 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyV2V: A Plug-and-Play Framework For Any Video-to-Video Editing Tasks
Paper and Code

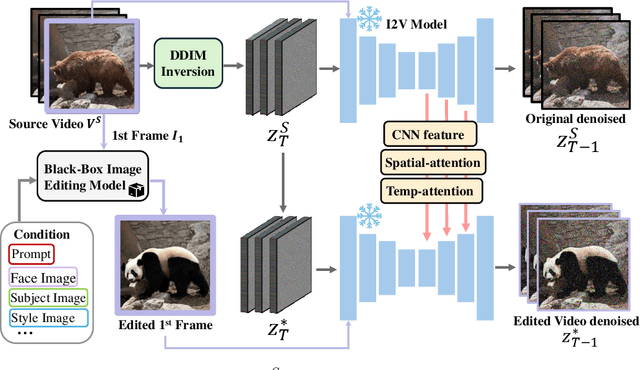
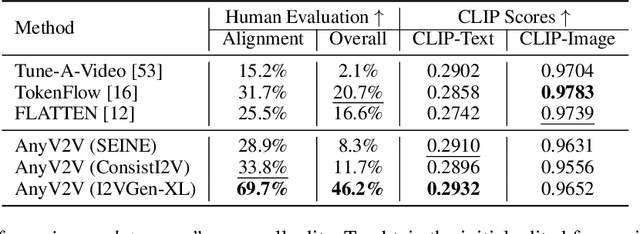

Video-to-video editing involves editing a source video along with additional control (such as text prompts, subjects, or styles) to generate a new video that aligns with the source video and the provided control. Traditional methods have been constrained to certain editing types, limiting their ability to meet the wide range of user demands. In this paper, we introduce AnyV2V, a novel training-free framework designed to simplify video editing into two primary steps: (1) employing an off-the-shelf image editing model (e.g. InstructPix2Pix, InstantID, etc) to modify the first frame, (2) utilizing an existing image-to-video generation model (e.g. I2VGen-XL) for DDIM inversion and feature injection. In the first stage, AnyV2V can plug in any existing image editing tools to support an extensive array of video editing tasks. Beyond the traditional prompt-based editing methods, AnyV2V also can support novel video editing tasks, including reference-based style transfer, subject-driven editing, and identity manipulation, which were unattainable by previous methods. In the second stage, AnyV2V can plug in any existing image-to-video models to perform DDIM inversion and intermediate feature injection to maintain the appearance and motion consistency with the source video. On the prompt-based editing, we show that AnyV2V can outperform the previous best approach by 35\% on prompt alignment, and 25\% on human preference. On the three novel tasks, we show that AnyV2V also achieves a high success rate. We believe AnyV2V will continue to thrive due to its ability to seamlessly integrate the fast-evolving image editing methods. Such compatibility can help AnyV2V to increase its versatility to cater to diverse user demands.