 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Matters More: Event-Centric Memory as a Logic Map for Agent Searching and Reasoning
Jan 08, 2026Large language models (LLMs) are increasingly deployed as intelligent agents that reason, plan, and interact with their environments. To effectively scale to long-horizon scenarios, a key capability for such agents is a memory mechanism that can retain, organize, and retrieve past experiences to support downstream decision-making. However, most existing approaches organize and store memories in a flat manner and rely on simple similarity-based retrieval techniques. Even when structured memory is introduced, existing methods often struggle to explicitly capture the logical relationships among experiences or memory units. Moreover, memory access is largely detached from the constructed structure and still depends on shallow semantic retrieval, preventing agents from reasoning logically over long-horizon dependencies. In this work, we propose CompassMem, an event-centric memory framework inspired by Event Segmentation Theory. CompassMem organizes memory as an Event Graph by incrementally segmenting experiences into events and linking them through explicit logical relations. This graph serves as a logic map, enabling agents to perform structured and goal-directed navigation over memory beyond superficial retrieval, progressively gathering valuable memories to support long-horizon reasoning. Experiments on LoCoMo and NarrativeQA demonstrate that CompassMem consistently improves both retrieval and reasoning performance across multiple backbone models.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
ORBIT -- Open Recommendation Benchmark for Reproducible Research with Hidden Tests
Oct 30, 2025Recommender systems are among the most impactful AI applications, interacting with billions of users every day, guiding them to relevant products, services, or information tailored to their preferences. However, the research and development of recommender systems are hindered by existing datasets that fail to capture realistic user behaviors and inconsistent evaluation settings that lead to ambiguous conclusions. This paper introduces the Open Recommendation Benchmark for Reproducible Research with HIdden Tests (ORBIT), a unified benchmark for consistent and realistic evaluation of recommendation models. ORBIT offers a standardized evaluation framework of public datasets with reproducible splits and transparent settings for its public leaderboard. Additionally, ORBIT introduces a new webpage recommendation task, ClueWeb-Reco, featuring web browsing sequences from 87 million public, high-quality webpages. ClueWeb-Reco is a synthetic dataset derived from real, user-consented, and privacy-guaranteed browsing data. It aligns with modern recommendation scenarios and is reserved as the hidden test part of our leaderboard to challenge recommendation models' generalization ability. ORBIT measures 12 representative recommendation models on its public benchmark and introduces a prompted LLM baseline on the ClueWeb-Reco hidden test. Our benchmark results reflect general improvements of recommender systems on the public datasets, with variable individual performances. The results on the hidden test reveal the limitations of existing approaches in large-scale webpage recommendation and highlight the potential for improvements with LLM integrations. ORBIT benchmark, leaderboard, and codebase are available at https://www.open-reco-bench.ai.
LLMs + Persona-Plug = Personalized LLMs
Sep 18, 2024



Personalization plays a critical role in numerous language tasks and applications, since users with the same requirements may prefer diverse outputs based on their individual interests. This has led to the development of various personalized approaches aimed at adapting large language models (LLMs) to generate customized outputs aligned with user preferences. Some of them involve fine-tuning a unique personalized LLM for each user, which is too expensive for widespread application. Alternative approaches introduce personalization information in a plug-and-play manner by retrieving the user's relevant historical texts as demonstrations. However, this retrieval-based strategy may break the continuity of the user history and fail to capture the user's overall styles and patterns, hence leading to sub-optimal performance. To address these challenges, we propose a novel personalized LLM model, \ours{}. It constructs a user-specific embedding for each individual by modeling all her historical contexts through a lightweight plug-in user embedder module. By attaching this embedding to the task input, LLMs can better understand and capture user habits and preferences, thereby producing more personalized outputs without tuning their own parameters. Extensive experiments on various tasks in the language model personalization (LaMP) benchmark demonstrate that the proposed model significantly outperforms existing personalized LLM approaches.
Generalizing Conversational Dense Retrieval via LLM-Cognition Data Augmentation
Feb 19, 2024



