 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Visual Generation in Unified Multimodal Models with Understanding Supervision
May 07, 2026Unified multimodal models are envisioned to bridge the gap between understanding and generation. Yet, to achieve competitive performance, state-of-the-art models adopt largely decoupled understanding and generation components. This design, while effective for individual tasks, weakens the connection required for mutual enhancement, leaving the potential synergy empirically uncertain. We propose to explicitly restore this synergy by introducing Understanding-Oriented Post-Training (UNO), a lightweight framework that treats understanding not only as a distinct task, but also a direct supervisory signal to steer generative representations. By incorporating objectives that encode semantic abstraction (captioning) and structural details (visual regression), we enable effective gradient flow from understanding to generation. Extensive experiments on image generation and editing demonstrate that understanding can serve as an effective catalyst for generation.
TexEditor: Structure-Preserving Text-Driven Texture Editing
Mar 19, 2026Text-guided texture editing aims to modify object appearance while preserving the underlying geometric structure. However, our empirical analysis reveals that even SOTA editing models frequently struggle to maintain structural consistency during texture editing, despite the intended changes being purely appearance-related. Motivated by this observation, we jointly enhance structure preservation from both data and training perspectives, and build TexEditor, a dedicated texture editing model based on Qwen-Image-Edit-2509. Firstly, we construct TexBlender, a high-quality SFT dataset generated with Blender, which provides strong structural priors for a cold start. Sec- ondly, we introduce StructureNFT, a RL-based approach that integrates structure-preserving losses to transfer the structural priors learned during SFT to real-world scenes. Moreover, due to the limited realism and evaluation coverage of existing benchmarks, we introduce TexBench, a general-purpose real-world benchmark for text-guided texture editing. Extensive experiments on existing Blender-based texture benchmarks and our TexBench show that TexEditor consistently outperforms strong baselines such as Nano Banana Pro. In addition, we assess TexEditor on the general purpose benchmark ImgEdit to validate its generalization. Our code and data are available at https://github.com/KlingAIResearch/TexEditor.
SemanticALLI: Caching Reasoning, Not Just Responses, in Agentic Systems
Jan 22, 2026Agentic AI pipelines suffer from a hidden inefficiency: they frequently reconstruct identical intermediate logic, such as metric normalization or chart scaffolding, even when the user's natural language phrasing is entirely novel. Conventional boundary caching fails to capture this inefficiency because it treats inference as a monolithic black box. We introduce SemanticALLI, a pipeline-aware architecture within Alli (PMG's marketing intelligence platform), designed to operationalize redundant reasoning. By decomposing generation into Analytic Intent Resolution (AIR) and Visualization Synthesis (VS), SemanticALLI elevates structured intermediate representations (IRs) to first-class, cacheable artifacts. The impact of caching within the agentic loop is substantial. In our evaluation, baseline monolithic caching caps at a 38.7% hit rate due to linguistic variance. In contrast, our structured approach allows for an additional stage, the Visualization Synthesis stage, to achieve an 83.10% hit rate, bypassing 4,023 LLM calls with a median latency of just 2.66 ms. This internal reuse reduces total token consumption, offering a practical lesson for AI system design: even when users rarely repeat themselves, the pipeline often does, at stable, structured checkpoints where caching is most reliable.
Artificial Intelligence Driven Channel Coding and Resource Optimization for Wireless Networks
Jan 11, 2026The ongoing evolution of 5G and its enhanced version, 5G+, has significantly transformed the telecommunications landscape, driving an unprecedented demand for ultra-high-speed data transmission, ultra-low latency, and resilient connectivity. These capabilities are essential for enabling mission-critical applications such as the Internet of Things, autonomous vehicles, and smart city infrastructures. This paper investigates the important role of Artificial Intelligence (AI) in addressing the key challenges faced by 5G/5G+ networks, including interference mitigation, dynamic resource allocation, and maintaining seamless network operation. The study particularly focuses on AI-driven innovations in coding theory, which offer advanced solutions to the limitations of conventional error correction and modulation techniques. By employing deep learning, reinforcement learning, and neural network-based approaches, this research demonstrates significant advancements in error correction performance, decoding efficiency, and adaptive transmission strategies. Additionally, the integration of AI with emerging technologies, such as massive multiple-input and multiple-output, intelligent reflecting surfaces, and privacy-enhancing mechanisms, is discussed, highlighting their potential to propel the next generation of wireless networks. This paper also provides insights into the transformative impact of AI on modern wireless communication, establishing a foundation for scalable, adaptive, and more efficient network architectures.
