 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing guidance for missing data in diffusion-based sequential recommendation
Jan 22, 2026Contemporary sequential recommendation methods are becoming more complex, shifting from classification to a diffusion-guided generative paradigm. However, the quality of guidance in the form of user information is often compromised by missing data in the observed sequences, leading to suboptimal generation quality. Existing methods address this by removing locally similar items, but overlook ``critical turning points'' in user interest, which are crucial for accurately predicting subsequent user intent. To address this, we propose a novel Counterfactual Attention Regulation Diffusion model (CARD), which focuses on amplifying the signal from key interest-turning-point items while concurrently identifying and suppressing noise within the user sequence. CARD consists of (1) a Dual-side Thompson Sampling method to identify sequences undergoing significant interest shift, and (2) a counterfactual attention mechanism for these sequences to quantify the importance of each item. In this manner, CARD provides the diffusion model with a high-quality guidance signal composed of dynamically re-weighted interaction vectors to enable effective generation. Experiments show our method works well on real-world data without being computationally expensive. Our code is available at https://github.com/yanqilong3321/CARD.
An Iteration-Free Fixed-Point Estimator for Diffusion Inversion
Dec 09, 2025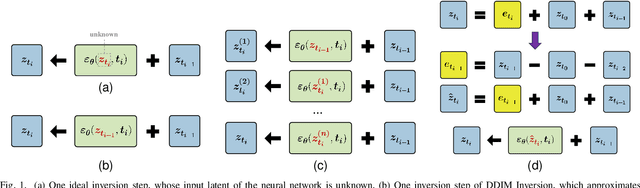



Diffusion inversion aims to recover the initial noise corresponding to a given image such that this noise can reconstruct the original image through the denoising diffusion process. The key component of diffusion inversion is to minimize errors at each inversion step, thereby mitigating cumulative inaccuracies. Recently, fixed-point iteration has emerged as a widely adopted approach to minimize reconstruction errors at each inversion step. However, it suffers from high computational costs due to its iterative nature and the complexity of hyperparameter selection. To address these issues, we propose an iteration-free fixed-point estimator for diffusion inversion. First, we derive an explicit expression of the fixed point from an ideal inversion step. Unfortunately, it inherently contains an unknown data prediction error. Building upon this, we introduce the error approximation, which uses the calculable error from the previous inversion step to approximate the unknown error at the current inversion step. This yields a calculable, approximate expression for the fixed point, which is an unbiased estimator characterized by low variance, as shown by our theoretical analysis. We evaluate reconstruction performance on two text-image datasets, NOCAPS and MS-COCO. Compared to DDIM inversion and other inversion methods based on the fixed-point iteration, our method achieves consistent and superior performance in reconstruction tasks without additional iterations or training.
CoS: Towards Optimal Event Scheduling via Chain-of-Scheduling
Nov 17, 2025Recommending event schedules is a key issue in Event-based Social Networks (EBSNs) in order to maintain user activity. An effective recommendation is required to maximize the user's preference, subjecting to both time and geographical constraints. Existing methods face an inherent trade-off among efficiency, effectiveness, and generalization, due to the NP-hard nature of the problem. This paper proposes the Chain-of-Scheduling (CoS) framework, which activates the event scheduling capability of Large Language Models (LLMs) through a guided, efficient scheduling process. CoS enhances LLM by formulating the schedule task into three atomic stages, i.e., exploration, verification and integration. Then we enable the LLMs to generate CoS autonomously via Knowledge Distillation (KD). Experimental results show that CoS achieves near-theoretical optimal effectiveness with high efficiency on three real-world datasets in a interpretable manner. Moreover, it demonstrates strong zero-shot learning ability on out-of-domain data.
System of Agentic AI for the Discovery of Metal-Organic Frameworks
Apr 18, 2025Generative models and machine learning promise accelerated material discovery in MOFs for CO2 capture and water harvesting but face significant challenges navigating vast chemical spaces while ensuring synthetizability. Here, we present MOFGen, a system of Agentic AI comprising interconnected agents: a large language model that proposes novel MOF compositions, a diffusion model that generates crystal structures, quantum mechanical agents that optimize and filter candidates, and synthetic-feasibility agents guided by expert rules and machine learning. Trained on all experimentally reported MOFs and computational databases, MOFGen generated hundreds of thousands of novel MOF structures and synthesizable organic linkers. Our methodology was validated through high-throughput experiments and the successful synthesis of five "AI-dreamt" MOFs, representing a major step toward automated synthesizable material discovery.
