 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSumRank: Aligning Summarization Models for Long-Document Listwise Reranking
Mar 25, 2026Large Language Models (LLMs) have demonstrated superior performance in listwise passage reranking task. However, directly applying them to rank long-form documents introduces both effectiveness and efficiency issues due to the substantially increased context length. To address this challenge, we propose a pointwise summarization model SumRank, aligned with downstream listwise reranking, to compress long-form documents into concise rank-aligned summaries before the final listwise reranking stage. To obtain our summarization model SumRank, we introduce a three-stage training pipeline comprising cold-start Supervised Fine-Tuning (SFT), specialized RL data construction, and rank-driven alignment via Reinforcement Learning. This paradigm aligns the SumRank with downstream ranking objectives to preserve relevance signals. We conduct extensive experiments on five benchmark datasets from the TREC Deep Learning tracks (TREC DL 19-23). Results show that our lightweight SumRank model achieves state-of-the-art (SOTA) ranking performance while significantly improving efficiency by reducing both summarization overhead and reranking complexity.
Agentic-R: Learning to Retrieve for Agentic Search
Jan 17, 2026Agentic search has recently emerged as a powerful paradigm, where an agent interleaves multi-step reasoning with on-demand retrieval to solve complex questions. Despite its success, how to design a retriever for agentic search remains largely underexplored. Existing search agents typically rely on similarity-based retrievers, while similar passages are not always useful for final answer generation. In this paper, we propose a novel retriever training framework tailored for agentic search. Unlike retrievers designed for single-turn retrieval-augmented generation (RAG) that only rely on local passage utility, we propose to use both local query-passage relevance and global answer correctness to measure passage utility in a multi-turn agentic search. We further introduce an iterative training strategy, where the search agent and the retriever are optimized bidirectionally and iteratively. Different from RAG retrievers that are only trained once with fixed questions, our retriever is continuously improved using evolving and higher-quality queries from the agent. Extensive experiments on seven single-hop and multi-hop QA benchmarks demonstrate that our retriever, termed \ours{}, consistently outperforms strong baselines across different search agents. Our codes are available at: https://github.com/8421BCD/Agentic-R.
ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
Aug 09, 2025Large Language Model (LLM) based listwise ranking has shown superior performance in many passage ranking tasks. With the development of Large Reasoning Models, many studies have demonstrated that step-by-step reasoning during test-time helps improve listwise ranking performance. However, due to the scarcity of reasoning-intensive training data, existing rerankers perform poorly in many complex ranking scenarios and the ranking ability of reasoning-intensive rerankers remains largely underdeveloped. In this paper, we first propose an automated reasoning-intensive training data synthesis framework, which sources training queries and passages from diverse domains and applies DeepSeek-R1 to generate high-quality training labels. A self-consistency data filtering mechanism is designed to ensure the data quality. To empower the listwise reranker with strong reasoning ability, we further propose a two-stage post-training approach, which includes a cold-start supervised fine-tuning (SFT) stage for reasoning pattern learning and a reinforcement learning (RL) stage for further ranking ability enhancement. During the RL stage, based on the nature of listwise ranking, we design a multi-view ranking reward, which is more effective than a ranking metric-based reward. Extensive experiments demonstrate that our trained reasoning-intensive reranker \textbf{ReasonRank} outperforms existing baselines significantly and also achieves much lower latency than pointwise reranker Rank1. \textbf{Through further experiments, our ReasonRank has achieved state-of-the-art (SOTA) performance 40.6 on the BRIGHT leaderboard\footnote{https://brightbenchmark.github.io/}.} Our codes are available at https://github.com/8421BCD/ReasonRank.
