using MATH, GSM8K, Countdown and MBPP datasets on various language models ranging from 1.5B to 9B across Qwen, Llama, and Gemma models. Our study shows that curating datasets that are closer to the model's distribution is a critical aspect to consider. We also show that a correct final answer is not always a reliable indicator of a faithful reasoning process.
VideoAgent: Self-Improving Video Generation
Oct 15, 2024



Video generation has been used to generate visual plans for controlling robotic systems. Given an image observation and a language instruction, previous work has generated video plans which are then converted to robot controls to be executed. However, a major bottleneck in leveraging video generation for control lies in the quality of the generated videos, which often suffer from hallucinatory content and unrealistic physics, resulting in low task success when control actions are extracted from the generated videos. While scaling up dataset and model size provides a partial solution, integrating external feedback is both natural and essential for grounding video generation in the real world. With this observation, we propose VideoAgent for self-improving generated video plans based on external feedback. Instead of directly executing the generated video plan, VideoAgent first refines the generated video plans using a novel procedure which we call self-conditioning consistency, utilizing feedback from a pretrained vision-language model (VLM). As the refined video plan is being executed, VideoAgent collects additional data from the environment to further improve video plan generation. Experiments in simulated robotic manipulation from MetaWorld and iTHOR show that VideoAgent drastically reduces hallucination, thereby boosting success rate of downstream manipulation tasks. We further illustrate that VideoAgent can effectively refine real-robot videos, providing an early indicator that robotics can be an effective tool in grounding video generation in the physical world.
Review-Feedback-Reason (ReFeR): A Novel Framework for NLG Evaluation and Reasoning
Jul 16, 2024



Assessing the quality of Natural Language Generation (NLG) outputs, such as those produced by large language models (LLMs), poses significant challenges. Traditional approaches involve either resource-intensive human evaluations or automatic metrics, which often exhibit a low correlation with human judgment. In this study, we propose Review-Feedback-Reason (ReFeR), a novel evaluation framework for NLG using LLM agents. We rigorously test ReFeR using two pre-existing benchmark datasets on diverse NLG tasks. The proposed framework not only enhances the accuracy of NLG evaluation, surpassing previous benchmarks by $\sim$20\%, but also generates constructive feedback and significantly improves collective reasoning. This feedback is then leveraged for the creation of instruction-tuning datasets, which, when used to fine-tune smaller models like Mistral-7B, makes them extremely good evaluators, yielding a better correlation with human evaluations and performance nearly on par with GPT-3.5. We highlight the effectiveness of our methodology through its application on three reasoning benchmarks, where it outperforms most of the state-of-the-art methods, and also outperforms the reasoning capabilities of models like GPT-3.5 Turbo by $\sim$11.67\% and GPT-4 by $\sim$1\% on an average.
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation
Jun 24, 2024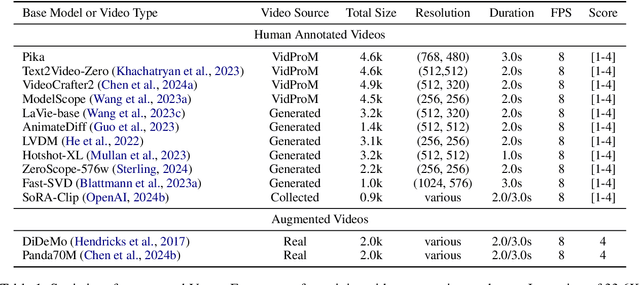

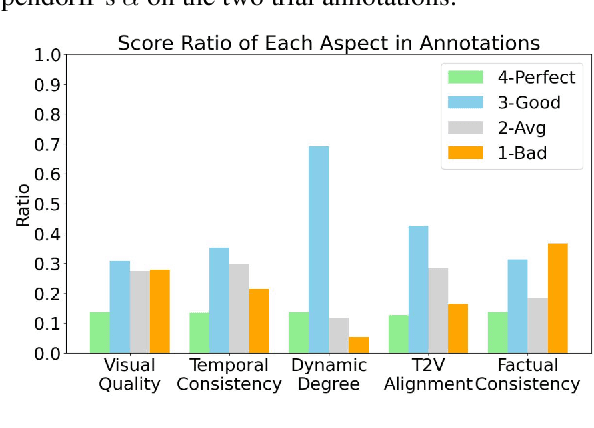

The recent years have witnessed great advances in video generation. However, the development of automatic video metrics is lagging significantly behind. None of the existing metric is able to provide reliable scores over generated videos. The main barrier is the lack of large-scale human-annotated dataset. In this paper, we release VideoFeedback, the first large-scale dataset containing human-provided multi-aspect score over 37.6K synthesized videos from 11 existing video generative models. We train VideoScore (initialized from Mantis) based on VideoFeedback to enable automatic video quality assessment. Experiments show that the Spearman correlation between VideoScore and humans can reach 77.1 on VideoFeedback-test, beating the prior best metrics by about 50 points. Further result on other held-out EvalCrafter, GenAI-Bench, and VBench show that VideoScore has consistently much higher correlation with human judges than other metrics. Due to these results, we believe VideoScore can serve as a great proxy for human raters to (1) rate different video models to track progress (2) simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Jun 04, 2024



In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities. This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates the trivial and noisy questions in MMLU. Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16% to 33% compared to MMLU but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5% in MMLU to just 2% in MMLU-Pro. Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our assessments confirm that MMLU-Pro is a more discriminative benchmark to better track progress in the field.
