 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Preferences Are Created Equal: Stability-Aware and Gradient-Efficient Alignment for Reasoning Models
Feb 01, 2026Preference-based alignment is pivotal for training large reasoning models; however, standard methods like Direct Preference Optimization (DPO) typically treat all preference pairs uniformly, overlooking the evolving utility of training instances. This static approach often leads to inefficient or unstable optimization, as it wastes computation on trivial pairs with negligible gradients and suffers from noise induced by samples near uncertain decision boundaries. Facing these challenges, we propose SAGE (Stability-Aware Gradient Efficiency), a dynamic framework designed to enhance alignment reliability by maximizing the Signal-to-Noise Ratio of policy updates. Concretely, SAGE integrates a coarse-grained curriculum mechanism that refreshes candidate pools based on model competence with a fine-grained, stability-aware scoring function that prioritizes informative, confident errors while filtering out unstable samples. Experiments on multiple mathematical reasoning benchmarks demonstrate that SAGE significantly accelerates convergence and outperforms static baselines, highlighting the critical role of policy-aware, stability-conscious data selection in reasoning alignment.
MatchTIR: Fine-Grained Supervision for Tool-Integrated Reasoning via Bipartite Matching
Jan 15, 2026Tool-Integrated Reasoning (TIR) empowers large language models (LLMs) to tackle complex tasks by interleaving reasoning steps with external tool interactions. However, existing reinforcement learning methods typically rely on outcome- or trajectory-level rewards, assigning uniform advantages to all steps within a trajectory. This coarse-grained credit assignment fails to distinguish effective tool calls from redundant or erroneous ones, particularly in long-horizon multi-turn scenarios. To address this, we propose MatchTIR, a framework that introduces fine-grained supervision via bipartite matching-based turn-level reward assignment and dual-level advantage estimation. Specifically, we formulate credit assignment as a bipartite matching problem between predicted and ground-truth traces, utilizing two assignment strategies to derive dense turn-level rewards. Furthermore, to balance local step precision with global task success, we introduce a dual-level advantage estimation scheme that integrates turn-level and trajectory-level signals, assigning distinct advantage values to individual interaction turns. Extensive experiments on three benchmarks demonstrate the superiority of MatchTIR. Notably, our 4B model surpasses the majority of 8B competitors, particularly in long-horizon and multi-turn tasks. Our codes are available at https://github.com/quchangle1/MatchTIR.
Efficient Thought Space Exploration through Strategic Intervention
Nov 13, 2025While large language models (LLMs) demonstrate emerging reasoning capabilities, current inference-time expansion methods incur prohibitive computational costs by exhaustive sampling. Through analyzing decoding trajectories, we observe that most next-token predictions align well with the golden output, except for a few critical tokens that lead to deviations. Inspired by this phenomenon, we propose a novel Hint-Practice Reasoning (HPR) framework that operationalizes this insight through two synergistic components: 1) a hinter (powerful LLM) that provides probabilistic guidance at critical decision points, and 2) a practitioner (efficient smaller model) that executes major reasoning steps. The framework's core innovation lies in Distributional Inconsistency Reduction (DIR), a theoretically-grounded metric that dynamically identifies intervention points by quantifying the divergence between practitioner's reasoning trajectory and hinter's expected distribution in a tree-structured probabilistic space. Through iterative tree updates guided by DIR, HPR reweights promising reasoning paths while deprioritizing low-probability branches. Experiments across arithmetic and commonsense reasoning benchmarks demonstrate HPR's state-of-the-art efficiency-accuracy tradeoffs: it achieves comparable performance to self-consistency and MCTS baselines while decoding only 1/5 tokens, and outperforms existing methods by at most 5.1% absolute accuracy while maintaining similar or lower FLOPs.
