 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTER: Agentic Scaling with Tool-integrated Extended Reasoning
Feb 01, 2026Reinforcement learning (RL) has emerged as a dominant paradigm for eliciting long-horizon reasoning in Large Language Models (LLMs). However, scaling Tool-Integrated Reasoning (TIR) via RL remains challenging due to interaction collapse: a pathological state where models fail to sustain multi-turn tool usage, instead degenerating into heavy internal reasoning with only trivial, post-hoc code verification. We systematically study three questions: (i) how cold-start SFT induces an agentic, tool-using behavioral prior, (ii) how the interaction density of cold-start trajectories shapes exploration and downstream RL outcomes, and (iii) how the RL interaction budget affects learning dynamics and generalization under varying inference-time budgets. We then introduce ASTER (Agentic Scaling with Tool-integrated Extended Reasoning), a framework that circumvents this collapse through a targeted cold-start strategy prioritizing interaction-dense trajectories. We find that a small expert cold-start set of just 4K interaction-dense trajectories yields the strongest downstream performance, establishing a robust prior that enables superior exploration during extended RL training. Extensive evaluations demonstrate that ASTER-4B achieves state-of-the-art results on competitive mathematical benchmarks, reaching 90.0% on AIME 2025, surpassing leading frontier open-source models, including DeepSeek-V3.2-Exp.
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
May 29, 2025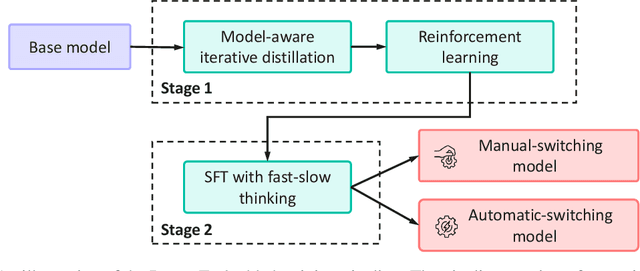

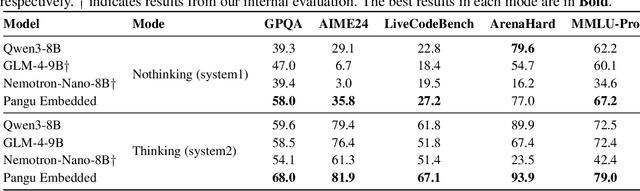
This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
ARIES: Stimulating Self-Refinement of Large Language Models by Iterative Preference Optimization
Feb 08, 2025A truly intelligent Large Language Model (LLM) should be capable of correcting errors in its responses through external interactions. However, even the most advanced models often face challenges in improving their outputs. In this paper, we explore how to cultivate LLMs with the self-refinement capability through iterative preference training, and how this ability can be leveraged to improve model performance during inference. To this end, we introduce a novel post-training and inference framework, called ARIES: Adaptive Refinement and Iterative Enhancement Structure. This method iteratively performs preference training and self-refinement-based data collection. During training, ARIES strengthen the model's direct question-answering capability while simultaneously unlocking its self-refinement potential. During inference, ARIES harnesses this self-refinement capability to generate a series of progressively refined responses, which are then filtered using either the Reward Model Scoring or a simple yet effective Rule-Based Selection mechanism, specifically tailored to our approach, to construct a dataset for the next round of preference training. Experimental results demonstrate the remarkable performance of ARIES. When applied to the Llama-3.1-8B model and under the self-refinement setting, ARIES surpasses powerful models such as GPT-4o, achieving 62.3% length-controlled (LC) and a 63.3% raw win rates on AlpacaEval 2, outperforming Iterative DPO by 27.8% and 35.5% respectively, as well as a 50.3% win rate on Arena-Hard, surpassing Iterative DPO by 26.6%. Furthermore, ARIES consistently enhances performance on mathematical reasoning tasks like GSM8K and MATH.
Surgical tool classification and localization: results and methods from the MICCAI 2022 SurgToolLoc challenge
May 11, 2023



The ability to automatically detect and track surgical instruments in endoscopic videos can enable transformational interventions. Assessing surgical performance and efficiency, identifying skilled tool use and choreography, and planning operational and logistical aspects of OR resources are just a few of the applications that could benefit. Unfortunately, obtaining the annotations needed to train machine learning models to identify and localize surgical tools is a difficult task. Annotating bounding boxes frame-by-frame is tedious and time-consuming, yet large amounts of data with a wide variety of surgical tools and surgeries must be captured for robust training. Moreover, ongoing annotator training is needed to stay up to date with surgical instrument innovation. In robotic-assisted surgery, however, potentially informative data like timestamps of instrument installation and removal can be programmatically harvested. The ability to rely on tool installation data alone would significantly reduce the workload to train robust tool-tracking models. With this motivation in mind we invited the surgical data science community to participate in the challenge, SurgToolLoc 2022. The goal was to leverage tool presence data as weak labels for machine learning models trained to detect tools and localize them in video frames with bounding boxes. We present the results of this challenge along with many of the team's efforts. We conclude by discussing these results in the broader context of machine learning and surgical data science. The training data used for this challenge consisting of 24,695 video clips with tool presence labels is also being released publicly and can be accessed at https://console.cloud.google.com/storage/browser/isi-surgtoolloc-2022.