ResTok: Learning Hierarchical Residuals in 1D Visual Tokenizers for Autoregressive Image Generation
Jan 07, 2026Existing 1D visual tokenizers for autoregressive (AR) generation largely follow the design principles of language modeling, as they are built directly upon transformers whose priors originate in language, yielding single-hierarchy latent tokens and treating visual data as flat sequential token streams. However, this language-like formulation overlooks key properties of vision, particularly the hierarchical and residual network designs that have long been essential for convergence and efficiency in visual models. To bring "vision" back to vision, we propose the Residual Tokenizer (ResTok), a 1D visual tokenizer that builds hierarchical residuals for both image tokens and latent tokens. The hierarchical representations obtained through progressively merging enable cross-level feature fusion at each layer, substantially enhancing representational capacity. Meanwhile, the semantic residuals between hierarchies prevent information overlap, yielding more concentrated latent distributions that are easier for AR modeling. Cross-level bindings consequently emerge without any explicit constraints. To accelerate the generation process, we further introduce a hierarchical AR generator that substantially reduces sampling steps by predicting an entire level of latent tokens at once rather than generating them strictly token-by-token. Extensive experiments demonstrate that restoring hierarchical residual priors in visual tokenization significantly improves AR image generation, achieving a gFID of 2.34 on ImageNet-256 with only 9 sampling steps. Code is available at https://github.com/Kwai-Kolors/ResTok.
SVG-T2I: Scaling Up Text-to-Image Latent Diffusion Model Without Variational Autoencoder
Dec 12, 2025Visual generation grounded in Visual Foundation Model (VFM) representations offers a highly promising unified pathway for integrating visual understanding, perception, and generation. Despite this potential, training large-scale text-to-image diffusion models entirely within the VFM representation space remains largely unexplored. To bridge this gap, we scale the SVG (Self-supervised representations for Visual Generation) framework, proposing SVG-T2I to support high-quality text-to-image synthesis directly in the VFM feature domain. By leveraging a standard text-to-image diffusion pipeline, SVG-T2I achieves competitive performance, reaching 0.75 on GenEval and 85.78 on DPG-Bench. This performance validates the intrinsic representational power of VFMs for generative tasks. We fully open-source the project, including the autoencoder and generation model, together with their training, inference, evaluation pipelines, and pre-trained weights, to facilitate further research in representation-driven visual generation.
ContextDrag: Precise Drag-Based Image Editing via Context-Preserving Token Injection and Position-Consistent Attention
Dec 09, 2025Drag-based image editing aims to modify visual content followed by user-specified drag operations. Despite existing methods having made notable progress, they still fail to fully exploit the contextual information in the reference image, including fine-grained texture details, leading to edits with limited coherence and fidelity. To address this challenge, we introduce ContextDrag, a new paradigm for drag-based editing that leverages the strong contextual modeling capability of editing models, such as FLUX-Kontext. By incorporating VAE-encoded features from the reference image, ContextDrag can leverage rich contextual cues and preserve fine-grained details, without the need for finetuning or inversion. Specifically, ContextDrag introduced a novel Context-preserving Token Injection (CTI) that injects noise-free reference features into their correct destination locations via a Latent-space Reverse Mapping (LRM) algorithm. This strategy enables precise drag control while preserving consistency in both semantics and texture details. Second, ContextDrag adopts a novel Position-Consistent Attention (PCA), which positional re-encodes the reference tokens and applies overlap-aware masking to eliminate interference from irrelevant reference features. Extensive experiments on DragBench-SR and DragBench-DR demonstrate that our approach surpasses all existing SOTA methods. Code will be publicly available.