AdaSwitch: Adaptive Switching Generation for Knowledge Distillation
Oct 09, 2025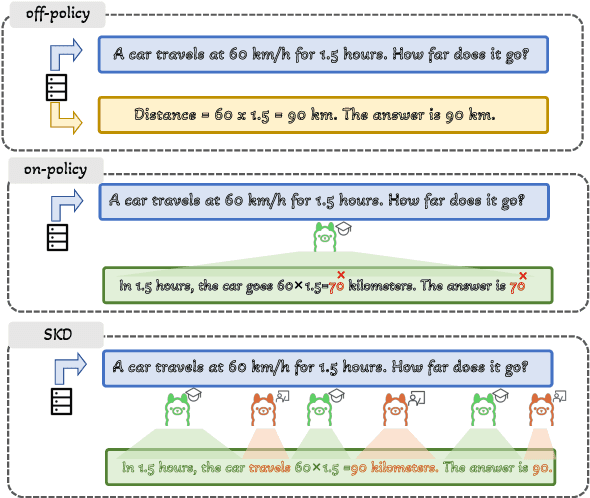
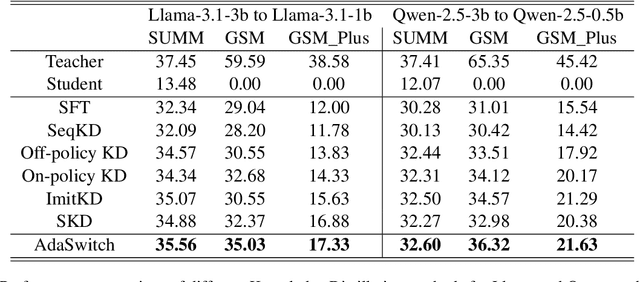
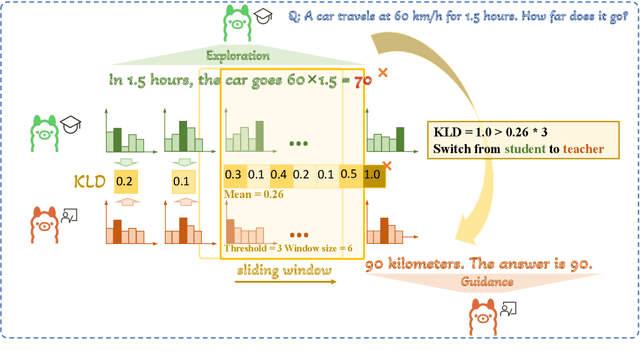
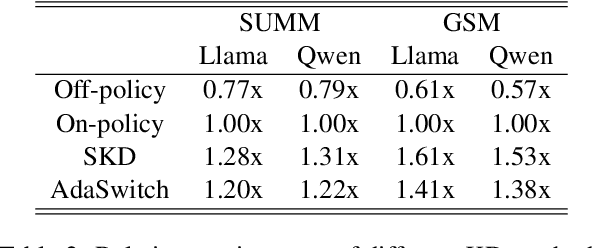
Small language models (SLMs) are crucial for applications with strict latency and computational constraints, yet achieving high performance remains challenging. Knowledge distillation (KD) can transfer capabilities from large teacher models, but existing methods involve trade-offs: off-policy distillation provides high-quality supervision but introduces a training-inference mismatch, while on-policy approaches maintain consistency but rely on low-quality student outputs. To address these issues, we propose AdaSwitch, a novel approach that dynamically combines on-policy and off-policy generation at the token level. AdaSwitch allows the student to first explore its own predictions and then selectively integrate teacher guidance based on real-time quality assessment. This approach simultaneously preserves consistency and maintains supervision quality. Experiments on three datasets with two teacher-student LLM pairs demonstrate that AdaSwitch consistently improves accuracy, offering a practical and effective method for distilling SLMs with acceptable additional overhead.
