 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025
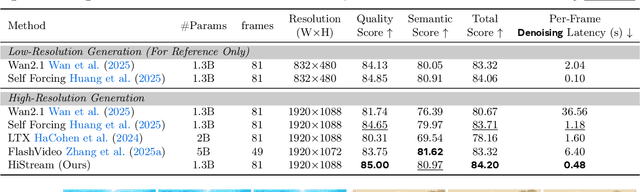
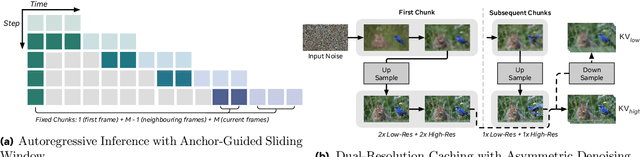
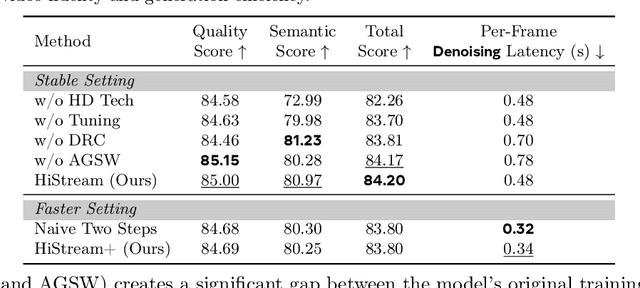
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
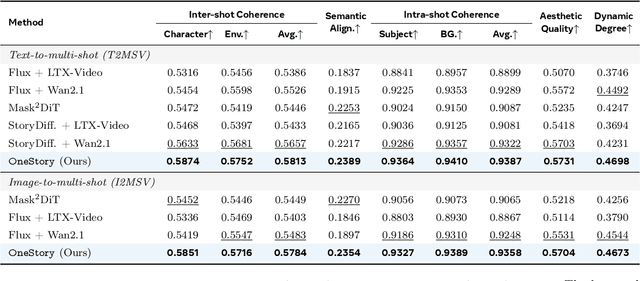
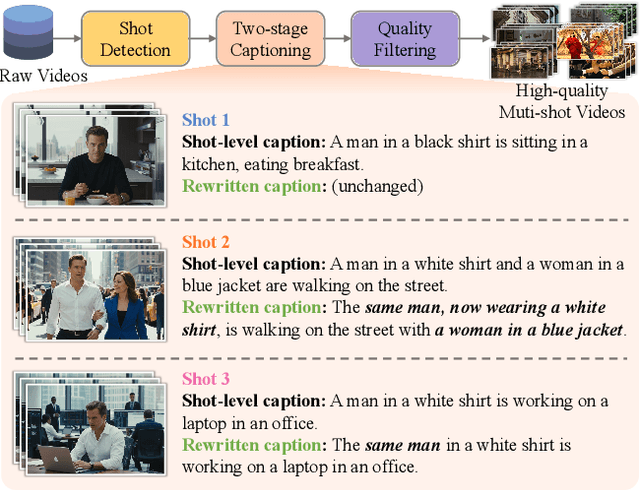

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
VideoEval-Pro: Robust and Realistic Long Video Understanding Evaluation
May 20, 2025Large multimodal models (LMMs) have recently emerged as a powerful tool for long video understanding (LVU), prompting the development of standardized LVU benchmarks to evaluate their performance. However, our investigation reveals a rather sober lesson for existing LVU benchmarks. First, most existing benchmarks rely heavily on multiple-choice questions (MCQs), whose evaluation results are inflated due to the possibility of guessing the correct answer; Second, a significant portion of questions in these benchmarks have strong priors to allow models to answer directly without even reading the input video. For example, Gemini-1.5-Pro can achieve over 50\% accuracy given a random frame from a long video on Video-MME. We also observe that increasing the number of frames does not necessarily lead to improvement on existing benchmarks, which is counterintuitive. As a result, the validity and robustness of current LVU benchmarks are undermined, impeding a faithful assessment of LMMs' long-video understanding capability. To tackle this problem, we propose VideoEval-Pro, a realistic LVU benchmark containing questions with open-ended short-answer, which truly require understanding the entire video. VideoEval-Pro assesses both segment-level and full-video understanding through perception and reasoning tasks. By evaluating 21 proprietary and open-source video LMMs, we conclude the following findings: (1) video LMMs show drastic performance ($>$25\%) drops on open-ended questions compared with MCQs; (2) surprisingly, higher MCQ scores do not lead to higher open-ended scores on VideoEval-Pro; (3) compared to other MCQ benchmarks, VideoEval-Pro benefits more from increasing the number of input frames. Our results show that VideoEval-Pro offers a more realistic and reliable measure of long video understanding, providing a clearer view of progress in this domain.
Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers
Mar 14, 2025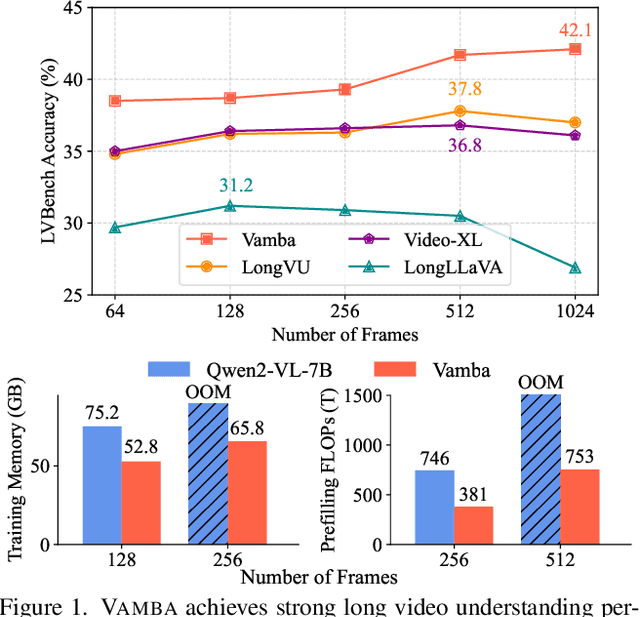
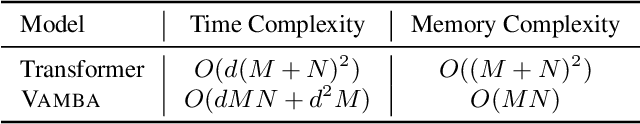
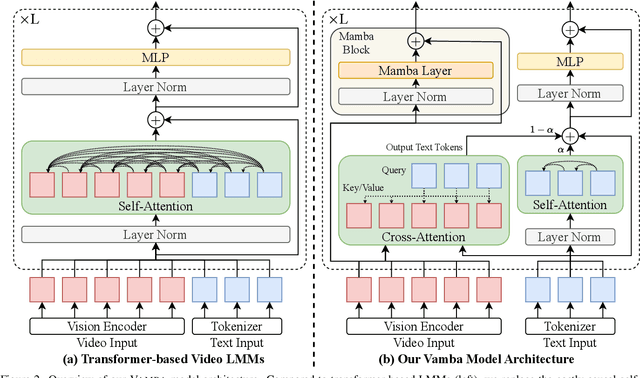
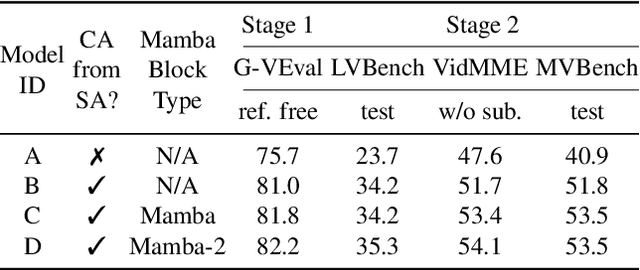
State-of-the-art transformer-based large multimodal models (LMMs) struggle to handle hour-long video inputs due to the quadratic complexity of the causal self-attention operations, leading to high computational costs during training and inference. Existing token compression-based methods reduce the number of video tokens but often incur information loss and remain inefficient for extremely long sequences. In this paper, we explore an orthogonal direction to build a hybrid Mamba-Transformer model (VAMBA) that employs Mamba-2 blocks to encode video tokens with linear complexity. Without any token reduction, VAMBA can encode more than 1024 frames (640$\times$360) on a single GPU, while transformer-based models can only encode 256 frames. On long video input, VAMBA achieves at least 50% reduction in GPU memory usage during training and inference, and nearly doubles the speed per training step compared to transformer-based LMMs. Our experimental results demonstrate that VAMBA improves accuracy by 4.3% on the challenging hour-long video understanding benchmark LVBench over prior efficient video LMMs, and maintains strong performance on a broad spectrum of long and short video understanding tasks.
