 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Powered Query-Driven Event Timeline Summarization in Industrial Search
May 26, 2026Understanding how events evolve over time is essential for search engines handling queries about trending news. We present QDET (Query-Driven Event Timeline Summarization), a production system deployed on Baidu Search that constructs focused event timelines to explain specific query events. Unlike traditional topic-centric approaches that aim for comprehensive coverage, QDET identifies and organizes sub-events closely relevant to the query from noisy candidate sets formed by millions of documents retrieved daily. QDET incorporates two key innovations: (1) multi-task supervised fine-tuning with three auxiliary tasks-temporal ordering, causal judgment, and timeline completion-that enable compact models to match the performance of much larger general-purpose models in specialized domains; (2) reinforcement learning-based event concise summarization that enforces strict length constraints while maintaining semantic quality, achieving 88.2% length compliance and outperforming 671B-scale models by 7.7 points in constraint satisfaction. Our fine-tuned 7B parameter model achieves 76.2% F1 score on timeline summarization, slightly surpassing the zero-shot performance of DeepSeek-R1-671B (76.1% F1) while using only 1% of its parameters-demonstrating that domain-specific optimization enables production-ready models with comparable quality at drastically reduced computational costs. Online A/B tests on Baidu Search validate real-world effectiveness, showing 5.5% CTR improvement, 4.6% longer dwell time, and 4.4% deeper exploration compared to single-task baselines. We further demonstrate that timeline understanding transfers to heat prediction, confirming effective knowledge transfer to downstream tasks.
RAG-Enhanced Large Language Models for Dynamic Content Expiration Prediction in Web Search
May 13, 2026In commercial web search, aligning content freshness with user intent remains challenging due to the highly varied lifespans of information. Traditional industrial approaches rely on static time-window filtering, resulting in "one-size-fits-all" rankings where content may be chronologically recent but semantically expired. To address the limitation, we present a novel Large Language Models (LLMs)-based Query-Aware Dynamic Content Expiration Prediction Framework deployed in Baidu search, reformulating timeliness as a dynamic validity inference task. Our framework extracts fine-grained temporal contexts from documents and leverages LLMs to deduce a query-specific "validity horizon"-a semantic boundary defining when information becomes obsolete based on user intent. Integrated with robust hallucination mitigation strategies to ensure reliability, our approach has been evaluated through offline and online A/B testing on live production traffic. Results demonstrate significant improvements in search freshness and user experience metrics, validating the effectiveness of LLM-driven reasoning for solving semantic expiration at an industrial scale.
How to Utilize Complementary Vision-Text Information for 2D Structure Understanding
Mar 17, 2026LLMs typically linearize 2D tables into 1D sequences to fit their autoregressive architecture, which weakens row-column adjacency and other layout cues. In contrast, purely visual encoders can capture spatial cues, yet often struggle to preserve exact cell text. Our analysis reveals that these two modalities provide highly distinct information to LLMs and exhibit strong complementarity. However, direct concatenation and other fusion methods yield limited gains and frequently introduce cross-modal interference. To address this issue, we propose DiVA-Former, a lightweight architecture designed to effectively integrate vision and text information. DiVA-Former leverages visual tokens as dynamic queries to distill long textual sequences into digest vectors, thereby effectively exploiting complementary vision--text information. Evaluated across 13 table benchmarks, DiVA-Former improves upon the pure-text baseline by 23.9\% and achieves consistent gains over existing baselines using visual inputs, textual inputs, or a combination of both.
Reconstructing Content via Collaborative Attention to Improve Multimodal Embedding Quality
Mar 02, 2026Multimodal embedding models, rooted in multimodal large language models (MLLMs), have yielded significant performance improvements across diverse tasks such as retrieval and classification. However, most existing approaches rely heavily on large-scale contrastive learning, with limited exploration of how the architectural and training paradigms of MLLMs affect embedding quality. While effective for generation, the causal attention and next-token prediction paradigm of MLLMs does not explicitly encourage the formation of globally compact representations, limiting their effectiveness as multimodal embedding backbones. To address this, we propose CoCoA, a Content reconstruction pre-training paradigm based on Collaborative Attention for multimodal embedding optimization. Specifically, we restructure the attention flow and introduce an EOS-based reconstruction task, encouraging the model to reconstruct input from the corresponding <EOS> embeddings. This drives the multimodal model to compress the semantic information of the input into the <EOS> token, laying the foundations for subsequent contrastive learning. Extensive experiments on MMEB-V1 demonstrate that CoCoA built upon Qwen2-VL and Qwen2.5-VL significantly improves embedding quality. Results validate that content reconstruction serves as an effective strategy to maximize the value of existing data, enabling multimodal embedding models generate compact and informative representations, raising their performance ceiling.