Staying in the Sweet Spot: Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding
Sep 08, 2025Reinforcement learning with verifiable rewards (RLVR) has achieved remarkable success in enhancing the reasoning capabilities of large language models (LLMs). However, existing RLVR methods often suffer from exploration inefficiency due to mismatches between the training data's difficulty and the model's capability. LLMs fail to discover viable reasoning paths when problems are overly difficult, while learning little new capability when problems are too simple. In this work, we formalize the impact of problem difficulty by quantifying the relationship between loss descent speed and rollout accuracy. Building on this analysis, we propose SEELE, a novel supervision-aided RLVR framework that dynamically adjusts problem difficulty to stay within the high-efficiency region. SEELE augments each training sample by appending a hint (part of a full solution) after the original problem. Unlike previous hint-based approaches, SEELE deliberately and adaptively adjusts the hint length for each problem to achieve an optimal difficulty. To determine the optimal hint length, SEELE employs a multi-round rollout sampling strategy. In each round, it fits an item response theory model to the accuracy-hint pairs collected in preceding rounds to predict the required hint length for the next round. This instance-level, real-time difficulty adjustment aligns problem difficulty with the evolving model capability, thereby improving exploration efficiency. Experimental results show that SEELE outperforms Group Relative Policy Optimization (GRPO) and Supervised Fine-tuning (SFT) by +11.8 and +10.5 points, respectively, and surpasses the best previous supervision-aided approach by +3.6 points on average across six math reasoning benchmarks.
From Prompting to Alignment: A Generative Framework for Query Recommendation
Apr 14, 2025



In modern search systems, search engines often suggest relevant queries to users through various panels or components, helping refine their information needs. Traditionally, these recommendations heavily rely on historical search logs to build models, which suffer from cold-start or long-tail issues. Furthermore, tasks such as query suggestion, completion or clarification are studied separately by specific design, which lacks generalizability and hinders adaptation to novel applications. Despite recent attempts to explore the use of LLMs for query recommendation, these methods mainly rely on the inherent knowledge of LLMs or external sources like few-shot examples, retrieved documents, or knowledge bases, neglecting the importance of the calibration and alignment with user feedback, thus limiting their practical utility. To address these challenges, we first propose a general Generative Query Recommendation (GQR) framework that aligns LLM-based query generation with user preference. Specifically, we unify diverse query recommendation tasks by a universal prompt framework, leveraging the instruct-following capability of LLMs for effective generation. Secondly, we align LLMs with user feedback via presenting a CTR-alignment framework, which involves training a query-wise CTR predictor as a process reward model and employing list-wise preference alignment to maximize the click probability of the generated query list. Furthermore, recognizing the inconsistency between LLM knowledge and proactive search intents arising from the separation of user-initiated queries from models, we align LLMs with user initiative via retrieving co-occurrence queries as side information when historical logs are available.
PA-RAG: RAG Alignment via Multi-Perspective Preference Optimization
Dec 19, 2024



The emergence of Retrieval-augmented generation (RAG) has alleviated the issues of outdated and hallucinatory content in the generation of large language models (LLMs), yet it still reveals numerous limitations. When a general-purpose LLM serves as the RAG generator, it often suffers from inadequate response informativeness, response robustness, and citation quality. Past approaches to tackle these limitations, either by incorporating additional steps beyond generating responses or optimizing the generator through supervised fine-tuning (SFT), still failed to align with the RAG requirement thoroughly. Consequently, optimizing the RAG generator from multiple preference perspectives while maintaining its end-to-end LLM form remains a challenge. To bridge this gap, we propose Multiple Perspective Preference Alignment for Retrieval-Augmented Generation (PA-RAG), a method for optimizing the generator of RAG systems to align with RAG requirements comprehensively. Specifically, we construct high-quality instruction fine-tuning data and multi-perspective preference data by sampling varied quality responses from the generator across different prompt documents quality scenarios. Subsequently, we optimize the generator using SFT and Direct Preference Optimization (DPO). Extensive experiments conducted on four question-answer datasets across three LLMs demonstrate that PA-RAG can significantly enhance the performance of RAG generators. Our code and datasets are available at https://github.com/wujwyi/PA-RAG.
