 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jan 06, 2026Vision-Language-Action (VLA) models, which integrate pretrained large Vision-Language Models (VLM) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM's general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM's performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning.
Long Video Diffusion Generation with Segmented Cross-Attention and Content-Rich Video Data Curation
Dec 02, 2024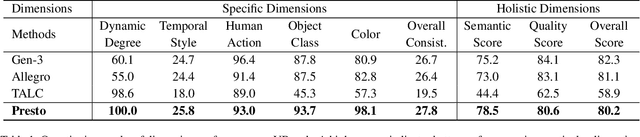
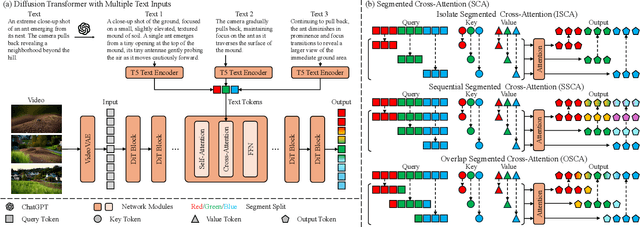


We introduce Presto, a novel video diffusion model designed to generate 15-second videos with long-range coherence and rich content. Extending video generation methods to maintain scenario diversity over long durations presents significant challenges. To address this, we propose a Segmented Cross-Attention (SCA) strategy, which splits hidden states into segments along the temporal dimension, allowing each segment to cross-attend to a corresponding sub-caption. SCA requires no additional parameters, enabling seamless incorporation into current DiT-based architectures. To facilitate high-quality long video generation, we build the LongTake-HD dataset, consisting of 261k content-rich videos with scenario coherence, annotated with an overall video caption and five progressive sub-captions. Experiments show that our Presto achieves 78.5% on the VBench Semantic Score and 100% on the Dynamic Degree, outperforming existing state-of-the-art video generation methods. This demonstrates that our proposed Presto significantly enhances content richness, maintains long-range coherence, and captures intricate textual details. More details are displayed on our project page: https://presto-video.github.io/.
Fleximo: Towards Flexible Text-to-Human Motion Video Generation
Nov 29, 2024
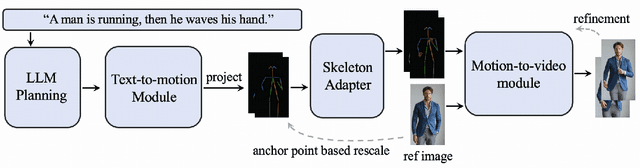


Current methods for generating human motion videos rely on extracting pose sequences from reference videos, which restricts flexibility and control. Additionally, due to the limitations of pose detection techniques, the extracted pose sequences can sometimes be inaccurate, leading to low-quality video outputs. We introduce a novel task aimed at generating human motion videos solely from reference images and natural language. This approach offers greater flexibility and ease of use, as text is more accessible than the desired guidance videos. However, training an end-to-end model for this task requires millions of high-quality text and human motion video pairs, which are challenging to obtain. To address this, we propose a new framework called Fleximo, which leverages large-scale pre-trained text-to-3D motion models. This approach is not straightforward, as the text-generated skeletons may not consistently match the scale of the reference image and may lack detailed information. To overcome these challenges, we introduce an anchor point based rescale method and design a skeleton adapter to fill in missing details and bridge the gap between text-to-motion and motion-to-video generation. We also propose a video refinement process to further enhance video quality. A large language model (LLM) is employed to decompose natural language into discrete motion sequences, enabling the generation of motion videos of any desired length. To assess the performance of Fleximo, we introduce a new benchmark called MotionBench, which includes 400 videos across 20 identities and 20 motions. We also propose a new metric, MotionScore, to evaluate the accuracy of motion following. Both qualitative and quantitative results demonstrate that our method outperforms existing text-conditioned image-to-video generation methods. All code and model weights will be made publicly available.
