 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJADE: Bridging the Strategic-Operational Gap in Dynamic Agentic RAG
Jan 29, 2026The evolution of Retrieval-Augmented Generation (RAG) has shifted from static retrieval pipelines to dynamic, agentic workflows where a central planner orchestrates multi-turn reasoning. However, existing paradigms face a critical dichotomy: they either optimize modules jointly within rigid, fixed-graph architectures, or empower dynamic planning while treating executors as frozen, black-box tools. We identify that this \textit{decoupled optimization} creates a ``strategic-operational mismatch,'' where sophisticated planning strategies fail to materialize due to unadapted local executors, often leading to negative performance gains despite increased system complexity. In this paper, we propose \textbf{JADE} (\textbf{J}oint \textbf{A}gentic \textbf{D}ynamic \textbf{E}xecution), a unified framework for the joint optimization of planning and execution within dynamic, multi-turn workflows. By modeling the system as a cooperative multi-agent team unified under a single shared backbone, JADE enables end-to-end learning driven by outcome-based rewards. This approach facilitates \textit{co-adaptation}: the planner learns to operate within the capability boundaries of the executors, while the executors evolve to align with high-level strategic intent. Empirical results demonstrate that JADE transforms disjoint modules into a synergistic system, yielding remarkable performance improvements via joint optimization and enabling a flexible balance between efficiency and effectiveness through dynamic workflow orchestration.
Self-Compression of Chain-of-Thought via Multi-Agent Reinforcement Learning
Jan 29, 2026The inference overhead induced by redundant reasoning undermines the interactive experience and severely bottlenecks the deployment of Large Reasoning Models. Existing reinforcement learning (RL)-based solutions tackle this problem by coupling a length penalty with outcome-based rewards. This simplistic reward weighting struggles to reconcile brevity with accuracy, as enforcing brevity may compromise critical reasoning logic. In this work, we address this limitation by proposing a multi-agent RL framework that selectively penalizes redundant chunks, while preserving essential reasoning logic. Our framework, Self-Compression via MARL (SCMA), instantiates redundancy detection and evaluation through two specialized agents: \textbf{a Segmentation Agent} for decomposing the reasoning process into logical chunks, and \textbf{a Scoring Agent} for quantifying the significance of each chunk. The Segmentation and Scoring agents collaboratively define an importance-weighted length penalty during training, incentivizing \textbf{a Reasoning Agent} to prioritize essential logic without introducing inference overhead during deployment. Empirical evaluations across model scales demonstrate that SCMA reduces response length by 11.1\% to 39.0\% while boosting accuracy by 4.33\% to 10.02\%. Furthermore, ablation studies and qualitative analysis validate that the synergistic optimization within the MARL framework fosters emergent behaviors, yielding more powerful LRMs compared to vanilla RL paradigms.
Efficient Thought Space Exploration through Strategic Intervention
Nov 13, 2025While large language models (LLMs) demonstrate emerging reasoning capabilities, current inference-time expansion methods incur prohibitive computational costs by exhaustive sampling. Through analyzing decoding trajectories, we observe that most next-token predictions align well with the golden output, except for a few critical tokens that lead to deviations. Inspired by this phenomenon, we propose a novel Hint-Practice Reasoning (HPR) framework that operationalizes this insight through two synergistic components: 1) a hinter (powerful LLM) that provides probabilistic guidance at critical decision points, and 2) a practitioner (efficient smaller model) that executes major reasoning steps. The framework's core innovation lies in Distributional Inconsistency Reduction (DIR), a theoretically-grounded metric that dynamically identifies intervention points by quantifying the divergence between practitioner's reasoning trajectory and hinter's expected distribution in a tree-structured probabilistic space. Through iterative tree updates guided by DIR, HPR reweights promising reasoning paths while deprioritizing low-probability branches. Experiments across arithmetic and commonsense reasoning benchmarks demonstrate HPR's state-of-the-art efficiency-accuracy tradeoffs: it achieves comparable performance to self-consistency and MCTS baselines while decoding only 1/5 tokens, and outperforms existing methods by at most 5.1% absolute accuracy while maintaining similar or lower FLOPs.
AdaSwitch: Adaptive Switching between Small and Large Agents for Effective Cloud-Local Collaborative Learning
Oct 17, 2024



Recent advancements in large language models (LLMs) have been remarkable. Users face a choice between using cloud-based LLMs for generation quality and deploying local-based LLMs for lower computational cost. The former option is typically costly and inefficient, while the latter usually fails to deliver satisfactory performance for reasoning steps requiring deliberate thought processes. In this work, we propose a novel LLM utilization paradigm that facilitates the collaborative operation of large cloud-based LLMs and smaller local-deployed LLMs. Our framework comprises two primary modules: the local agent instantiated with a relatively smaller LLM, handling less complex reasoning steps, and the cloud agent equipped with a larger LLM, managing more intricate reasoning steps. This collaborative processing is enabled through an adaptive mechanism where the local agent introspectively identifies errors and proactively seeks assistance from the cloud agent, thereby effectively integrating the strengths of both locally-deployed and cloud-based LLMs, resulting in significant enhancements in task completion performance and efficiency. We evaluate AdaSwitch across 7 benchmarks, ranging from mathematical reasoning and complex question answering, using various types of LLMs to instantiate the local and cloud agents. The empirical results show that AdaSwitch effectively improves the performance of the local agent, and sometimes achieves competitive results compared to the cloud agent while utilizing much less computational overhead.