VISTA: Enhancing Long-Duration and High-Resolution Video Understanding by Video Spatiotemporal Augmentation
Dec 01, 2024



Current large multimodal models (LMMs) face significant challenges in processing and comprehending long-duration or high-resolution videos, which is mainly due to the lack of high-quality datasets. To address this issue from a data-centric perspective, we propose VISTA, a simple yet effective Video Spatiotemporal Augmentation framework that synthesizes long-duration and high-resolution video instruction-following pairs from existing video-caption datasets. VISTA spatially and temporally combines videos to create new synthetic videos with extended durations and enhanced resolutions, and subsequently produces question-answer pairs pertaining to these newly synthesized videos. Based on this paradigm, we develop seven video augmentation methods and curate VISTA-400K, a video instruction-following dataset aimed at enhancing long-duration and high-resolution video understanding. Finetuning various video LMMs on our data resulted in an average improvement of 3.3% across four challenging benchmarks for long-video understanding. Furthermore, we introduce the first comprehensive high-resolution video understanding benchmark HRVideoBench, on which our finetuned models achieve a 6.5% performance gain. These results highlight the effectiveness of our framework.
OmniEdit: Building Image Editing Generalist Models Through Specialist Supervision
Nov 11, 2024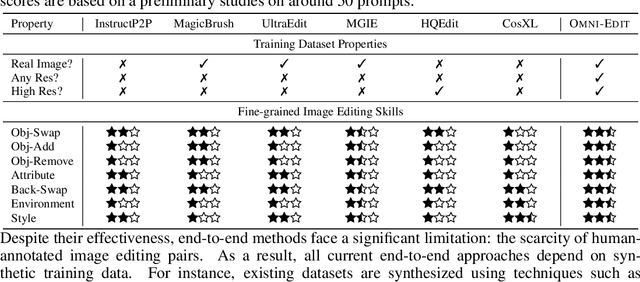
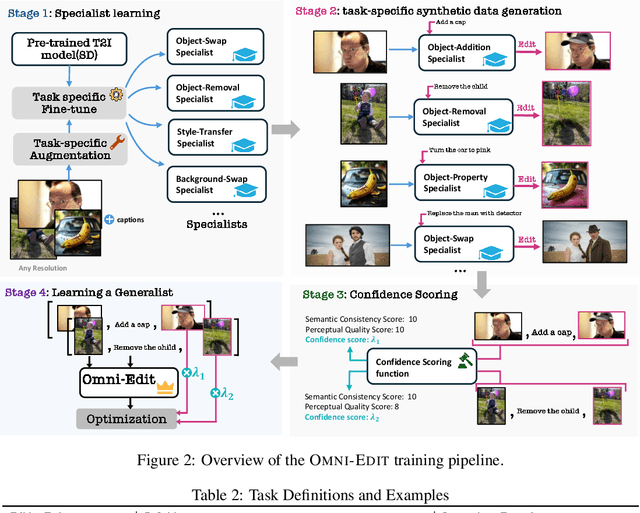
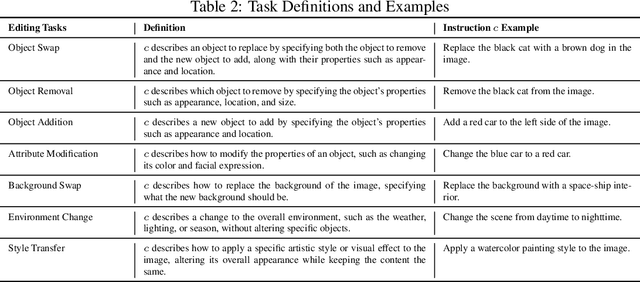

Instruction-guided image editing methods have demonstrated significant potential by training diffusion models on automatically synthesized or manually annotated image editing pairs. However, these methods remain far from practical, real-life applications. We identify three primary challenges contributing to this gap. Firstly, existing models have limited editing skills due to the biased synthesis process. Secondly, these methods are trained with datasets with a high volume of noise and artifacts. This is due to the application of simple filtering methods like CLIP-score. Thirdly, all these datasets are restricted to a single low resolution and fixed aspect ratio, limiting the versatility to handle real-world use cases. In this paper, we present \omniedit, which is an omnipotent editor to handle seven different image editing tasks with any aspect ratio seamlessly. Our contribution is in four folds: (1) \omniedit is trained by utilizing the supervision from seven different specialist models to ensure task coverage. (2) we