Improving Multi-Subject Consistency in Open-Domain Image Generation with Isolation and Reposition Attention
Nov 28, 2024



Training-free diffusion models have achieved remarkable progress in generating multi-subject consistent images within open-domain scenarios. The key idea of these methods is to incorporate reference subject information within the attention layer. However, existing methods still obtain suboptimal performance when handling numerous subjects. This paper reveals the two primary issues contributing to this deficiency. Firstly, there is undesired interference among different subjects within the target image. Secondly, tokens tend to reference nearby tokens, which reduces the effectiveness of the attention mechanism when there is a significant positional difference between subjects in reference and target images. To address these challenges, we propose a training-free diffusion model with Isolation and Reposition Attention, named IR-Diffusion. Specifically, Isolation Attention ensures that multiple subjects in the target image do not reference each other, effectively eliminating the subject fusion. On the other hand, Reposition Attention involves scaling and repositioning subjects in both reference and target images to the same position within the images. This ensures that subjects in the target image can better reference those in the reference image, thereby maintaining better consistency. Extensive experiments demonstrate that the proposed methods significantly enhance multi-subject consistency, outperforming all existing methods in open-domain scenarios.
Allegro: Open the Black Box of Commercial-Level Video Generation Model
Oct 20, 2024



Significant advancements have been made in the field of video generation, with the open-source community contributing a wealth of research papers and tools for training high-quality models. However, despite these efforts, the available information and resources remain insufficient for achieving commercial-level performance. In this report, we open the black box and introduce $\textbf{Allegro}$, an advanced video generation model that excels in both quality and temporal consistency. We also highlight the current limitations in the field and present a comprehensive methodology for training high-performance, commercial-level video generation models, addressing key aspects such as data, model architecture, training pipeline, and evaluation. Our user study shows that Allegro surpasses existing open-source models and most commercial models, ranking just behind Hailuo and Kling. Code: https://github.com/rhymes-ai/Allegro , Model: https://huggingface.co/rhymes-ai/Allegro , Gallery: https://rhymes.ai/allegro_gallery .