DiffClone: Enhanced Behaviour Cloning in Robotics with Diffusion-Driven Policy Learning
Jan 17, 2024



Robot learning tasks are extremely compute-intensive and hardware-specific. Thus the avenues of tackling these challenges, using a diverse dataset of offline demonstrations that can be used to train robot manipulation agents, is very appealing. The Train-Offline-Test-Online (TOTO) Benchmark provides a well-curated open-source dataset for offline training comprised mostly of expert data and also benchmark scores of the common offline-RL and behaviour cloning agents. In this paper, we introduce DiffClone, an offline algorithm of enhanced behaviour cloning agent with diffusion-based policy learning, and measured the efficacy of our method on real online physical robots at test time. This is also our official submission to the Train-Offline-Test-Online (TOTO) Benchmark Challenge organized at NeurIPS 2023. We experimented with both pre-trained visual representation and agent policies. In our experiments, we find that MOCO finetuned ResNet50 performs the best in comparison to other finetuned representations. Goal state conditioning and mapping to transitions resulted in a minute increase in the success rate and mean-reward. As for the agent policy, we developed DiffClone, a behaviour cloning agent improved using conditional diffusion.
Improving Question Answering with Generation of NQ-like Questions
Oct 12, 2022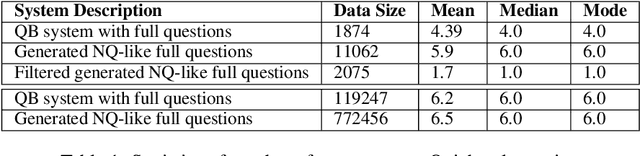
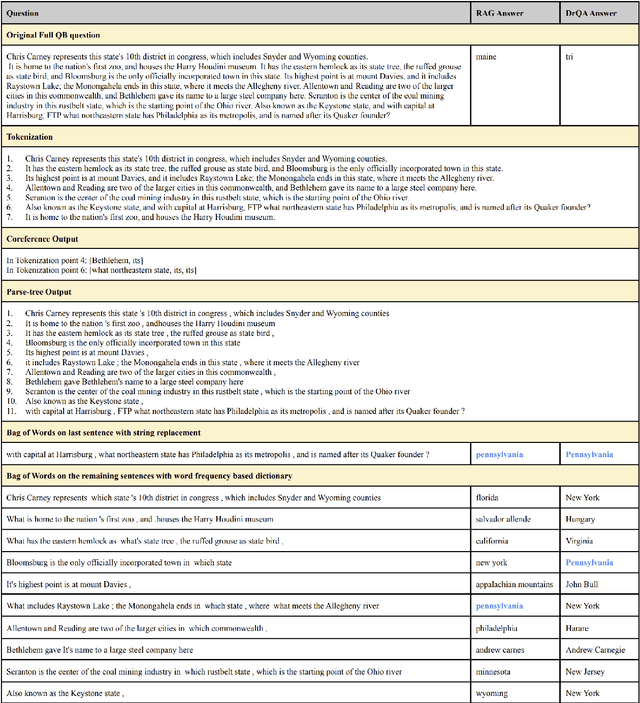
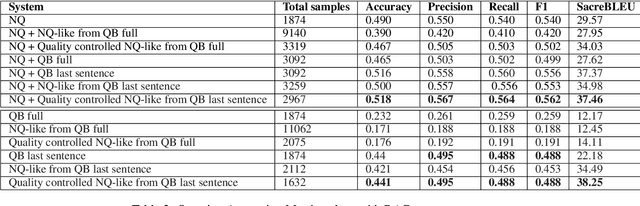
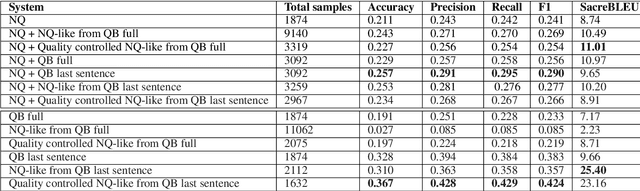
Question Answering (QA) systems require a large amount of annotated data which is costly and time-consuming to gather. Converting datasets of existing QA benchmarks are challenging due to different formats and complexities. To address these issues, we propose an algorithm to automatically generate shorter questions resembling day-to-day human communication in the Natural Questions (NQ) dataset from longer trivia questions in Quizbowl (QB) dataset by leveraging conversion in style among the datasets. This provides an automated way to generate more data for our QA systems. To ensure quality as well as quantity of data, we detect and remove ill-formed questions using a neural classifier. We demonstrate that in a low resource setting, using the generated data improves the QA performance over the baseline system on both NQ and QB data. Our algorithm improves the scalability of training data while maintaining quality of data for QA systems.