utilize importance sampling based on the scores provided by large multimodal models (like GPT-4o) instead of CLIP-score to improve the data quality. (3) we propose a new editing architecture called EditNet to greatly boost the editing success rate, (4) we provide images with different aspect ratios to ensure that our model can handle any image in the wild. We have curated a test set containing images of different aspect ratios, accompanied by diverse instructions to cover different tasks. Both automatic evaluation and human evaluations demonstrate that \omniedit can significantly outperform all the existing models. Our code, dataset and model will be available at \url{https://tiger-ai-lab.github.io/OmniEdit/}
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Jun 04, 2024



In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities. This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates the trivial and noisy questions in MMLU. Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16% to 33% compared to MMLU but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5% in MMLU to just 2% in MMLU-Pro. Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our assessments confirm that MMLU-Pro is a more discriminative benchmark to better track progress in the field.
Video Diffusion Models: A Survey
May 06, 2024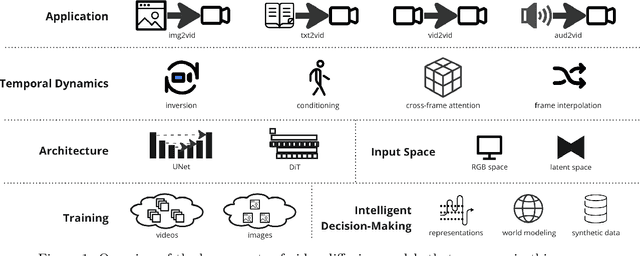
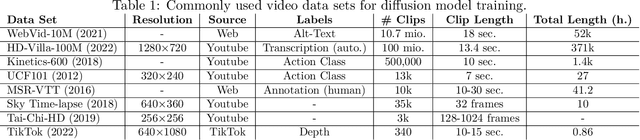
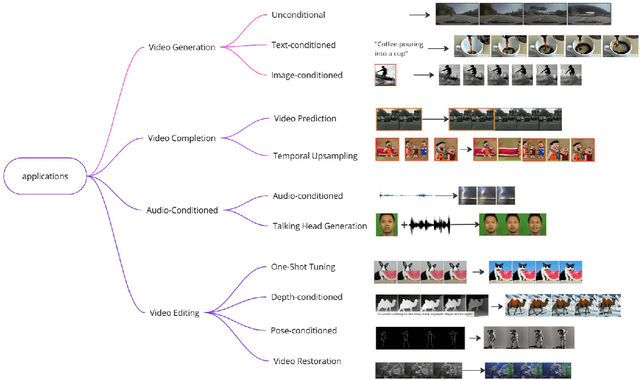

Diffusion generative models have recently become a robust technique for producing and modifying coherent, high-quality video. This survey offers a systematic overview of critical elements of diffusion models for video generation, covering applications, architectural choices, and the modeling of temporal dynamics. Recent advancements in the field are summarized and grouped into development trends. The survey concludes with an overview of remaining challenges and an outlook on the future of the field. Website: https://github.com/ndrwmlnk/Awesome-Video-Diffusion-Models
AnyV2V: A Plug-and-Play Framework For Any Video-to-Video Editing Tasks
Mar 22, 2024
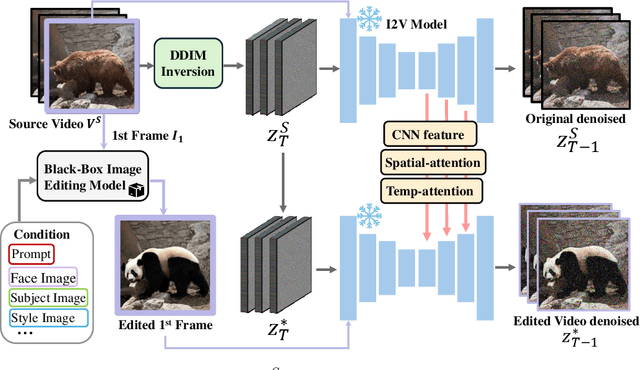
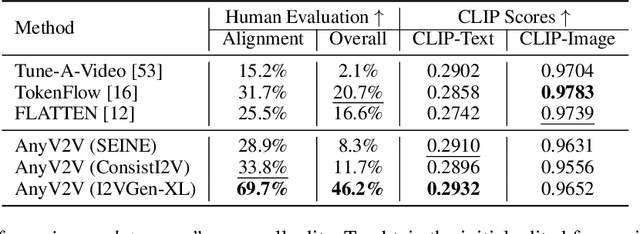

Video-to-video editing involves editing a source video along with additional control (such as text prompts, subjects, or styles) to generate a new video that aligns with the source video and the provided control. Traditional methods have been constrained to certain editing types, limiting their ability to meet the wide range of user demands. In this paper, we introduce AnyV2V, a novel training-free framework designed to simplify video editing into