Thinking Forward and Backward: Multi-Objective Reinforcement Learning for Retrieval-Augmented Reasoning
Nov 13, 2025Retrieval-augmented generation (RAG) has proven to be effective in mitigating hallucinations in large language models, yet its effectiveness remains limited in complex, multi-step reasoning scenarios. Recent efforts have incorporated search-based interactions into RAG, enabling iterative reasoning with real-time retrieval. Most approaches rely on outcome-based supervision, offering no explicit guidance for intermediate steps. This often leads to reward hacking and degraded response quality. We propose Bi-RAR, a novel retrieval-augmented reasoning framework that evaluates each intermediate step jointly in both forward and backward directions. To assess the information completeness of each step, we introduce a bidirectional information distance grounded in Kolmogorov complexity, approximated via language model generation probabilities. This quantification measures both how far the current reasoning is from the answer and how well it addresses the question. To optimize reasoning under these bidirectional signals, we adopt a multi-objective reinforcement learning framework with a cascading reward structure that emphasizes early trajectory alignment. Empirical results on seven question answering benchmarks demonstrate that Bi-RAR surpasses previous methods and enables efficient interaction and reasoning with the search engine during training and inference.
TP-RAG: Benchmarking Retrieval-Augmented Large Language Model Agents for Spatiotemporal-Aware Travel Planning
Apr 11, 2025Large language models (LLMs) have shown promise in automating travel planning, yet they often fall short in addressing nuanced spatiotemporal rationality. While existing benchmarks focus on basic plan validity, they neglect critical aspects such as route efficiency, POI appeal, and real-time adaptability. This paper introduces TP-RAG, the first benchmark tailored for retrieval-augmented, spatiotemporal-aware travel planning. Our dataset includes 2,348 real-world travel queries, 85,575 fine-grain annotated POIs, and 18,784 high-quality travel trajectory references sourced from online tourist documents, enabling dynamic and context-aware planning. Through extensive experiments, we reveal that integrating reference trajectories significantly improves spatial efficiency and POI rationality of the travel plan, while challenges persist in universality and robustness due to conflicting references and noisy data. To address these issues, we propose EvoRAG, an evolutionary framework that potently synergizes diverse retrieved trajectories with LLMs' intrinsic reasoning. EvoRAG achieves state-of-the-art performance, improving spatiotemporal compliance and reducing commonsense violation compared to ground-up and retrieval-augmented baselines. Our work underscores the potential of hybridizing Web knowledge with LLM-driven optimization, paving the way for more reliable and adaptive travel planning agents.
CoRanking: Collaborative Ranking with Small and Large Ranking Agents
Apr 01, 2025Large Language Models (LLMs) have demonstrated superior listwise ranking performance. However, their superior performance often relies on large-scale parameters (\eg, GPT-4) and a repetitive sliding window process, which introduces significant efficiency challenges. In this paper, we propose \textbf{CoRanking}, a novel collaborative ranking framework that combines small and large ranking models for efficient and effective ranking. CoRanking first employs a small-size reranker to pre-rank all the candidate passages, bringing relevant ones to the top part of the list (\eg, top-20). Then, the LLM listwise reranker is applied to only rerank these top-ranked passages instead of the whole list, substantially enhancing overall ranking efficiency. Although more efficient, previous studies have revealed that the LLM listwise reranker have significant positional biases on the order of input passages. Directly feed the top-ranked passages from small reranker may result in the sub-optimal performance of LLM listwise reranker. To alleviate this problem, we introduce a passage order adjuster trained via reinforcement learning, which reorders the top passages from the small reranker to align with the LLM's preferences of passage order. Extensive experiments on three IR benchmarks demonstrate that CoRanking significantly improves efficiency (reducing ranking latency by about 70\%) while achieving even better effectiveness compared to using only the LLM listwise reranker.
