 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStaying in the Sweet Spot: Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding
Sep 08, 2025Reinforcement learning with verifiable rewards (RLVR) has achieved remarkable success in enhancing the reasoning capabilities of large language models (LLMs). However, existing RLVR methods often suffer from exploration inefficiency due to mismatches between the training data's difficulty and the model's capability. LLMs fail to discover viable reasoning paths when problems are overly difficult, while learning little new capability when problems are too simple. In this work, we formalize the impact of problem difficulty by quantifying the relationship between loss descent speed and rollout accuracy. Building on this analysis, we propose SEELE, a novel supervision-aided RLVR framework that dynamically adjusts problem difficulty to stay within the high-efficiency region. SEELE augments each training sample by appending a hint (part of a full solution) after the original problem. Unlike previous hint-based approaches, SEELE deliberately and adaptively adjusts the hint length for each problem to achieve an optimal difficulty. To determine the optimal hint length, SEELE employs a multi-round rollout sampling strategy. In each round, it fits an item response theory model to the accuracy-hint pairs collected in preceding rounds to predict the required hint length for the next round. This instance-level, real-time difficulty adjustment aligns problem difficulty with the evolving model capability, thereby improving exploration efficiency. Experimental results show that SEELE outperforms Group Relative Policy Optimization (GRPO) and Supervised Fine-tuning (SFT) by +11.8 and +10.5 points, respectively, and surpasses the best previous supervision-aided approach by +3.6 points on average across six math reasoning benchmarks.
Computational Efficient Informative Nonignorable Matrix Completion: A Row- and Column-Wise Matrix U-Statistic Pseudo-Likelihood Approach
Apr 05, 2025In this study, we establish a unified framework to deal with the high dimensional matrix completion problem under flexible nonignorable missing mechanisms. Although the matrix completion problem has attracted much attention over the years, there are very sparse works that consider the nonignorable missing mechanism. To address this problem, we derive a row- and column-wise matrix U-statistics type loss function, with the nuclear norm for regularization. A singular value proximal gradient algorithm is developed to solve the proposed optimization problem. We prove the non-asymptotic upper bound of the estimation error's Frobenius norm and show the performance of our method through numerical simulations and real data analysis.
PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing
Mar 15, 2025

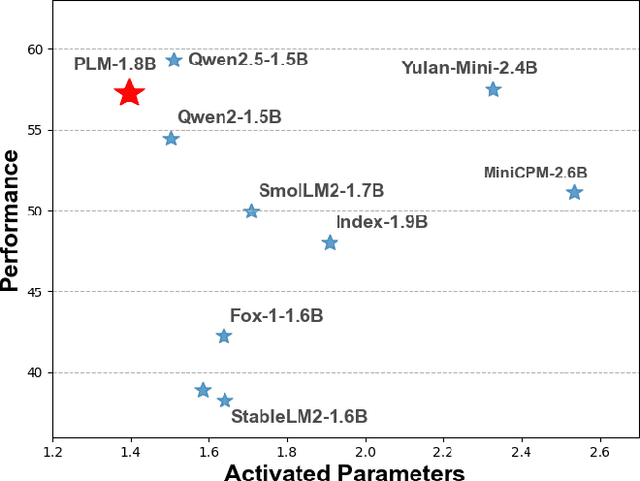

While scaling laws have been continuously validated in large language models (LLMs) with increasing model parameters, the inherent tension between the inference demands of LLMs and the limited resources of edge devices poses a critical challenge to the development of edge intelligence. Recently, numerous small language models have emerged, aiming to distill the capabilities of LLMs into smaller footprints. However, these models often retain the fundamental architectural principles of their larger counterparts, still imposing considerable strain on the storage and bandwidth capacities of edge devices. In this paper, we introduce the PLM, a Peripheral Language Model, developed through a co-design process that jointly optimizes model architecture and edge system constraints. The PLM utilizes a Multi-head Latent Attention mechanism and employs the squared ReLU activation function to encourage sparsity, thereby reducing peak memory footprint during inference. During training, we collect and reorganize open-source datasets, implement a multi-phase training strategy, and empirically investigate the Warmup-Stable-Decay-Constant (WSDC) learning rate scheduler. Additionally, we incorporate Reinforcement Learning from Human Feedback (RLHF) by adopting the ARIES preference learning approach. Following a two-phase SFT process, this method yields performance gains of 2% in general tasks, 9% in the GSM8K task, and 11% in coding tasks. In addition to its novel architecture, evaluation results demonstrate that PLM outperforms existing small language models trained on publicly available data while maintaining the lowest number of activated parameters. Furthermore, deployment across various edge devices, including consumer-grade GPUs, mobile phones, and Raspberry Pis, validates PLM's suitability for peripheral applications. The PLM series models are publicly available at https://github.com/plm-team/PLM.
ARIES: Stimulating Self-Refinement of Large Language Models by Iterative Preference Optimization
Feb 08, 2025A truly intelligent Large Language Model (LLM) should be capable of correcting errors in its responses through external interactions. However, even the most advanced models often face challenges in improving their outputs. In this paper, we explore how to cultivate LLMs with the self-refinement capability through iterative preference training, and how this ability can be leveraged to improve model performance during inference. To this end, we introduce a novel post-training and inference framework, called ARIES: Adaptive Refinement and Iterative Enhancement Structure. This method iteratively performs preference training and self-refinement-based data collection. During training, ARIES strengthen the model's direct question-answering capability while simultaneously unlocking its self-refinement potential. During inference, ARIES harnesses this self-refinement capability to generate a series of progressively refined responses, which are then filtered using either the Reward Model Scoring or a simple yet effective Rule-Based Selection mechanism, specifically tailored to our approach, to construct a dataset for the next round of preference training. Experimental results demonstrate the remarkable performance of ARIES. When applied to the Llama-3.1-8B model and under the self-refinement setting, ARIES surpasses powerful models such as GPT-4o, achieving 62.3% length-controlled (LC) and a 63.3% raw win rates on AlpacaEval 2, outperforming Iterative DPO by 27.8% and 35.5% respectively, as well as a 50.3% win rate on Arena-Hard, surpassing Iterative DPO by 26.6%. Furthermore, ARIES consistently enhances performance on mathematical reasoning tasks like GSM8K and MATH.
Token-level Direct Preference Optimization
Apr 18, 2024Fine-tuning pre-trained Large Language Models (LLMs) is essential to align them with human values and intentions. This process often utilizes methods like pairwise comparisons and KL divergence against a reference LLM, focusing on the evaluation of full answers generated by the models. However, the generation of these responses occurs in a token level, following a sequential, auto-regressive fashion. In this paper, we introduce Token-level Direct Preference Optimization (TDPO), a novel approach to align LLMs with human preferences by optimizing policy at the token level. Unlike previous methods, which face challenges in divergence efficiency, TDPO incorporates forward KL divergence constraints for each token, improving alignment and diversity. Utilizing the Bradley-Terry model for a token-based reward system, TDPO enhances the regulation of KL divergence, while preserving simplicity without the need for explicit reward modeling. Experimental results across various text tasks demonstrate TDPO's superior performance in balancing alignment with generation diversity. Notably, fine-tuning with TDPO strikes a better balance than DPO in the controlled sentiment generation and single-turn dialogue datasets, and significantly improves the quality of generated responses compared to both DPO and PPO-based RLHF methods. Our code is open-sourced at https://github.com/Vance0124/Token-level-Direct-Preference-Optimization.