DreamStory: Open-Domain Story Visualization by LLM-Guided Multi-Subject Consistent Diffusion
Jul 17, 2024
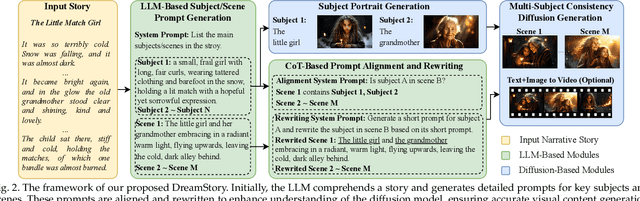
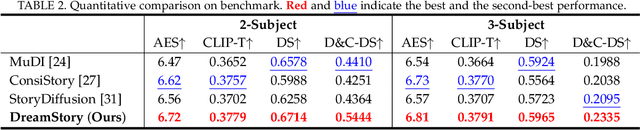
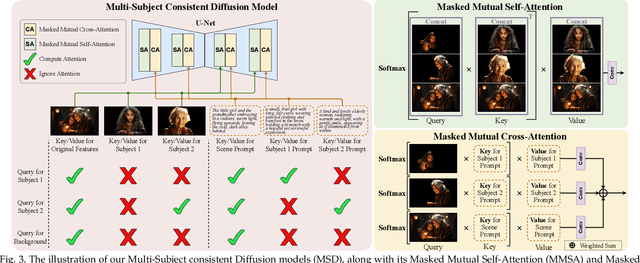
Story visualization aims to create visually compelling images or videos corresponding to textual narratives. Despite recent advances in diffusion models yielding promising results, existing methods still struggle to create a coherent sequence of subject-consistent frames based solely on a story. To this end, we propose DreamStory, an automatic open-domain story visualization framework by leveraging the LLMs and a novel multi-subject consistent diffusion model. DreamStory consists of (1) an LLM acting as a story director and (2) an innovative Multi-Subject consistent Diffusion model (MSD) for generating consistent multi-subject across the images. First, DreamStory employs the LLM to generate descriptive prompts for subjects and scenes aligned with the story, annotating each scene's subjects for subsequent subject-consistent generation. Second, DreamStory utilizes these detailed subject descriptions to create portraits of the subjects, with these portraits and their corresponding textual information serving as multimodal anchors (guidance). Finally, the MSD uses these multimodal anchors to generate story scenes with consistent multi-subject. Specifically, the MSD includes Masked Mutual Self-Attention (MMSA) and Masked Mutual Cross-Attention (MMCA) modules. MMSA and MMCA modules ensure appearance and semantic consistency with reference images and text, respectively. Both modules employ masking mechanisms to prevent subject blending. To validate our approach and promote progress in story visualization, we established a benchmark, DS-500, which can assess the overall performance of the story visualization framework, subject-identification accuracy, and the consistency of the generation model. Extensive experiments validate the effectiveness of DreamStory in both subjective and objective evaluations. Please visit our project homepage at https://dream-xyz.github.io/dreamstory.
VLM-Eval: A General Evaluation on Video Large Language Models
Nov 20, 2023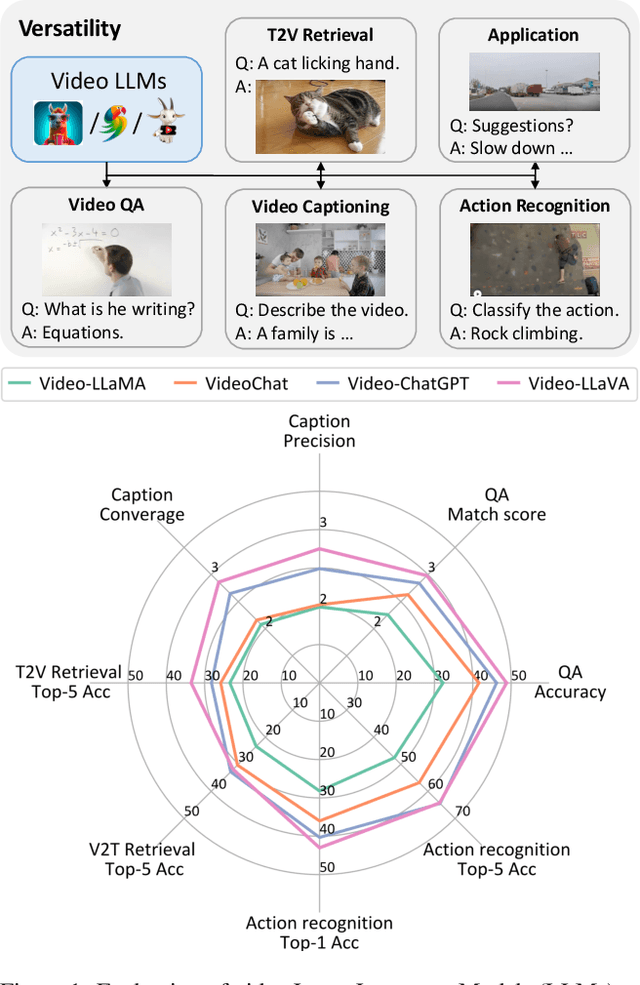