Cross-model Control: Improving Multiple Large Language Models in One-time Training
Oct 23, 2024



The number of large language models (LLMs) with varying parameter scales and vocabularies is increasing. While they deliver powerful performance, they also face a set of common optimization needs to meet specific requirements or standards, such as instruction following or avoiding the output of sensitive information from the real world. However, how to reuse the fine-tuning outcomes of one model to other models to reduce training costs remains a challenge. To bridge this gap, we introduce Cross-model Control (CMC), a method that improves multiple LLMs in one-time training with a portable tiny language model. Specifically, we have observed that the logit shift before and after fine-tuning is remarkably similar across different models. Based on this insight, we incorporate a tiny language model with a minimal number of parameters. By training alongside a frozen template LLM, the tiny model gains the capability to alter the logits output by the LLMs. To make this tiny language model applicable to models with different vocabularies, we propose a novel token mapping strategy named PM-MinED. We have conducted extensive experiments on instruction tuning and unlearning tasks, demonstrating the effectiveness of CMC. Our code is available at https://github.com/wujwyi/CMC.
AdaSwitch: Adaptive Switching between Small and Large Agents for Effective Cloud-Local Collaborative Learning
Oct 17, 2024



Recent advancements in large language models (LLMs) have been remarkable. Users face a choice between using cloud-based LLMs for generation quality and deploying local-based LLMs for lower computational cost. The former option is typically costly and inefficient, while the latter usually fails to deliver satisfactory performance for reasoning steps requiring deliberate thought processes. In this work, we propose a novel LLM utilization paradigm that facilitates the collaborative operation of large cloud-based LLMs and smaller local-deployed LLMs. Our framework comprises two primary modules: the local agent instantiated with a relatively smaller LLM, handling less complex reasoning steps, and the cloud agent equipped with a larger LLM, managing more intricate reasoning steps. This collaborative processing is enabled through an adaptive mechanism where the local agent introspectively identifies errors and proactively seeks assistance from the cloud agent, thereby effectively integrating the strengths of both locally-deployed and cloud-based LLMs, resulting in significant enhancements in task completion performance and efficiency. We evaluate AdaSwitch across 7 benchmarks, ranging from mathematical reasoning and complex question answering, using various types of LLMs to instantiate the local and cloud agents. The empirical results show that AdaSwitch effectively improves the performance of the local agent, and sometimes achieves competitive results compared to the cloud agent while utilizing much less computational overhead.
From Exploration to Mastery: Enabling LLMs to Master Tools via Self-Driven Interactions
Oct 10, 2024



Tool learning enables Large Language Models (LLMs) to interact with external environments by invoking tools, serving as an effective strategy to mitigate the limitations inherent in their pre-training data. In this process, tool documentation plays a crucial role by providing usage instructions for LLMs, thereby facilitating effective tool utilization. This paper concentrates on the critical challenge of bridging the comprehension gap between LLMs and external tools due to the inadequacies and inaccuracies inherent in existing human-centric tool documentation. We propose a novel framework, DRAFT, aimed at Dynamically Refining tool documentation through the Analysis of Feedback and Trails emanating from LLMs' interactions with external tools. This methodology pivots on an innovative trial-and-error approach, consisting of three distinct learning phases: experience gathering, learning from experience, and documentation rewriting, to iteratively enhance the tool documentation. This process is further optimized by implementing a diversity-promoting exploration strategy to ensure explorative diversity and a tool-adaptive termination mechanism to prevent overfitting while enhancing efficiency. Extensive experiments on multiple datasets demonstrate that DRAFT's iterative, feedback-based refinement significantly ameliorates documentation quality, fostering a deeper comprehension and more effective utilization of tools by LLMs. Notably, our analysis reveals that the tool documentation refined via our approach demonstrates robust cross-model generalization capabilities.