A Pilot Empirical Study on When and How to Use Knowledge Graphs as Retrieval Augmented Generation
Feb 28, 2025The integration of Knowledge Graphs (KGs) into the Retrieval Augmented Generation (RAG) framework has attracted significant interest, with early studies showing promise in mitigating hallucinations and improving model accuracy. However, a systematic understanding and comparative analysis of the rapidly emerging KG-RAG methods are still lacking. This paper seeks to lay the foundation for systematically answering the question of when and how to use KG-RAG by analyzing their performance in various application scenarios associated with different technical configurations. After outlining the mind map using KG-RAG framework and summarizing its popular pipeline, we conduct a pilot empirical study of KG-RAG works to reimplement and evaluate 6 KG-RAG methods across 7 datasets in diverse scenarios, analyzing the impact of 9 KG-RAG configurations in combination with 17 LLMs. Our results underscore the critical role of appropriate application conditions and optimal configurations of KG-RAG components.
Detecting Emotional Incongruity of Sarcasm by Commonsense Reasoning
Dec 17, 2024This paper focuses on sarcasm detection, which aims to identify whether given statements convey criticism, mockery, or other negative sentiment opposite to the literal meaning. To detect sarcasm, humans often require a comprehensive understanding of the semantics in the statement and even resort to external commonsense to infer the fine-grained incongruity. However, existing methods lack commonsense inferential ability when they face complex real-world scenarios, leading to unsatisfactory performance. To address this problem, we propose a novel framework for sarcasm detection, which conducts incongruity reasoning based on commonsense augmentation, called EICR. Concretely, we first employ retrieval-augmented large language models to supplement the missing but indispensable commonsense background knowledge. To capture complex contextual associations, we construct a dependency graph and obtain the optimized topology via graph refinement. We further introduce an adaptive reasoning skeleton that integrates prior rules to extract sentiment-inconsistent subgraphs explicitly. To eliminate the possible spurious relations between words and labels, we employ adversarial contrastive learning to enhance the robustness of the detector. Experiments conducted on five datasets demonstrate the effectiveness of EICR.
Improving Multi-Subject Consistency in Open-Domain Image Generation with Isolation and Reposition Attention
Nov 28, 2024



Training-free diffusion models have achieved remarkable progress in generating multi-subject consistent images within open-domain scenarios. The key idea of these methods is to incorporate reference subject information within the attention layer. However, existing methods still obtain suboptimal performance when handling numerous subjects. This paper reveals the two primary issues contributing to this deficiency. Firstly, there is undesired interference among different subjects within the target image. Secondly, tokens tend to reference nearby tokens, which reduces the effectiveness of the attention mechanism when there is a significant positional difference between subjects in reference and target images. To address these challenges, we propose a training-free diffusion model with Isolation and Reposition Attention, named IR-Diffusion. Specifically, Isolation Attention ensures that multiple subjects in the target image do not reference each other, effectively eliminating the subject fusion. On the other hand, Reposition Attention involves scaling and repositioning subjects in both reference and target images to the same position within the images. This ensures that subjects in the target image can better reference those in the reference image, thereby maintaining better consistency. Extensive experiments demonstrate that the proposed methods significantly enhance multi-subject consistency, outperforming all existing methods in open-domain scenarios.
CoRe: Context-Regularized Text Embedding Learning for Text-to-Image Personalization
Aug 28, 2024
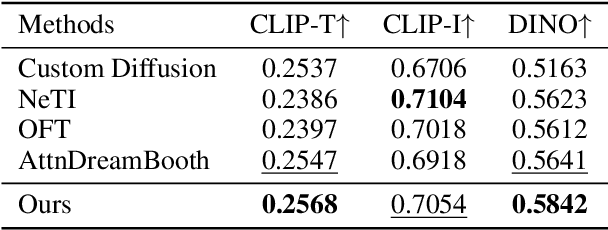
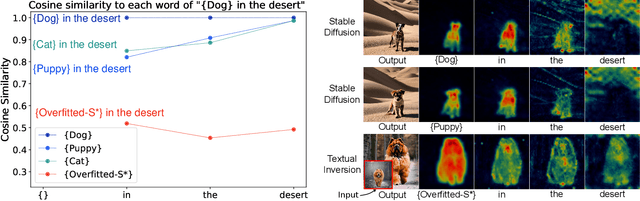
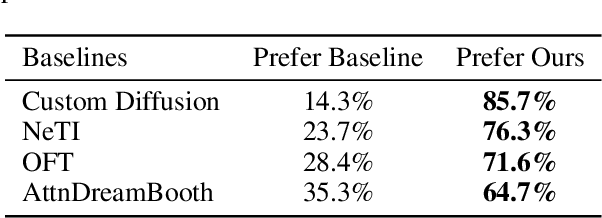
Recent advances in text-to-image personalization have enabled high-quality and controllable image synthesis for user-provided concepts. However, existing methods still struggle to balance identity preservation with text alignment. Our approach is based on the fact that generating prompt-aligned images requires a precise semantic understanding of the prompt, which involves accurately processing the interactions between the new concept and its surrounding context tokens within the CLIP text encoder. To address this, we aim to embed the new concept properly into the input embedding space of the text encoder, allowing for seamless integration with existing tokens. We introduce Context Regularization (CoRe), which enhances the learning of the new concept's text embedding by regularizing its context tokens in the prompt. This is based on the insight that appropriate output vectors of the text encoder for the context tokens can only be achieved if the new concept's text embedding is correctly learned. CoRe can be applied to arbitrary prompts without requiring the generation of corresponding images, thus improving the generalization of the learned text embedding. Additionally, CoRe can serve as a test-time optimization technique to further enhance the generations for specific prompts. Comprehensive experiments demonstrate that our method outperforms several baseline methods in both identity preservation and text alignment. Code will be made publicly available.
