 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRE: Encouraging Exploration in the Trust Region
Feb 03, 2026Entropy regularization is a standard technique in reinforcement learning (RL) to enhance exploration, yet it yields negligible effects or even degrades performance in Large Language Models (LLMs). We attribute this failure to the cumulative tail risk inherent to LLMs with massive vocabularies and long generation horizons. In such environments, standard global entropy maximization indiscriminately dilutes probability mass into the vast tail of invalid tokens rather than focusing on plausible candidates, thereby disrupting coherent reasoning. To address this, we propose Trust Region Entropy (TRE), a method that encourages exploration strictly within the model's trust region. Extensive experiments across mathematical reasoning (MATH), combinatorial search (Countdown), and preference alignment (HH) tasks demonstrate that TRE consistently outperforms vanilla PPO, standard entropy regularization, and other exploration baselines. Our code is available at https://github.com/WhyChaos/TRE-Encouraging-Exploration-in-the-Trust-Region.
Advancing General-Purpose Reasoning Models with Modular Gradient Surgery
Feb 02, 2026Reinforcement learning (RL) has played a central role in recent advances in large reasoning models (LRMs), yielding strong gains in verifiable and open-ended reasoning. However, training a single general-purpose LRM across diverse domains remains challenging due to pronounced domain heterogeneity. Through a systematic study of two widely used strategies, Sequential RL and Mixed RL, we find that both incur substantial cross-domain interference at the behavioral and gradient levels, resulting in limited overall gains. To address these challenges, we introduce **M**odular **G**radient **S**urgery (**MGS**), which resolves gradient conflicts at the module level within the transformer. When applied to Llama and Qwen models, MGS achieves average improvements of 4.3 (16.6\%) and 4.5 (11.1\%) points, respectively, over standard multi-task RL across three representative domains (math, general chat, and instruction following). Further analysis demonstrates that MGS remains effective under prolonged training. Overall, our study clarifies the sources of interference in multi-domain RL and presents an effective solution for training general-purpose LRMs.
GenCRF: Generative Clustering and Reformulation Framework for Enhanced Intent-Driven Information Retrieval
Sep 17, 2024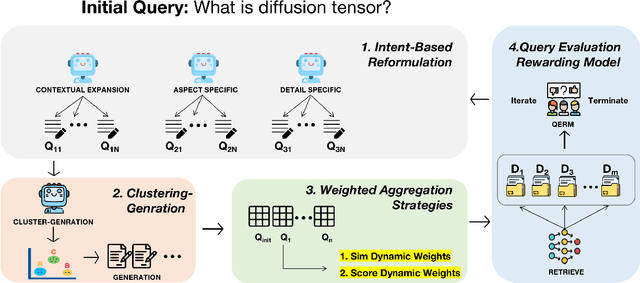
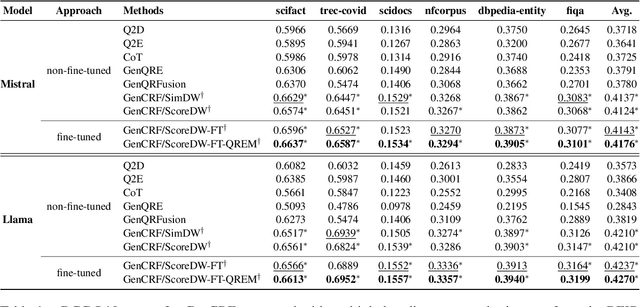
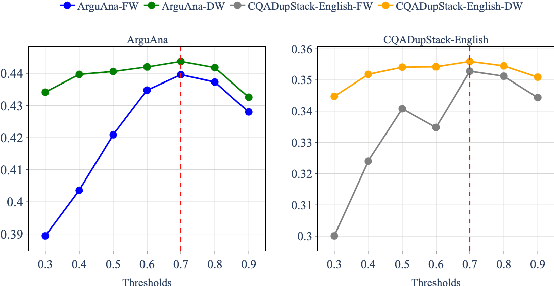
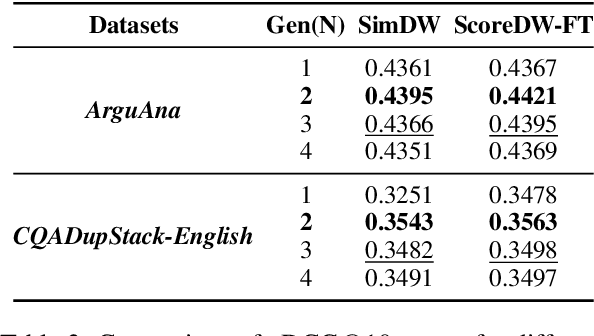