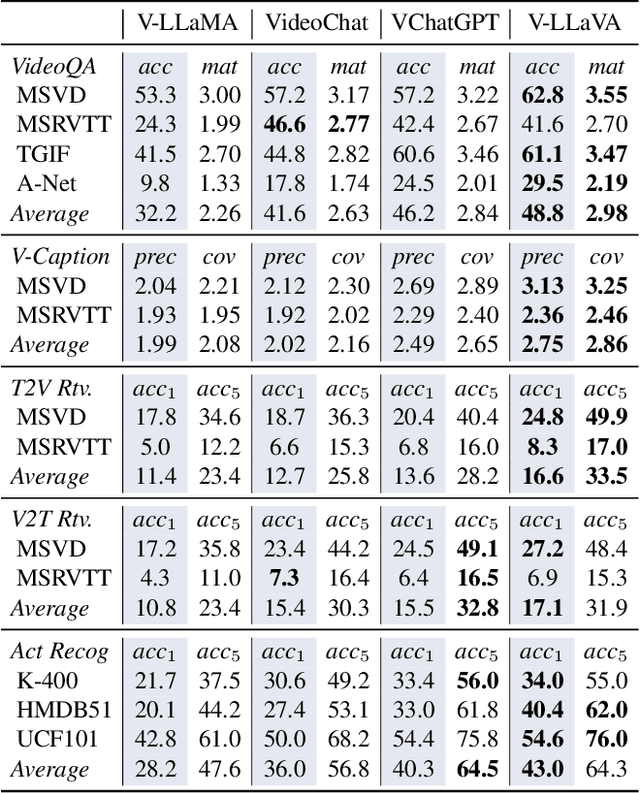
Despite the rapid development of video Large Language Models (LLMs), a comprehensive evaluation is still absent. In this paper, we introduce a unified evaluation that encompasses multiple video tasks, including captioning, question and answering, retrieval, and action recognition. In addition to conventional metrics, we showcase how GPT-based evaluation can match human-like performance in assessing response quality across multiple aspects. We propose a simple baseline: Video-LLaVA, which uses a single linear projection and outperforms existing video LLMs. Finally, we evaluate video LLMs beyond academic datasets, which show encouraging recognition and reasoning capabilities in driving scenarios with only hundreds of video-instruction pairs for fine-tuning. We hope our work can serve as a unified evaluation for video LLMs, and help expand more practical scenarios. The evaluation code will be available soon.
Confidence-aware Adversarial Learning for Self-supervised Semantic Matching
Aug 25, 2020
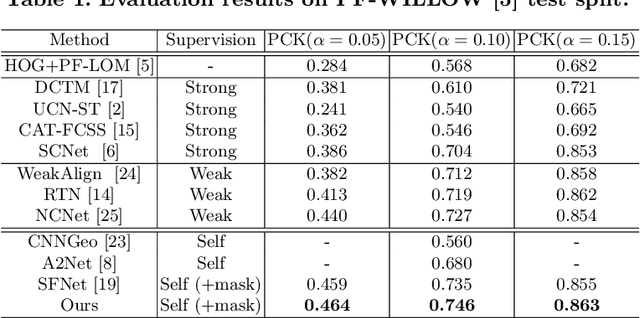
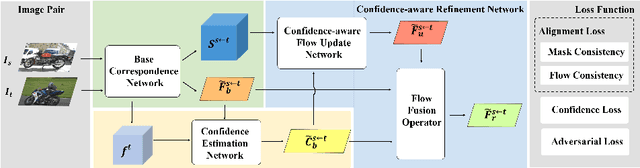
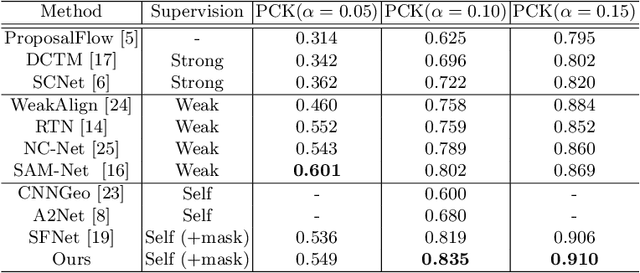
In this paper, we aim to address the challenging task of semantic matching where matching ambiguity is difficult to resolve even with learned deep features. We tackle this problem by taking into account the confidence in predictions and develop a novel refinement strategy to correct partial matching errors. Specifically, we introduce a Confidence-Aware Semantic Matching Network (CAMNet) which instantiates two key ideas of our approach. First, we propose to estimate a dense confidence map for a matching prediction through self-supervised learning. Second, based on the estimated confidence, we refine initial predictions by propagating reliable matching to the rest of locations on the image plane. In addition, we develop a new hybrid loss in which we integrate a semantic alignment loss with a confidence loss, and an adversarial loss that measures the quality of semantic correspondence. We are the first that exploit confidence during refinement to improve semantic matching accuracy and develop an end-to-end self-supervised adversarial learning procedure for the entire matching network. We evaluate our method on two public benchmarks, on which we achieve top performance over the prior state of the art. We will release our source code at https://github.com/ShuaiyiHuang/CAMNet.