CoRanking: Collaborative Ranking with Small and Large Ranking Agents
Apr 01, 2025Large Language Models (LLMs) have demonstrated superior listwise ranking performance. However, their superior performance often relies on large-scale parameters (\eg, GPT-4) and a repetitive sliding window process, which introduces significant efficiency challenges. In this paper, we propose \textbf{CoRanking}, a novel collaborative ranking framework that combines small and large ranking models for efficient and effective ranking. CoRanking first employs a small-size reranker to pre-rank all the candidate passages, bringing relevant ones to the top part of the list (\eg, top-20). Then, the LLM listwise reranker is applied to only rerank these top-ranked passages instead of the whole list, substantially enhancing overall ranking efficiency. Although more efficient, previous studies have revealed that the LLM listwise reranker have significant positional biases on the order of input passages. Directly feed the top-ranked passages from small reranker may result in the sub-optimal performance of LLM listwise reranker. To alleviate this problem, we introduce a passage order adjuster trained via reinforcement learning, which reorders the top passages from the small reranker to align with the LLM's preferences of passage order. Extensive experiments on three IR benchmarks demonstrate that CoRanking significantly improves efficiency (reducing ranking latency by about 70\%) while achieving even better effectiveness compared to using only the LLM listwise reranker.
Sliding Windows Are Not the End: Exploring Full Ranking with Long-Context Large Language Models
Dec 19, 2024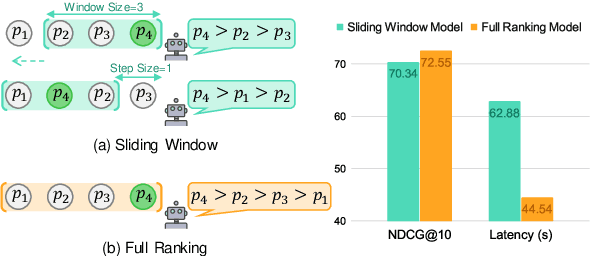
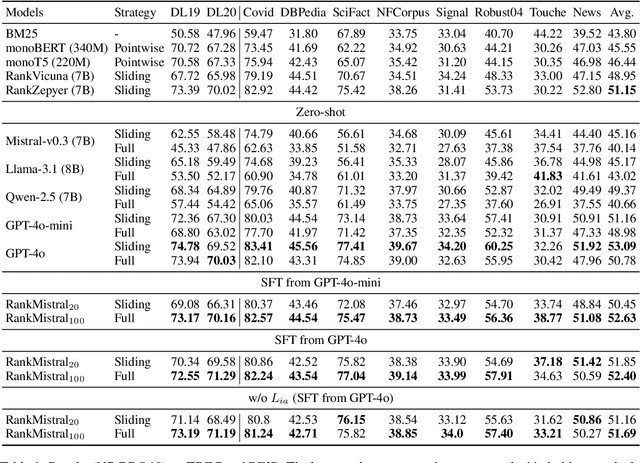
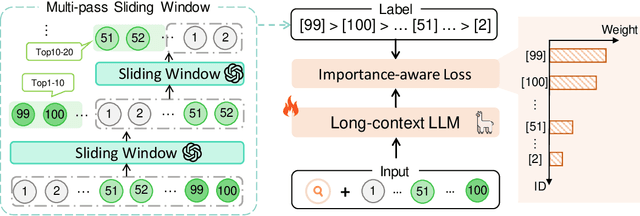
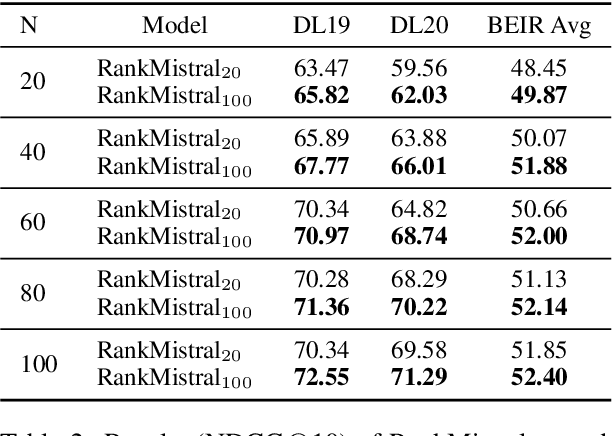
Large Language Models (LLMs) have shown exciting performance in listwise passage ranking. Due to the limited input length, existing methods often adopt the sliding window strategy. Such a strategy, though effective, is inefficient as it involves repetitive and serialized processing, which usually re-evaluates relevant passages multiple times. As a result, it incurs redundant API costs, which are proportional to the number of inference tokens. The development of long-context LLMs enables the full ranking of all passages within a single inference, avoiding redundant API costs. In this paper, we conduct a comprehensive study of long-context LLMs for ranking tasks in terms of efficiency and effectiveness. Surprisingly, our experiments reveal that full ranking with long-context LLMs can deliver superior performance in the supervised fine-tuning setting with a huge efficiency improvement. Furthermore, we identify two limitations of fine-tuning the full ranking model based on existing methods: (1) sliding window strategy fails to produce a full ranking list as a training label, and (2) the language modeling loss cannot emphasize top-ranked passage IDs in the label. To alleviate these issues, we propose a new complete listwise label construction approach and a novel importance-aware learning objective for full ranking. Experiments show the superior performance of our method over baselines. Our codes are available at \url{https://github.com/8421BCD/fullrank}.