Query reformulation is a well-known problem in Information Retrieval (IR) aimed at enhancing single search successful completion rate by automatically modifying user's input query. Recent methods leverage Large Language Models (LLMs) to improve query reformulation, but often generate limited and redundant expansions, potentially constraining their effectiveness in capturing diverse intents. In this paper, we propose GenCRF: a Generative Clustering and Reformulation Framework to capture diverse intentions adaptively based on multiple differentiated, well-generated queries in the retrieval phase for the first time. GenCRF leverages LLMs to generate variable queries from the initial query using customized prompts, then clusters them into groups to distinctly represent diverse intents. Furthermore, the framework explores to combine diverse intents query with innovative weighted aggregation strategies to optimize retrieval performance and crucially integrates a novel Query Evaluation Rewarding Model (QERM) to refine the process through feedback loops. Empirical experiments on the BEIR benchmark demonstrate that GenCRF achieves state-of-the-art performance, surpassing previous query reformulation SOTAs by up to 12% on nDCG@10. These techniques can be adapted to various LLMs, significantly boosting retriever performance and advancing the field of Information Retrieval.
TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
Oct 26, 2020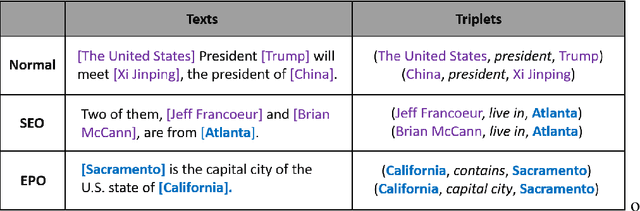

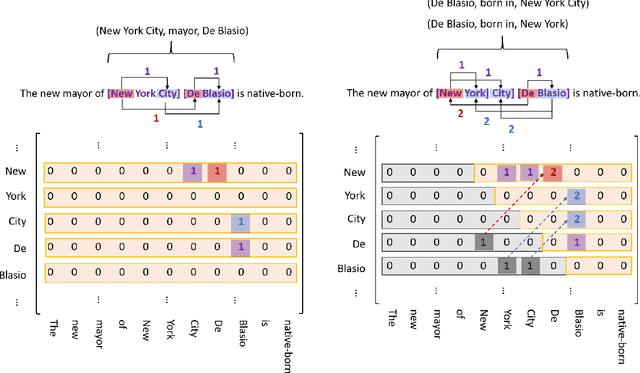

Extracting entities and relations from unstructured text has attracted increasing attention in recent years but remains challenging, due to the intrinsic difficulty in identifying overlapping relations with shared entities. Prior works show that joint learning can result in a noticeable performance gain. However, they usually involve sequential interrelated steps and suffer from the problem of exposure bias. At training time, they predict with the ground truth conditions while at inference it has to make extraction from scratch. This discrepancy leads to error accumulation. To mitigate the issue, we propose in this paper a one-stage joint extraction model, namely, TPLinker, which is capable of discovering overlapping relations sharing one or both entities while immune from the exposure bias. TPLinker formulates joint extraction as a token pair linking problem and introduces a novel handshaking tagging scheme that aligns the boundary tokens of entity pairs under each relation type. Experiment results show that TPLinker performs significantly better on overlapping and multiple relation extraction, and achieves state-of-the-art performance on two public datasets.