Dynamic Context Correspondence Network for Semantic Alignment
Sep 08, 2019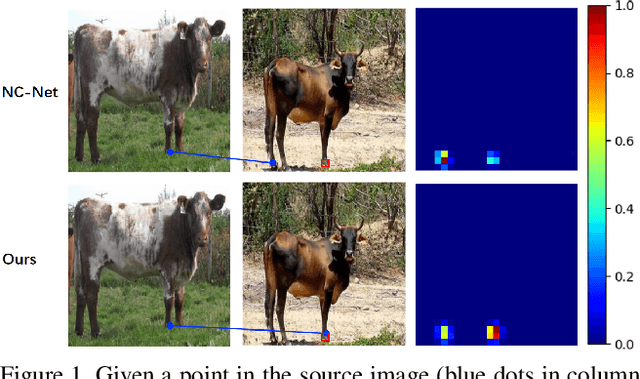
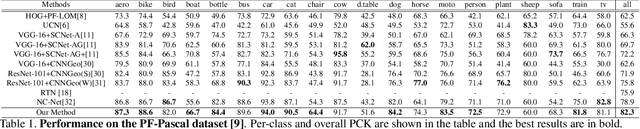
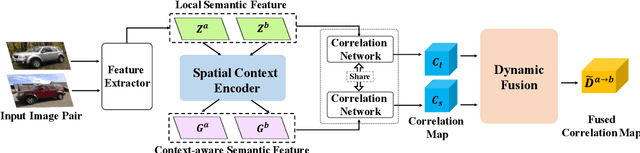
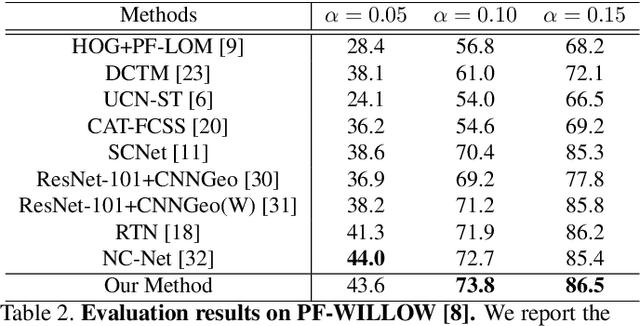
Establishing semantic correspondence is a core problem in computer vision and remains challenging due to large intra-class variations and lack of annotated data. In this paper, we aim to incorporate global semantic context in a flexible manner to overcome the limitations of prior work that relies on local semantic representations. To this end, we first propose a context-aware semantic representation that incorporates spatial layout for robust matching against local ambiguities. We then develop a novel dynamic fusion strategy based on attention mechanism to weave the advantages of both local and context features by integrating semantic cues from multiple scales. We instantiate our strategy by designing an end-to-end learnable deep network, named as Dynamic Context Correspondence Network (DCCNet). To train the network, we adopt a multi-auxiliary task loss to improve the efficiency of our weakly-supervised learning procedure. Our approach achieves superior or competitive performance over previous methods on several challenging datasets, including PF-Pascal, PF-Willow, and TSS, demonstrating its effectiveness and generality.