 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Video Diffusion Generation with Segmented Cross-Attention and Content-Rich Video Data Curation
Paper and Code
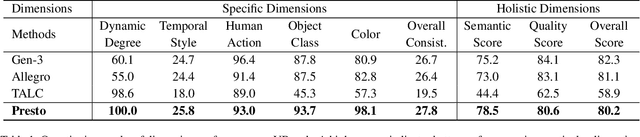
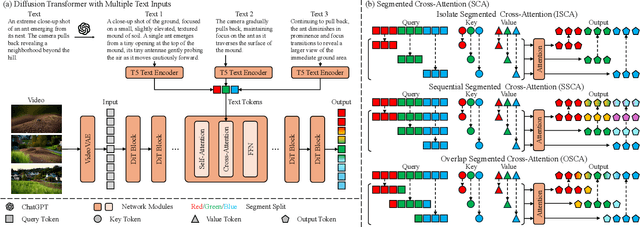


We introduce Presto, a novel video diffusion model designed to generate 15-second videos with long-range coherence and rich content. Extending video generation methods to maintain scenario diversity over long durations presents significant challenges. To address this, we propose a Segmented Cross-Attention (SCA) strategy, which splits hidden states into segments along the temporal dimension, allowing each segment to cross-attend to a corresponding sub-caption. SCA requires no additional parameters, enabling seamless incorporation into current DiT-based architectures. To facilitate high-quality long video generation, we build the LongTake-HD dataset, consisting of 261k content-rich videos with scenario coherence, annotated with an overall video caption and five progressive sub-captions. Experiments show that our Presto achieves 78.5% on the VBench Semantic Score and 100% on the Dynamic Degree, outperforming existing state-of-the-art video generation methods. This demonstrates that our proposed Presto significantly enhances content richness, maintains long-range coherence, and captures intricate textual details. More details are displayed on our project page: https://presto-video.github.io/.