DemoRank: Selecting Effective Demonstrations for Large Language Models in Ranking Task
Jun 24, 2024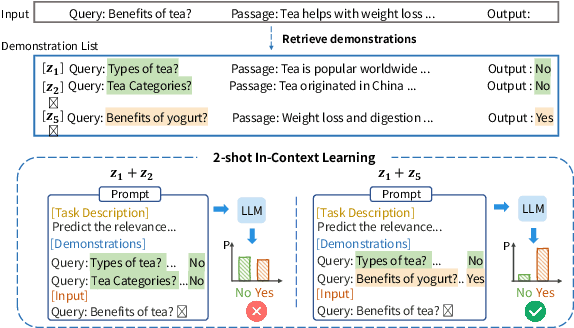
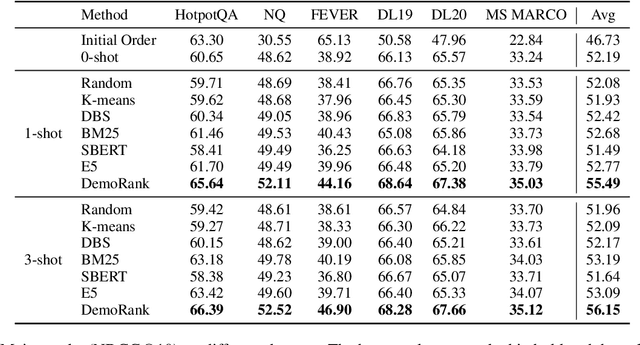
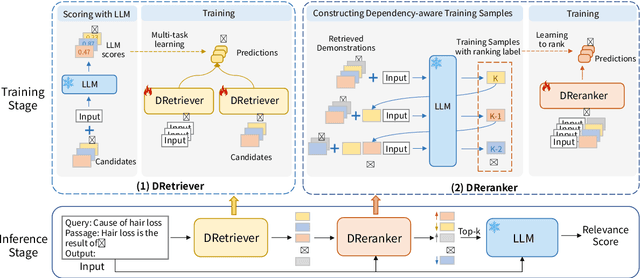
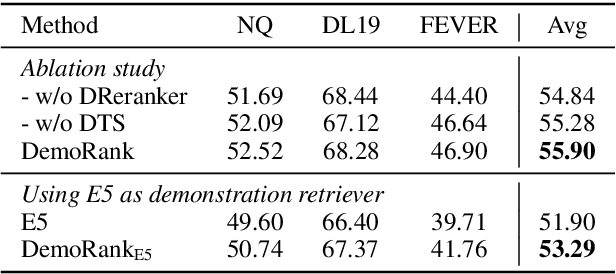
Recently, there has been increasing interest in applying large language models (LLMs) as zero-shot passage rankers. However, few studies have explored how to select appropriate in-context demonstrations for the passage ranking task, which is the focus of this paper. Previous studies mainly apply a demonstration retriever to retrieve demonstrations and use top-$k$ demonstrations for in-context learning (ICL). Although effective, this approach overlooks the dependencies between demonstrations, leading to inferior performance of few-shot ICL in the passage ranking task. In this paper, we formulate the demonstration selection as a \textit{retrieve-then-rerank} process and introduce the DemoRank framework. In this framework, we first use LLM feedback to train a demonstration retriever and construct a novel dependency-aware training samples to train a demonstration reranker to improve few-shot ICL. The construction of such training samples not only considers demonstration dependencies but also performs in an efficient way. Extensive experiments demonstrate DemoRank's effectiveness in in-domain scenarios and strong generalization to out-of-domain scenarios. Our codes are available at~\url{https://github.com/8421BCD/DemoRank}.