Focus Quality Assessment of High-Throughput Whole Slide Imaging in Digital Pathology
Nov 14, 2018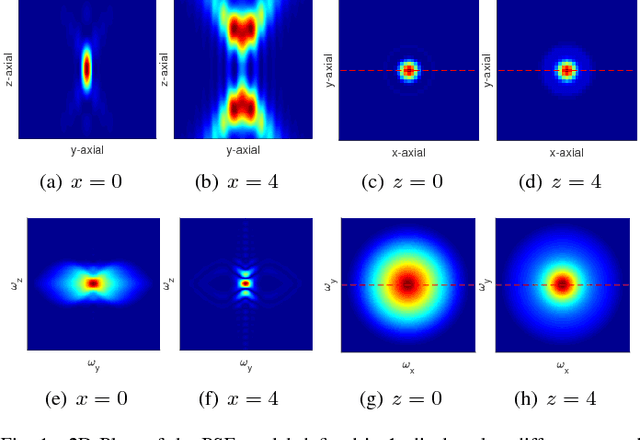
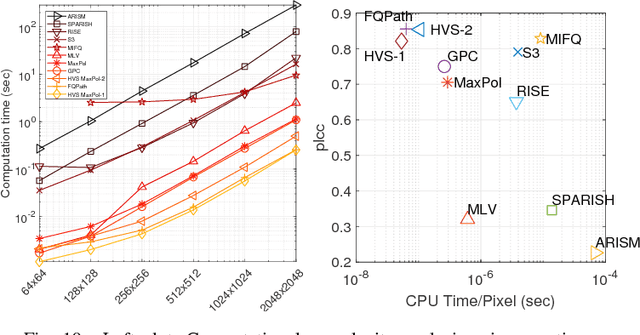
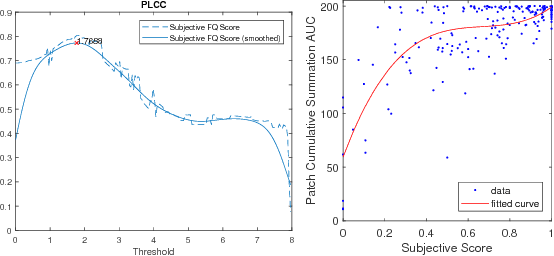
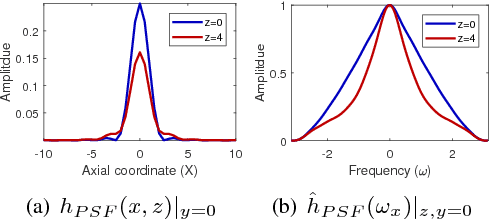
One of the challenges facing the adoption of digital pathology workflows for clinical use is the need for automated quality control. As the scanners sometimes determine focus inaccurately, the resultant image blur deteriorates the scanned slide to the point of being unusable. Also, the scanned slide images tend to be extremely large when scanned at greater or equal 20X image resolution. Hence, for digital pathology to be clinically useful, it is necessary to use computational tools to quickly and accurately quantify the image focus quality and determine whether an image needs to be re-scanned. We propose a no-reference focus quality assessment metric specifically for digital pathology images, that operates by using a sum of even-derivative filter bases to synthesize a human visual system-like kernel, which is modeled as the inverse of the lens' point spread function. This kernel is then applied to a digital pathology image to modify high-frequency image information deteriorated by the scanner's optics and quantify the focus quality at the patch level. We show in several experiments that our method correlates better with ground-truth $z$-level data than other methods, and is more computationally efficient. We also extend our method to generate a local slide-level focus quality heatmap, which can be used for automated slide quality control, and demonstrate the utility of our method for clinical scan quality control by comparison with subjective slide quality scores.