Conversational search utilizes muli-turn natural language contexts to retrieve relevant passages. Existing conversational dense retrieval models mostly view a conversation as a fixed sequence of questions and responses, overlooking the severe data sparsity problem -- that is, users can perform a conversation in various ways, and these alternate conversations are unrecorded. Consequently, they often struggle to generalize to diverse conversations in real-world scenarios. In this work, we propose a framework for generalizing Conversational dense retrieval via LLM-cognition data Augmentation (ConvAug). ConvAug first generates multi-level augmented conversations to capture the diverse nature of conversational contexts. Inspired by human cognition, we devise a cognition-aware process to mitigate the generation of false positives, false negatives, and hallucinations. Moreover, we develop a difficulty-adaptive sample filter that selects challenging samples for complex conversations, thereby giving the model a larger learning space. A contrastive learning objective is then employed to train a better conversational context encoder. Extensive experiments conducted on four public datasets, under both normal and zero-shot settings, demonstrate the effectiveness, generalizability, and applicability of ConvAug.
Large Language Models for Information Retrieval: A Survey
Aug 15, 2023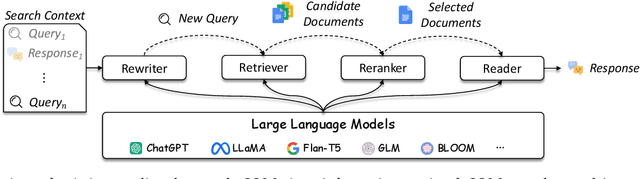
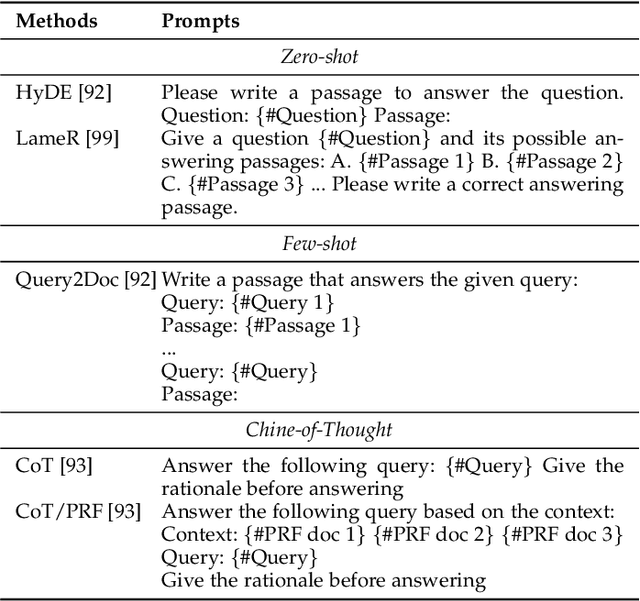
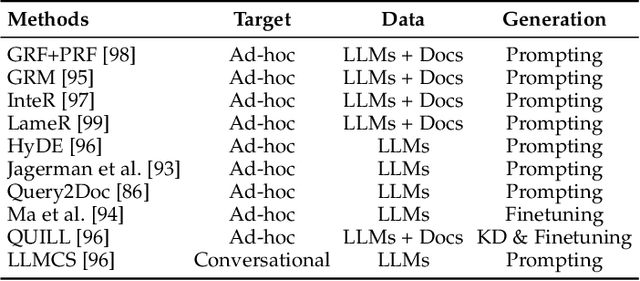
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions within this expanding field.
RETA-LLM: A Retrieval-Augmented Large Language Model Toolkit
Jun 08, 2023

Although Large Language Models (LLMs) have demonstrated extraordinary capabilities in many domains, they still have a tendency to hallucinate and generate fictitious responses to user requests. This problem can be alleviated by augmenting LLMs with information retrieval (IR) systems (also known as retrieval-augmented LLMs). Applying this strategy, LLMs can generate more factual texts in response to user input according to the relevant content retrieved by IR systems from external corpora as references. In addition, by incorporating external knowledge, retrieval-augmented LLMs can answer in-domain questions that cannot be answered by solely relying on the world knowledge stored in parameters. To support research in this area and facilitate the development of retrieval-augmented LLM systems, we develop RETA-LLM, a {RET}reival-{A}ugmented LLM toolkit. In RETA-LLM, we create a complete pipeline to help researchers and users build their customized in-domain LLM-based systems. Compared with previous retrieval-augmented LLM systems, RETA-LLM provides more plug-and-play modules to support better interaction between IR systems and LLMs, including {request rewriting, document retrieval, passage extraction, answer generation, and fact checking} modules. Our toolkit is publicly available at https://github.com/RUC-GSAI/YuLan-IR/tree/main/RETA-LLM.
JDsearch: A Personalized Product Search Dataset with Real Queries and Full Interactions
May 24, 2023



Recently, personalized product search attracts great attention and many models have been proposed. To evaluate the effectiveness of these models, previous studies mainly utilize the simulated Amazon recommendation dataset, which contains automatically generated queries and excludes cold users and tail products. We argue that evaluating with such a dataset may yield unreliable results and conclusions, and deviate from real user satisfaction. To overcome these problems, in this paper, we release a personalized product search dataset comprised of real user queries and diverse user-product interaction types (clicking, adding to cart, following, and purchasing) collected from JD.com, a popular Chinese online shopping platform. More specifically, we sample about 170,000 active users on a specific date, then record all their interacted products and issued queries in one year, without removing any tail users and products. This finally results in roughly 12,000,000 products, 9,400,000 real searches, and 26,000,000 user-product interactions. We study the characteristics of this dataset from various perspectives and evaluate representative personalization models to verify its feasibility. The dataset can be publicly accessed at Github: https://github.com/rucliujn/JDsearch.