CABACE: Injecting Character Sequence Information and Domain Knowledge for Enhanced Acronym and Long-Form Extraction
Dec 25, 2021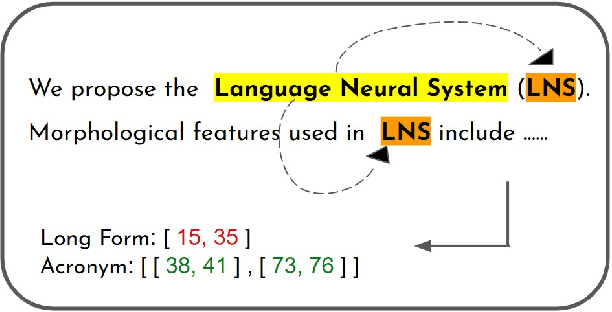
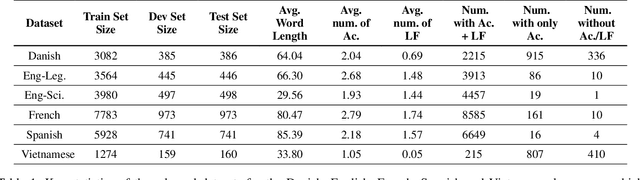
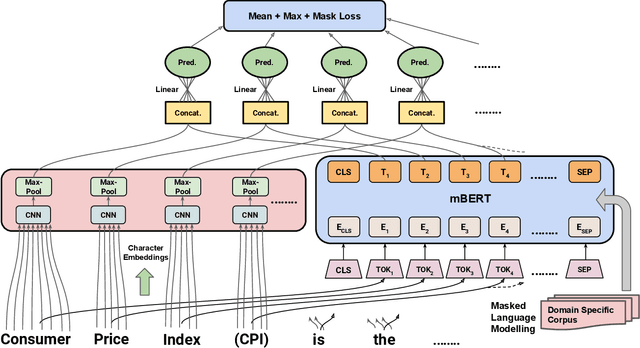
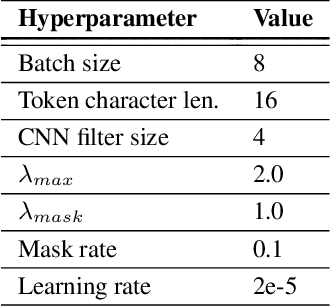
Acronyms and long-forms are commonly found in research documents, more so in documents from scientific and legal domains. Many acronyms used in such documents are domain-specific and are very rarely found in normal text corpora. Owing to this, transformer-based NLP models often detect OOV (Out of Vocabulary) for acronym tokens, especially for non-English languages, and their performance suffers while linking acronyms to their long forms during extraction. Moreover, pretrained transformer models like BERT are not specialized to handle scientific and legal documents. With these points being the overarching motivation behind this work, we propose a novel framework CABACE: Character-Aware BERT for ACronym Extraction, which takes into account character sequences in text and is adapted to scientific and legal domains by masked language modelling. We further use an objective with an augmented loss function, adding the max loss and mask loss terms to the standard cross-entropy loss for training CABACE. We further leverage pseudo labelling and adversarial data generation to improve the generalizability of the framework. Experimental results prove the superiority of the proposed framework in comparison to various baselines. Additionally, we show that the proposed framework is better suited than baseline models for zero-shot generalization to non-English languages, thus reinforcing the effectiveness of our approach. Our team BacKGProp secured the highest scores on the French dataset, second-highest on Danish and Vietnamese, and third-highest in the English-Legal dataset on the global leaderboard for the acronym extraction (AE) shared task at SDU AAAI-22.