Cross-model Control: Improving Multiple Large Language Models in One-time Training
Oct 23, 2024



The number of large language models (LLMs) with varying parameter scales and vocabularies is increasing. While they deliver powerful performance, they also face a set of common optimization needs to meet specific requirements or standards, such as instruction following or avoiding the output of sensitive information from the real world. However, how to reuse the fine-tuning outcomes of one model to other models to reduce training costs remains a challenge. To bridge this gap, we introduce Cross-model Control (CMC), a method that improves multiple LLMs in one-time training with a portable tiny language model. Specifically, we have observed that the logit shift before and after fine-tuning is remarkably similar across different models. Based on this insight, we incorporate a tiny language model with a minimal number of parameters. By training alongside a frozen template LLM, the tiny model gains the capability to alter the logits output by the LLMs. To make this tiny language model applicable to models with different vocabularies, we propose a novel token mapping strategy named PM-MinED. We have conducted extensive experiments on instruction tuning and unlearning tasks, demonstrating the effectiveness of CMC. Our code is available at https://github.com/wujwyi/CMC.
JAILJUDGE: A Comprehensive Jailbreak Judge Benchmark with Multi-Agent Enhanced Explanation Evaluation Framework
Oct 11, 2024



Despite advancements in enhancing LLM safety against jailbreak attacks, evaluating LLM defenses remains a challenge, with current methods often lacking explainability and generalization to complex scenarios, leading to incomplete assessments (e.g., direct judgment without reasoning, low F1 score of GPT-4 in complex cases, bias in multilingual scenarios). To address this, we present JAILJUDGE, a comprehensive benchmark featuring diverse risk scenarios, including synthetic, adversarial, in-the-wild, and multilingual prompts, along with high-quality human-annotated datasets. The JAILJUDGE dataset includes over 35k+ instruction-tune data with reasoning explainability and JAILJUDGETEST, a 4.5k+ labeled set for risk scenarios, and a 6k+ multilingual set across ten languages. To enhance evaluation with explicit reasoning, we propose the JailJudge MultiAgent framework, which enables explainable, fine-grained scoring (1 to 10). This framework supports the construction of instruction-tuning ground truth and facilitates the development of JAILJUDGE Guard, an end-to-end judge model that provides reasoning and eliminates API costs. Additionally, we introduce JailBoost, an attacker-agnostic attack enhancer, and GuardShield, a moderation defense, both leveraging JAILJUDGE Guard. Our experiments demonstrate the state-of-the-art performance of JailJudge methods (JailJudge MultiAgent, JAILJUDGE Guard) across diverse models (e.g., GPT-4, Llama-Guard) and zero-shot scenarios. JailBoost and GuardShield significantly improve jailbreak attack and defense tasks under zero-shot settings, with JailBoost enhancing performance by 29.24% and GuardShield reducing defense ASR from 40.46% to 0.15%.
FltLM: An Intergrated Long-Context Large Language Model for Effective Context Filtering and Understanding
Oct 09, 2024
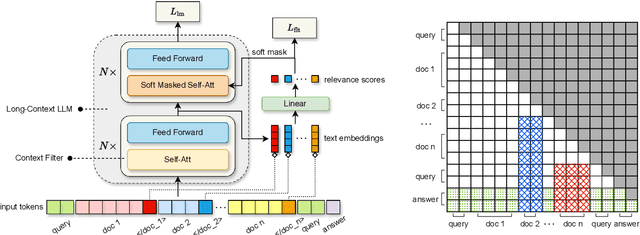

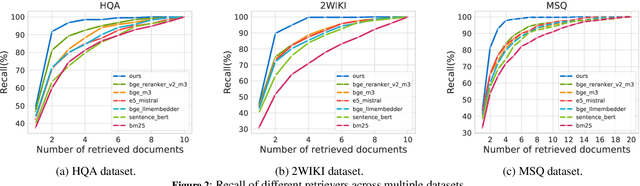
The development of Long-Context Large Language Models (LLMs) has markedly advanced natural language processing by facilitating the process of textual data across long documents and multiple corpora. However, Long-Context LLMs still face two critical challenges: The lost in the middle phenomenon, where crucial middle-context information is likely to be missed, and the distraction issue that the models lose focus due to overly extended contexts. To address these challenges, we propose the Context Filtering Language Model (FltLM), a novel integrated Long-Context LLM which enhances the ability of the model on multi-document question-answering (QA) tasks. Specifically, FltLM innovatively incorporates a context filter with a soft mask mechanism, identifying and dynamically excluding irrelevant content to concentrate on pertinent information for better comprehension and reasoning. Our approach not only mitigates these two challenges, but also enables the model to operate conveniently in a single forward pass. Experimental results demonstrate that FltLM significantly outperforms supervised fine-tuning and retrieval-based methods in complex QA scenarios, suggesting a promising solution for more accurate and reliable long-context natural language understanding applications.