two primary steps: (1) employing an off-the-shelf image editing model (e.g. InstructPix2Pix, InstantID, etc) to modify the first frame, (2) utilizing an existing image-to-video generation model (e.g. I2VGen-XL) for DDIM inversion and feature injection. In the first stage, AnyV2V can plug in any existing image editing tools to support an extensive array of video editing tasks. Beyond the traditional prompt-based editing methods, AnyV2V also can support novel video editing tasks, including reference-based style transfer, subject-driven editing, and identity manipulation, which were unattainable by previous methods. In the second stage, AnyV2V can plug in any existing image-to-video models to perform DDIM inversion and intermediate feature injection to maintain the appearance and motion consistency with the source video. On the prompt-based editing, we show that AnyV2V can outperform the previous best approach by 35\% on prompt alignment, and 25\% on human preference. On the three novel tasks, we show that AnyV2V also achieves a high success rate. We believe AnyV2V will continue to thrive due to its ability to seamlessly integrate the fast-evolving image editing methods. Such compatibility can help AnyV2V to increase its versatility to cater to diverse user demands.
StructLM: Towards Building Generalist Models for Structured Knowledge Grounding
Feb 28, 2024Structured data sources, such as tables, graphs, and databases, are ubiquitous knowledge sources. Despite the demonstrated capabilities of large language models (LLMs) on plain text, their proficiency in interpreting and utilizing structured data remains limited. Our investigation reveals a notable deficiency in LLMs' ability to process structured data, e.g., ChatGPT lags behind state-of-the-art (SoTA) model by an average of 35%. To augment the Structured Knowledge Grounding (SKG) capabilities in LLMs, we have developed a comprehensive instruction tuning dataset comprising 1.1 million examples. Utilizing this dataset, we train a series of models, referred to as StructLM, based on the Code-LLaMA architecture, ranging from 7B to 34B parameters. Our StructLM series surpasses task-specific models on 14 out of 18 evaluated datasets and establishes new SoTA achievements on 7 SKG tasks. Furthermore, StructLM demonstrates exceptional generalization across 6 novel SKG tasks. Contrary to expectations, we observe that scaling model size offers marginal benefits, with StructLM-34B showing only slight improvements over StructLM-7B. This suggests that structured knowledge grounding is still a challenging task and requires more innovative design to push to a new level.