 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing
Mar 15, 2025

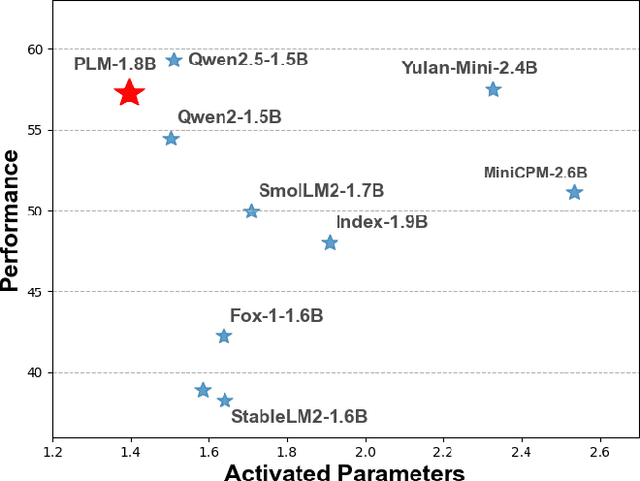

While scaling laws have been continuously validated in large language models (LLMs) with increasing model parameters, the inherent tension between the inference demands of LLMs and the limited resources of edge devices poses a critical challenge to the development of edge intelligence. Recently, numerous small language models have emerged, aiming to distill the capabilities of LLMs into smaller footprints. However, these models often retain the fundamental architectural principles of their larger counterparts, still imposing considerable strain on the storage and bandwidth capacities of edge devices. In this paper, we introduce the PLM, a Peripheral Language Model, developed through a co-design process that jointly optimizes model architecture and edge system constraints. The PLM utilizes a Multi-head Latent Attention mechanism and employs the squared ReLU activation function to encourage sparsity, thereby reducing peak memory footprint during inference. During training, we collect and reorganize open-source datasets, implement a multi-phase training strategy, and empirically investigate the Warmup-Stable-Decay-Constant (WSDC) learning rate scheduler. Additionally, we incorporate Reinforcement Learning from Human Feedback (RLHF) by adopting the ARIES preference learning approach. Following a two-phase SFT process, this method yields performance gains of 2% in general tasks, 9% in the GSM8K task, and 11% in coding tasks. In addition to its novel architecture, evaluation results demonstrate that PLM outperforms existing small language models trained on publicly available data while maintaining the lowest number of activated parameters. Furthermore, deployment across various edge devices, including consumer-grade GPUs, mobile phones, and Raspberry Pis, validates PLM's suitability for peripheral applications. The PLM series models are publicly available at https://github.com/plm-team/PLM.
Activation-aware Probe-Query: Effective Key-Value Retrieval for Long-Context LLMs Inference
Feb 19, 2025Recent advances in large language models (LLMs) have showcased exceptional performance in long-context tasks, while facing significant inference efficiency challenges with limited GPU memory. Existing solutions first proposed the sliding-window approach to accumulate a set of historical \textbf{key-value} (KV) pairs for reuse, then further improvements selectively retain its subsets at each step. However, due to the sparse attention distribution across a long context, it is hard to identify and recall relevant KV pairs, as the attention is distracted by massive candidate pairs. Additionally, we found it promising to select representative tokens as probe-Query in each sliding window to effectively represent the entire context, which is an approach overlooked by existing methods. Thus, we propose \textbf{ActQKV}, a training-free, \textbf{Act}ivation-aware approach that dynamically determines probe-\textbf{Q}uery and leverages it to retrieve the relevant \textbf{KV} pairs for inference. Specifically, ActQKV monitors a token-level indicator, Activation Bias, within each context window, enabling the proper construction of probe-Query for retrieval at pre-filling stage. To accurately recall the relevant KV pairs and minimize the irrelevant ones, we design a dynamic KV cut-off mechanism guided by information density across layers at the decoding stage. Experiments on the Long-Bench and $\infty$ Benchmarks demonstrate its state-of-the-art performance with competitive inference quality and resource efficiency.
Computation-friendly Graph Neural Network Design by Accumulating Knowledge on Large Language Models
Aug 13, 2024



Graph Neural Networks (GNNs), like other neural networks, have shown remarkable success but are hampered by the complexity of their architecture designs, which heavily depend on specific data and tasks. Traditionally, designing proper architectures involves trial and error, which requires intensive manual effort to optimize various components. To reduce human workload, researchers try to develop automated algorithms to design GNNs. However, both experts and automated algorithms suffer from two major issues in designing GNNs: 1) the substantial computational resources expended in repeatedly trying candidate GNN architectures until a feasible design is achieved, and 2) the intricate and prolonged processes required for humans or algorithms to accumulate knowledge of the interrelationship between graphs, GNNs, and performance. To further enhance the automation of GNN architecture design, we propose a computation-friendly way to empower Large Language Models (LLMs) with specialized knowledge in designing GNNs, thereby drastically shortening the computational overhead and development cycle of designing GNN architectures. Our framework begins by establishing a knowledge retrieval pipeline that comprehends the intercorrelations between graphs, GNNs, and performance. This pipeline converts past model design experiences into structured knowledge for LLM reference, allowing it to quickly suggest initial model proposals. Subsequently, we introduce a knowledge-driven search strategy that emulates the exploration-exploitation process of human experts, enabling quick refinement of initial proposals within a promising scope. Extensive experiments demonstrate that our framework can efficiently deliver promising (e.g., Top-5.77%) initial model proposals for unseen datasets within seconds and without any prior training and achieve outstanding search performance in a few iterations.
Cross-domain-aware Worker Selection with Training for Crowdsourced Annotation
Jun 11, 2024



Annotation through crowdsourcing draws incremental attention, which relies on an effective selection scheme given a pool of workers. Existing methods propose to select workers based on their performance on tasks with ground truth, while two important points are missed. 1) The historical performances of workers in other tasks. In real-world scenarios, workers need to solve a new task whose correlation with previous tasks is not well-known before the training, which is called cross-domain. 2) The dynamic worker performance as workers will learn from the ground truth. In this paper, we consider both factors in designing an allocation scheme named cross-domain-aware worker selection with training approach. Our approach proposes two estimation modules to both statistically analyze the cross-domain correlation and simulate the learning gain of workers dynamically. A framework with a theoretical analysis of the worker elimination process is given. To validate the effectiveness of our methods, we collect two novel real-world datasets and generate synthetic datasets. The experiment results show that our method outperforms the baselines on both real-world and synthetic datasets.
Emergence Learning: A Rising Direction from Emergent Abilities and a Monosemanticity-Based Study
Dec 17, 2023In the past 20 years, artificial neural networks have become dominant in various areas, continually growing in scale. However, the current analysis of large models has mainly focused on functionality, overlooking the influence of scale differences on their properties. To address this, we propose the concept of Emergence Learning, which emphasizes the significance of scale. By studying models of different scales, we have identified a key factor in achieving higher performance in large models: the decrease of monosemantic neurons. Building on this insight, we propose a proactive approach to inhibit monosemanticity for improved performance. Our solution involves a two-phase process that includes monosemantic neuron detection and inhibition, supported by theoretical analysis. Experimental results on various tasks and neural networks demonstrate the effectiveness of our proposed method. Following the idea of Emergence Learning, though drawing inspiration from scaling phenomena, the applicability of our method is not restricted to large scale alone. Therefore, the experiment is self-contained. However, extending this research to very large-scale datasets is appealing yet impossible for research departments due to limited resources. We are delighted to share the first co-authorship and eagerly await collaboration from any AI company before submission.