 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVShare: Semantic-Aware Key-Value Cache Sharing for Efficient Large Language Model Inference
Paper and Code
Mar 17, 2025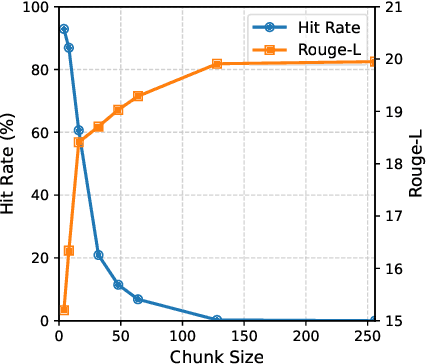


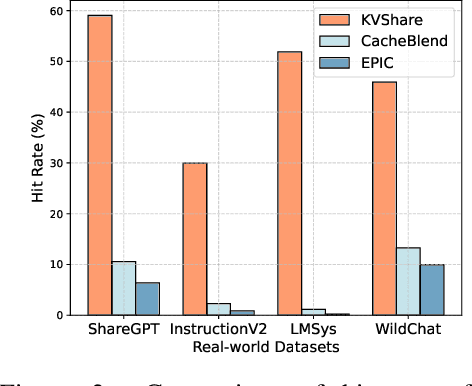
This paper presents KVShare, a multi-user Key-Value (KV) Cache sharing technology based on semantic similarity, designed to enhance the inference efficiency of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). Addressing the limitations of existing prefix caching (strict text prefix matching) and semantic caching (loss of response diversity), KVShare achieves fine-grained KV cache reuse through semantic alignment algorithms and differential editing operations. Experiments on real-world user conversation datasets demonstrate that KVShare improves KV cache hit rates by over 60%, while maintaining output quality comparable to full computation (no significant degradation in BLEU and Rouge-L metrics). This approach effectively reduces GPU resource consumption and is applicable to scenarios with repetitive queries, such as healthcare and education.