Large Language Models for Information Retrieval: A Survey
Aug 15, 2023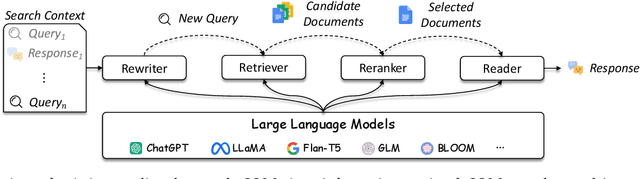
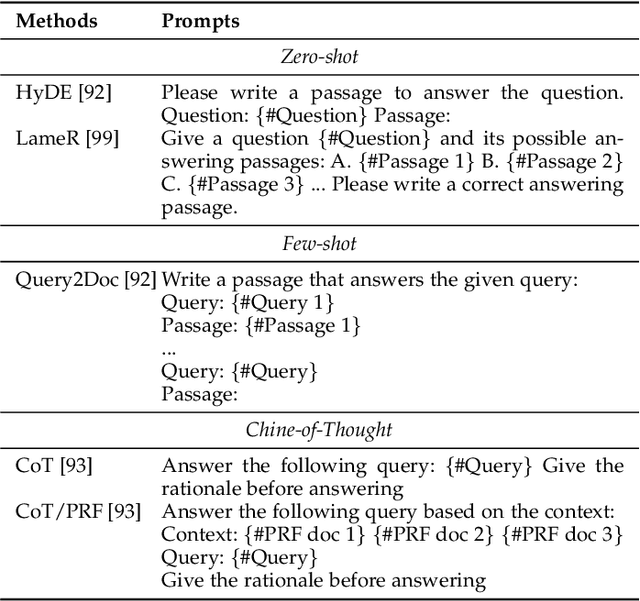
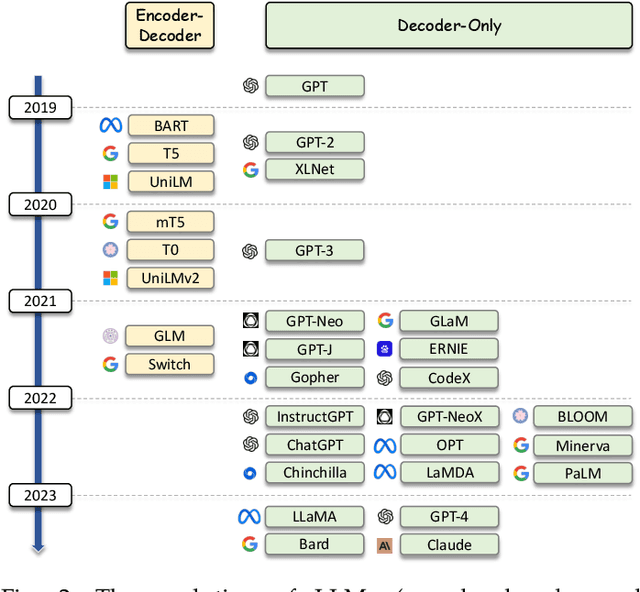
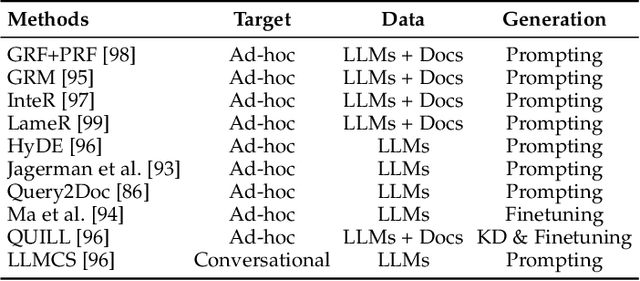
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions within this expanding field.