From Exploration to Mastery: Enabling LLMs to Master Tools via Self-Driven Interactions
Oct 10, 2024



Tool learning enables Large Language Models (LLMs) to interact with external environments by invoking tools, serving as an effective strategy to mitigate the limitations inherent in their pre-training data. In this process, tool documentation plays a crucial role by providing usage instructions for LLMs, thereby facilitating effective tool utilization. This paper concentrates on the critical challenge of bridging the comprehension gap between LLMs and external tools due to the inadequacies and inaccuracies inherent in existing human-centric tool documentation. We propose a novel framework, DRAFT, aimed at Dynamically Refining tool documentation through the Analysis of Feedback and Trails emanating from LLMs' interactions with external tools. This methodology pivots on an innovative trial-and-error approach, consisting of three distinct learning phases: experience gathering, learning from experience, and documentation rewriting, to iteratively enhance the tool documentation. This process is further optimized by implementing a diversity-promoting exploration strategy to ensure explorative diversity and a tool-adaptive termination mechanism to prevent overfitting while enhancing efficiency. Extensive experiments on multiple datasets demonstrate that DRAFT's iterative, feedback-based refinement significantly ameliorates documentation quality, fostering a deeper comprehension and more effective utilization of tools by LLMs. Notably, our analysis reveals that the tool documentation refined via our approach demonstrates robust cross-model generalization capabilities.
LLMs + Persona-Plug = Personalized LLMs
Sep 18, 2024



Personalization plays a critical role in numerous language tasks and applications, since users with the same requirements may prefer diverse outputs based on their individual interests. This has led to the development of various personalized approaches aimed at adapting large language models (LLMs) to generate customized outputs aligned with user preferences. Some of them involve fine-tuning a unique personalized LLM for each user, which is too expensive for widespread application. Alternative approaches introduce personalization information in a plug-and-play manner by retrieving the user's relevant historical texts as demonstrations. However, this retrieval-based strategy may break the continuity of the user history and fail to capture the user's overall styles and patterns, hence leading to sub-optimal performance. To address these challenges, we propose a novel personalized LLM model, \ours{}. It constructs a user-specific embedding for each individual by modeling all her historical contexts through a lightweight plug-in user embedder module. By attaching this embedding to the task input, LLMs can better understand and capture user habits and preferences, thereby producing more personalized outputs without tuning their own parameters. Extensive experiments on various tasks in the language model personalization (LaMP) benchmark demonstrate that the proposed model significantly outperforms existing personalized LLM approaches.
Tool Learning with Large Language Models: A Survey
May 28, 2024Recently, tool learning with large language models (LLMs) has emerged as a promising paradigm for augmenting the capabilities of LLMs to tackle highly complex problems. Despite growing attention and rapid advancements in this field, the existing literature remains fragmented and lacks systematic organization, posing barriers to entry for newcomers. This gap motivates us to conduct a comprehensive survey of existing works on tool learning with LLMs. In this survey, we focus on reviewing existing literature from the two primary aspects (1) why tool learning is beneficial and (2) how tool learning is implemented, enabling a comprehensive understanding of tool learning with LLMs. We first explore the "why" by reviewing both the benefits of tool integration and the inherent benefits of the tool learning paradigm from six specific aspects. In terms of "how", we systematically review the literature according to a taxonomy of four key stages in the tool learning workflow: task planning, tool selection, tool calling, and response generation. Additionally, we provide a detailed summary of existing benchmarks and evaluation methods, categorizing them according to their relevance to different stages. Finally, we discuss current challenges and outline potential future directions, aiming to inspire both researchers and industrial developers to further explore this emerging and promising area.