DialogGraph-LLM: Graph-Informed LLMs for End-to-End Audio Dialogue Intent Recognition
Nov 17, 2025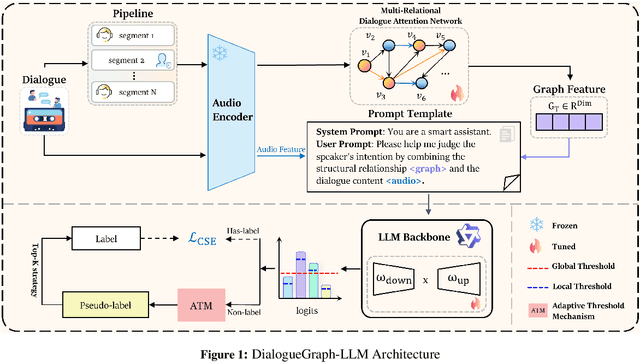



Recognizing speaker intent in long audio dialogues among speakers has a wide range of applications, but is a non-trivial AI task due to complex inter-dependencies in speaker utterances and scarce annotated data. To address these challenges, an end-to-end framework, namely DialogGraph-LLM, is proposed in the current work. DialogGraph-LLM combines a novel Multi-Relational Dialogue Attention Network (MR-DAN) architecture with multimodal foundation models (e.g., Qwen2.5-Omni-7B) for direct acoustic-to-intent inference. An adaptive semi-supervised learning strategy is designed using LLM with a confidence-aware pseudo-label generation mechanism based on dual-threshold filtering using both global and class confidences, and an entropy-based sample selection process that prioritizes high-information unlabeled instances. Extensive evaluations on the proprietary MarketCalls corpus and the publicly available MIntRec 2.0 benchmark demonstrate DialogGraph-LLM's superiority over strong audio and text-driven baselines. The framework demonstrates strong performance and efficiency in intent recognition in real world scenario audio dialogues, proving its practical value for audio-rich domains with limited supervision. Our code is available at https://github.com/david188888/DialogGraph-LLM.
Align-then-Slide: A complete evaluation framework for Ultra-Long Document-Level Machine Translation
Sep 04, 2025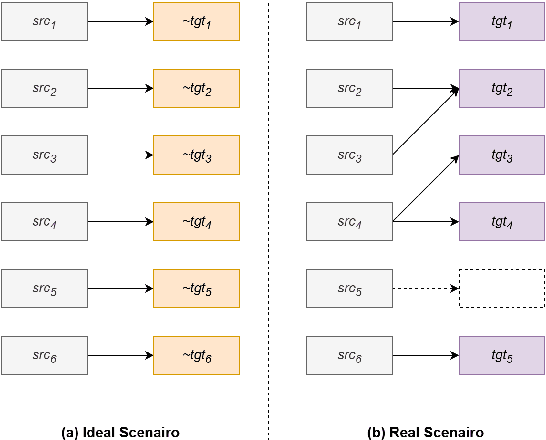
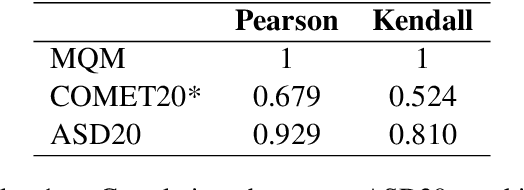
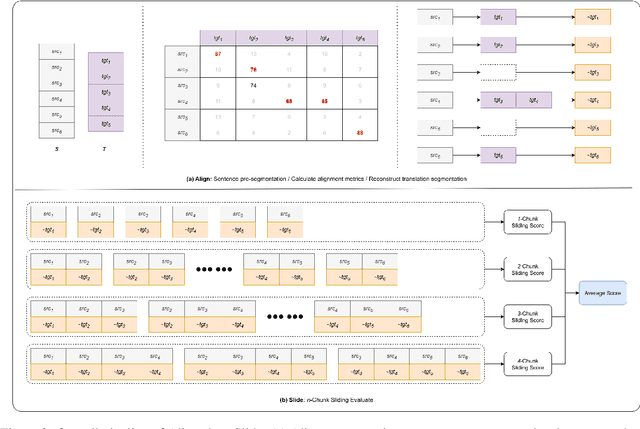
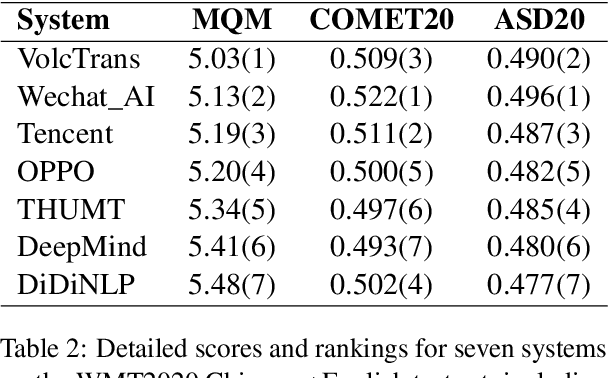
Large language models (LLMs) have ushered in a new era for document-level machine translation (\textit{doc}-mt), yet their whole-document outputs challenge existing evaluation methods that assume sentence-by-sentence alignment. We introduce \textit{\textbf{Align-then-Slide}}, a complete evaluation framework for ultra-long doc-mt. In the Align stage, we automatically infer sentence-level source-target correspondences and rebuild the target to match the source sentence number, resolving omissions and many-to-one/one-to-many mappings. In the n-Chunk Sliding Evaluate stage, we calculate averaged metric scores under 1-, 2-, 3- and 4-chunk for multi-granularity assessment. Experiments