Defending Label Inference and Backdoor Attacks in Vertical Federated Learning
Dec 10, 2021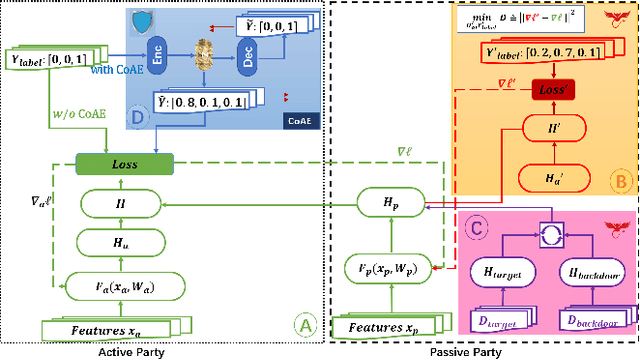

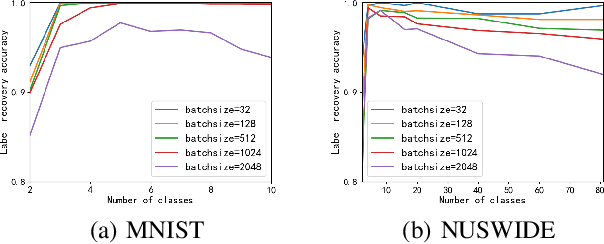
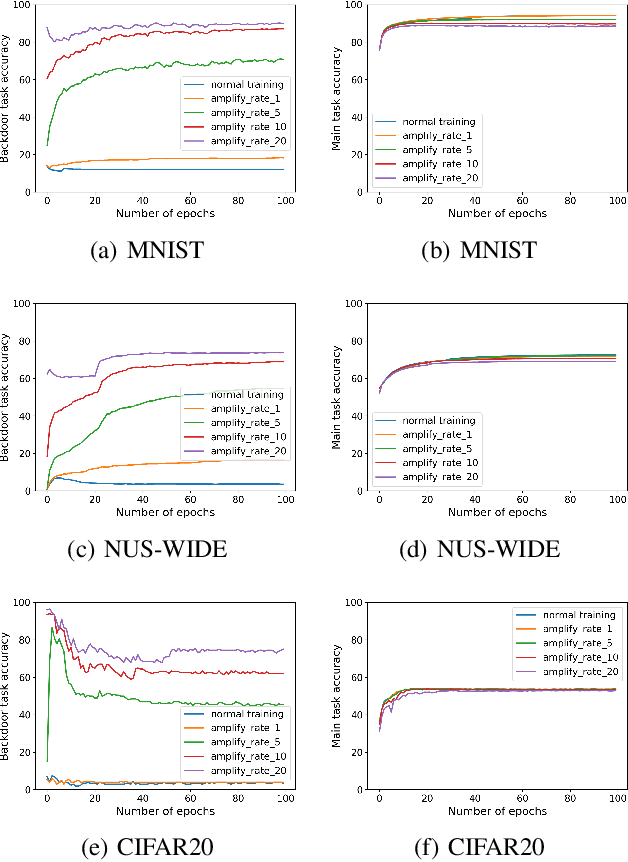
In collaborative learning settings like federated learning, curious parities might be honest but are attempting to infer other parties' private data through inference attacks while malicious parties might manipulate the learning process for their own purposes through backdoor attacks. However, most existing works only consider the federated learning scenario where data are partitioned by samples (HFL). The feature-partitioned federated learning (VFL) can be another important scenario in many real-world applications. Attacks and defenses in such scenarios are especially challenging when the attackers and the defenders are not able to access the features or model parameters of other participants. Previous works have only shown that private labels can be reconstructed from per-sample gradients. In this paper, we first show that private labels can be reconstructed when only batch-averaged gradients are revealed, which is against the common presumption. In addition, we show that a passive party in VFL can even replace its corresponding labels in the active party with a target label through a gradient-replacement attack. To defend against the first attack, we introduce a novel technique termed confusional autoencoder (CoAE), based on autoencoder and entropy regularization. We demonstrate that label inference attacks can be successfully blocked by this technique while hurting less main task accuracy compared to existing methods. Our CoAE technique is also effective in defending the gradient-replacement backdoor attack, making it an universal and practical defense strategy with no change to the original VFL protocol. We demonstrate the effectiveness of our approaches under both two-party and multi-party VFL settings. To the best of our knowledge, this is the first systematic study to deal with label inference and backdoor attacks in the feature-partitioned federated learning framework.