DreamStory: Open-Domain Story Visualization by LLM-Guided Multi-Subject Consistent Diffusion
Jul 17, 2024
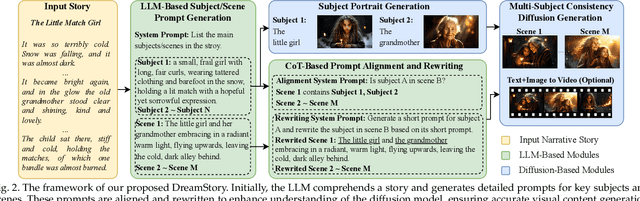
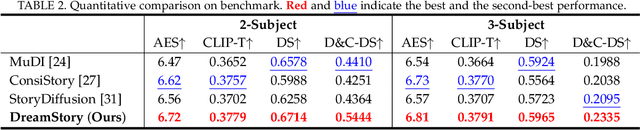
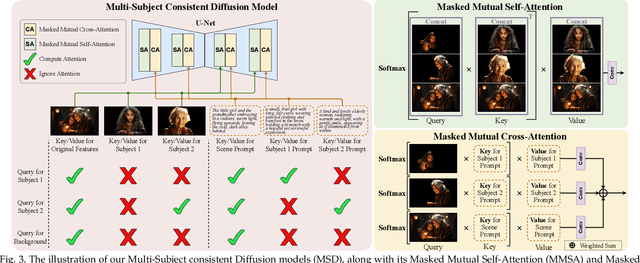
Story visualization aims to create visually compelling images or videos corresponding to textual narratives. Despite recent advances in diffusion models yielding promising results, existing methods still struggle to create a coherent sequence of subject-consistent frames based solely on a story. To this end, we propose DreamStory, an automatic open-domain story visualization framework by leveraging the LLMs and a novel multi-subject consistent diffusion model. DreamStory consists of (1) an LLM acting as a story director and (2) an innovative Multi-Subject consistent Diffusion model (MSD) for generating consistent multi-subject across the images. First, DreamStory employs the LLM to generate descriptive prompts for subjects and scenes aligned with the story, annotating each scene's subjects for subsequent subject-consistent generation. Second, DreamStory utilizes these detailed subject descriptions to create portraits of the subjects, with these portraits and their corresponding textual information serving as multimodal anchors (guidance). Finally, the MSD uses these multimodal anchors to generate story scenes with consistent multi-subject. Specifically, the MSD includes Masked Mutual Self-Attention (MMSA) and Masked Mutual Cross-Attention (MMCA) modules. MMSA and MMCA modules ensure appearance and semantic consistency with reference images and text, respectively. Both modules employ masking mechanisms to prevent subject blending. To validate our approach and promote progress in story visualization, we established a benchmark, DS-500, which can assess the overall performance of the story visualization framework, subject-identification accuracy, and the consistency of the generation model. Extensive experiments validate the effectiveness of DreamStory in both subjective and objective evaluations. Please visit our project homepage at https://dream-xyz.github.io/dreamstory.
Cross-domain-aware Worker Selection with Training for Crowdsourced Annotation
Jun 11, 2024



Annotation through crowdsourcing draws incremental attention, which relies on an effective selection scheme given a pool of workers. Existing methods propose to select workers based on their performance on tasks with ground truth, while two important points are missed. 1) The historical performances of workers in other tasks. In real-world scenarios, workers need to solve a new task whose correlation with previous tasks is not well-known before the training, which is called cross-domain. 2) The dynamic worker performance as workers will learn from the ground truth. In this paper, we consider both factors in designing an allocation scheme named cross-domain-aware worker selection with training approach. Our approach proposes two estimation modules to both statistically analyze the cross-domain correlation and simulate the learning gain of workers dynamically. A framework with a theoretical analysis of the worker elimination process is given. To validate the effectiveness of our methods, we collect two novel real-world datasets and generate synthetic datasets. The experiment results show that our method outperforms the baselines on both real-world and synthetic datasets.