Leveraging recent advances in Pre-Trained Language Models forEye-Tracking Prediction
Oct 09, 2021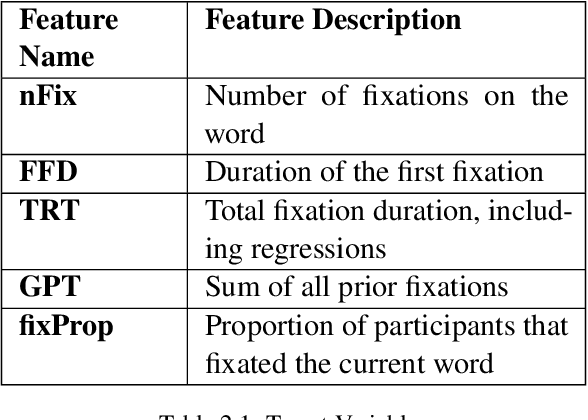
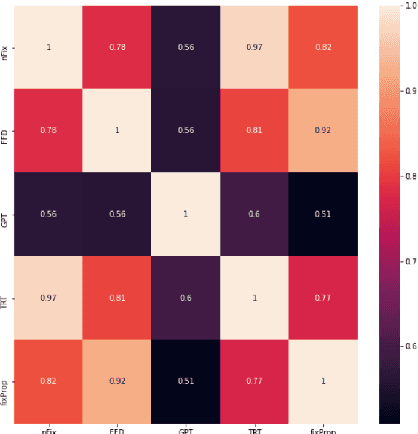
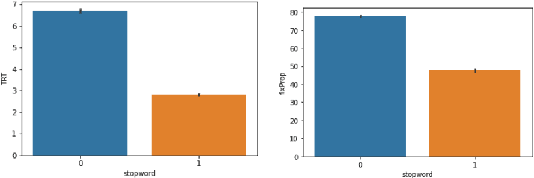
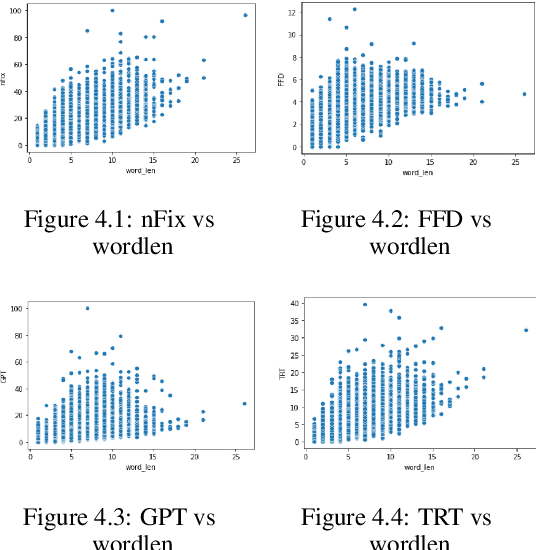
Cognitively inspired Natural Language Pro-cessing uses human-derived behavioral datalike eye-tracking data, which reflect the seman-tic representations of language in the humanbrain to augment the neural nets to solve arange of tasks spanning syntax and semanticswith the aim of teaching machines about lan-guage processing mechanisms. In this paper,we use the ZuCo 1.0 and ZuCo 2.0 dataset con-taining the eye-gaze features to explore differ-ent linguistic models to directly predict thesegaze features for each word with respect to itssentence. We tried different neural networkmodels with the words as inputs to predict thetargets. And after lots of experimentation andfeature engineering finally devised a novel ar-chitecture consisting of RoBERTa Token Clas-sifier with a dense layer on top for languagemodeling and a stand-alone model consistingof dense layers followed by a transformer layerfor the extra features we engineered. Finally,we took the mean of the outputs of both thesemodels to make the final predictions. We eval-uated the models using mean absolute error(MAE) and the R2 score for each target.