 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputation-friendly Graph Neural Network Design by Accumulating Knowledge on Large Language Models
Aug 13, 2024



Graph Neural Networks (GNNs), like other neural networks, have shown remarkable success but are hampered by the complexity of their architecture designs, which heavily depend on specific data and tasks. Traditionally, designing proper architectures involves trial and error, which requires intensive manual effort to optimize various components. To reduce human workload, researchers try to develop automated algorithms to design GNNs. However, both experts and automated algorithms suffer from two major issues in designing GNNs: 1) the substantial computational resources expended in repeatedly trying candidate GNN architectures until a feasible design is achieved, and 2) the intricate and prolonged processes required for humans or algorithms to accumulate knowledge of the interrelationship between graphs, GNNs, and performance. To further enhance the automation of GNN architecture design, we propose a computation-friendly way to empower Large Language Models (LLMs) with specialized knowledge in designing GNNs, thereby drastically shortening the computational overhead and development cycle of designing GNN architectures. Our framework begins by establishing a knowledge retrieval pipeline that comprehends the intercorrelations between graphs, GNNs, and performance. This pipeline converts past model design experiences into structured knowledge for LLM reference, allowing it to quickly suggest initial model proposals. Subsequently, we introduce a knowledge-driven search strategy that emulates the exploration-exploitation process of human experts, enabling quick refinement of initial proposals within a promising scope. Extensive experiments demonstrate that our framework can efficiently deliver promising (e.g., Top-5.77%) initial model proposals for unseen datasets within seconds and without any prior training and achieve outstanding search performance in a few iterations.
Search to Fine-tune Pre-trained Graph Neural Networks for Graph-level Tasks
Aug 14, 2023Recently, graph neural networks (GNNs) have shown its unprecedented success in many graph-related tasks. However, GNNs face the label scarcity issue as other neural networks do. Thus, recent efforts try to pre-train GNNs on a large-scale unlabeled graph and adapt the knowledge from the unlabeled graph to the target downstream task. The adaptation is generally achieved by fine-tuning the pre-trained GNNs with a limited number of labeled data. Despite the importance of fine-tuning, current GNNs pre-training works often ignore designing a good fine-tuning strategy to better leverage transferred knowledge and improve the performance on downstream tasks. Only few works start to investigate a better fine-tuning strategy for pre-trained GNNs. But their designs either have strong assumptions or overlook the data-aware issue for various downstream datasets. Therefore, we aim to design a better fine-tuning strategy for pre-trained GNNs to improve the model performance in this paper. Given a pre-trained GNN, we propose to search to fine-tune pre-trained graph neural networks for graph-level tasks (S2PGNN), which adaptively design a suitable fine-tuning framework for the given labeled data on the downstream task. To ensure the improvement brought by searching fine-tuning strategy, we carefully summarize a proper search space of fine-tuning framework that is suitable for GNNs. The empirical studies show that S2PGNN can be implemented on the top of 10 famous pre-trained GNNs and consistently improve their performance. Besides, S2PGNN achieves better performance than existing fine-tuning strategies within and outside the GNN area. Our code is publicly available at \url{https://anonymous.4open.science/r/code_icde2024-A9CB/}.
AutoGEL: An Automated Graph Neural Network with Explicit Link Information
Dec 02, 2021


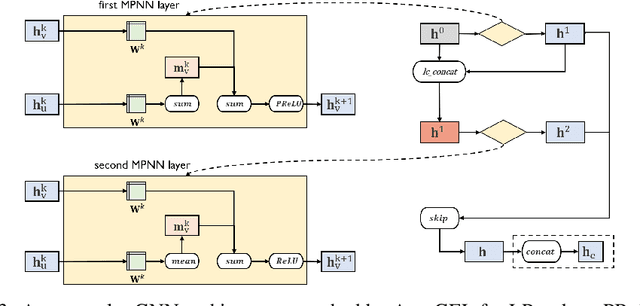
Recently, Graph Neural Networks (GNNs) have gained popularity in a variety of real-world scenarios. Despite the great success, the architecture design of GNNs heavily relies on manual labor. Thus, automated graph neural network (AutoGNN) has attracted interest and attention from the research community, which makes significant performance improvements in recent years. However, existing AutoGNN works mainly adopt an implicit way to model and leverage the link information in the graphs, which is not well regularized to the link prediction task on graphs, and limits the performance of AutoGNN for other graph tasks. In this paper, we present a novel AutoGNN work that explicitly models the link information, abbreviated to AutoGEL. In such a way, AutoGEL can handle the link prediction task and improve the performance of AutoGNNs on the node classification and graph classification task. Specifically, AutoGEL proposes a novel search space containing various design dimensions at both intra-layer and inter-layer designs and adopts a more robust differentiable search algorithm to further improve efficiency and effectiveness. Experimental results on benchmark data sets demonstrate the superiority of AutoGEL on several tasks.