COLT: Towards Completeness-Oriented Tool Retrieval for Large Language Models
May 25, 2024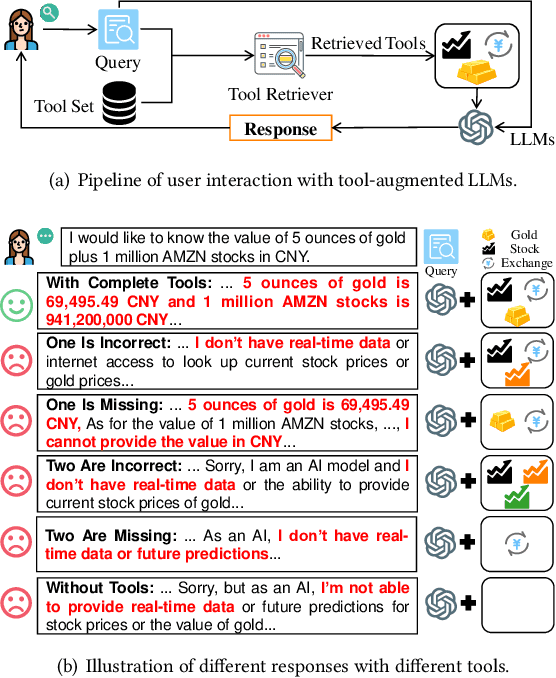
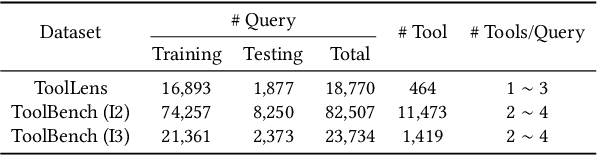
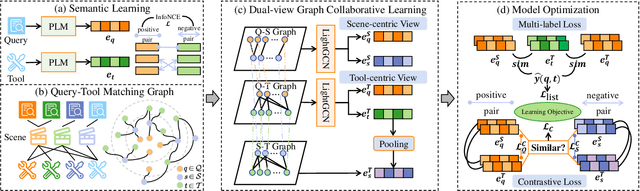

Recently, the integration of external tools with Large Language Models (LLMs) has emerged as a promising approach to overcome the inherent constraints of their pre-training data. However, realworld applications often involve a diverse range of tools, making it infeasible to incorporate all tools directly into LLMs due to constraints on input length and response time. Therefore, to fully exploit the potential of tool-augmented LLMs, it is crucial to develop an effective tool retrieval system. Existing tool retrieval methods techniques mainly rely on semantic matching between user queries and tool descriptions, which often results in the selection of redundant tools. As a result, these methods fail to provide a complete set of diverse tools necessary for addressing the multifaceted problems encountered by LLMs. In this paper, we propose a novel modelagnostic COllaborative Learning-based Tool Retrieval approach, COLT, which captures not only the semantic similarities between user queries and tool descriptions but also takes into account the collaborative information of tools. Specifically, we first fine-tune the PLM-based retrieval models to capture the semantic relationships between queries and tools in the semantic learning stage. Subsequently, we construct three bipartite graphs among queries, scenes, and tools and introduce a dual-view graph collaborative learning framework to capture the intricate collaborative relationships among tools during the collaborative learning stage. Extensive experiments on both the open benchmark and the newly introduced ToolLens dataset show that COLT achieves superior performance. Notably, the performance of BERT-mini (11M) with our proposed model framework outperforms BERT-large (340M), which has 30 times more parameters. Additionally, we plan to publicly release the ToolLens dataset to support further research in tool retrieval.
XL$^2$Bench: A Benchmark for Extremely Long Context Understanding with Long-range Dependencies
Apr 08, 2024Large Language Models (LLMs) have demonstrated remarkable performance across diverse tasks but are constrained by their small context window sizes. Various efforts have been proposed to expand the context window to accommodate even up to 200K input tokens. Meanwhile, building high-quality benchmarks with much longer text lengths and more demanding tasks to provide comprehensive evaluations is of immense practical interest to facilitate long context understanding research of LLMs. However, prior benchmarks create datasets that ostensibly cater to long-text comprehension by expanding the input of traditional tasks, which falls short to exhibit the unique characteristics of long-text understanding, including long dependency tasks and longer text length compatible with modern LLMs' context window size. In this paper, we introduce a benchmark for extremely long context understanding with long-range dependencies, XL$^2$Bench, which includes three scenarios: Fiction Reading, Paper Reading, and Law Reading, and four tasks of increasing complexity: Memory Retrieval, Detailed Understanding, Overall Understanding, and Open-ended Generation, covering 27 subtasks in English and Chinese. It has an average length of 100K+ words (English) and 200K+ characters (Chinese). Evaluating six leading LLMs on XL$^2$Bench, we find that their performance significantly lags behind human levels. Moreover, the observed decline in performance across both the original and enhanced datasets underscores the efficacy of our approach to mitigating data contamination.
Towards Verifiable Text Generation with Evolving Memory and Self-Reflection
Dec 14, 2023Large Language Models (LLMs) face several challenges, including the tendency to produce incorrect outputs, known as hallucination. An effective solution is verifiable text generation, which prompts LLMs to generate content with citations for accuracy verification. However, verifiable text generation is non-trivial due to the focus-shifting phenomenon, the dilemma between the precision and scope in document retrieval, and the intricate reasoning required to discern the relationship between the claim and citations. In this paper, we present VTG, an innovative approach for Verifiable Text Generation with evolving memory and self-reflection. VTG maintains evolving long short-term memory to retain both valuable documents and up-to-date documents. Active retrieval and diverse query generation are utilized to enhance both the precision and scope of the retrieved documents. Furthermore, VTG features a two-tier verifier and an evidence finder, enabling rethinking and reflection on the relationship between the claim and citations. We conduct extensive experiments on five datasets across three knowledge-intensive tasks and the results reveal that VTG significantly outperforms existing baselines.