on the WMT benchmark show a Pearson correlation of 0.929 between our method with expert MQM rankings. On a newly curated real-world test set, our method again aligns closely with human judgments. Furthermore, preference data produced by Align-then-Slide enables effective CPO training and its direct use as a reward model for GRPO, both yielding translations preferred over a vanilla SFT baseline. The results validate our framework as an accurate, robust, and actionable evaluation tool for doc-mt systems.
Mod-Adapter: Tuning-Free and Versatile Multi-concept Personalization via Modulation Adapter
May 24, 2025Personalized text-to-image generation aims to synthesize images of user-provided concepts in diverse contexts. Despite recent progress in multi-concept personalization, most are limited to object concepts and struggle to customize abstract concepts (e.g., pose, lighting). Some methods have begun exploring multi-concept personalization supporting abstract concepts, but they require test-time fine-tuning for each new concept, which is time-consuming and prone to overfitting on limited training images. In this work, we propose a novel tuning-free method for multi-concept personalization that can effectively customize both object and abstract concepts without test-time fine-tuning. Our method builds upon the modulation mechanism in pretrained Diffusion Transformers (DiTs) model, leveraging the localized and semantically meaningful properties of the modulation space. Specifically, we propose a novel module, Mod-Adapter, to predict concept-specific modulation direction for the modulation process of concept-related text tokens. It incorporates vision-language cross-attention for extracting concept visual features, and Mixture-of-Experts (MoE) layers that adaptively map the concept features into the modulation space. Furthermore, to mitigate the training difficulty caused by the large gap between the concept image space and the modulation space, we introduce a VLM-guided pretraining strategy that leverages the strong image understanding capabilities of vision-language models to provide semantic supervision signals. For a comprehensive comparison, we extend a standard benchmark by incorporating abstract concepts. Our method achieves state-of-the-art performance in multi-concept personalization, supported by quantitative, qualitative, and human evaluations.