 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Pathology: A Survey Review and The Way Forward
Apr 11, 2023



Computational Pathology (CoPath) is an interdisciplinary science that augments developments of computational approaches to analyze and model medical histopathology images. The main objective for CoPath is to develop infrastructure and workflows of digital diagnostics as an assistive CAD system for clinical pathology facilitating transformational changes in the diagnosis and treatment of cancer diseases. With evergrowing developments in deep learning and computer vision algorithms, and the ease of the data flow from digital pathology, currently CoPath is witnessing a paradigm shift. Despite the sheer volume of engineering and scientific works being introduced for cancer image analysis, there is still a considerable gap of adopting and integrating these algorithms in clinical practice. This raises a significant question regarding the direction and trends that are undertaken in CoPath. In this article we provide a comprehensive review of more than 700 papers to address the challenges faced in problem design all-the-way to the application and implementation viewpoints. We have catalogued each paper into a model-card by examining the key works and challenges faced to layout the current landscape in CoPath. We hope this helps the community to locate relevant works and facilitate understanding of the field's future directions. In a nutshell, we oversee the CoPath developments in cycle of stages which are required to be cohesively linked together to address the challenges associated with such multidisciplinary science. We overview this cycle from different perspectives of data-centric, model-centric, and application-centric problems. We finally sketch remaining challenges and provide directions for future technical developments and clinical integration of CoPath.
A Comprehensive Analysis of Weakly-Supervised Semantic Segmentation in Different Image Domains
Dec 24, 2019
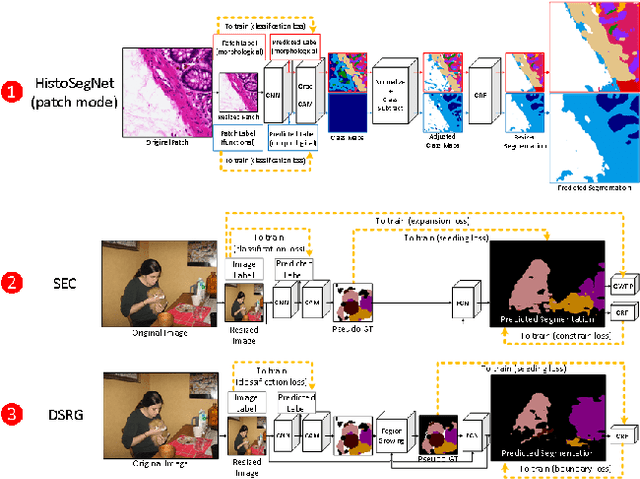


Recently proposed methods for weakly-supervised semantic segmentation have achieved impressive performance in predicting pixel classes despite being trained with only image labels which lack positional information. Because image annotations are cheaper and quicker to generate, weak supervision is more feasible for training segmentation algorithms in certain datasets. These methods have been predominantly developed on natural scene images and it is unclear whether they can be simply transferred to other domains with different characteristics, such as histopathology and satellite images, and still perform well. Little work has been conducted in the literature on applying weakly-supervised methods to these other image domains; it is unknown how to determine whether certain methods are more suitable for certain datasets, and how to determine the best method to use for a new dataset. This paper evaluates state-of-the-art weakly-supervised semantic segmentation methods on natural scene, histopathology, and satellite image datasets. We also analyze the compatibility of the methods for each dataset and present some principles for applying weakly-supervised semantic segmentation on an unseen image dataset.
Focus Quality Assessment of High-Throughput Whole Slide Imaging in Digital Pathology
Nov 14, 2018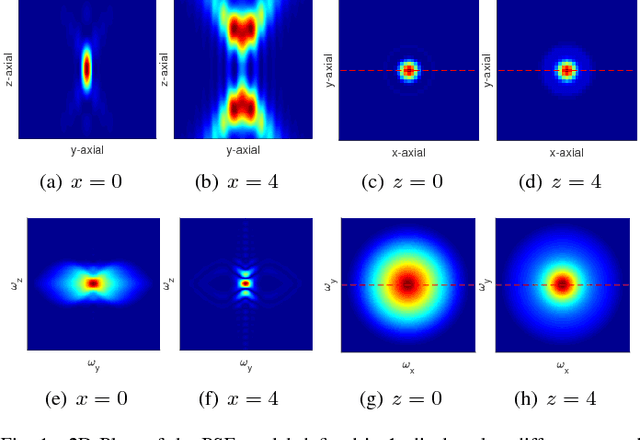
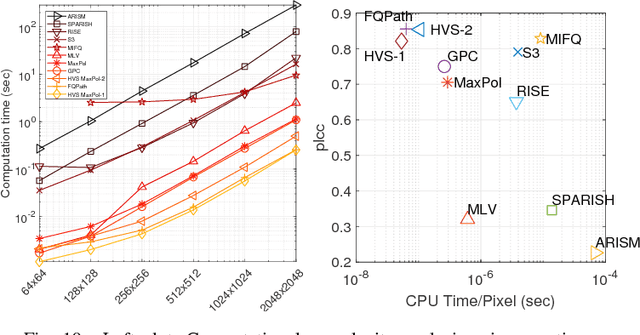
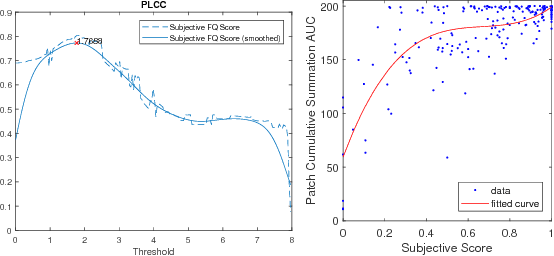
One of the challenges facing the adoption of digital pathology workflows for clinical use is the need for automated quality control. As the scanners sometimes determine focus inaccurately, the resultant image blur deteriorates the scanned slide to the point of being unusable. Also, the scanned slide images tend to be extremely large when scanned at greater or equal 20X image resolution. Hence, for digital pathology to be clinically useful, it is necessary to use computational tools to quickly and accurately quantify the image focus quality and determine whether an image needs to be re-scanned. We propose a no-reference focus quality assessment metric specifically for digital pathology images, that operates by using a sum of even-derivative filter bases to synthesize a human visual system-like kernel, which is modeled as the inverse of the lens' point spread function. This kernel is then applied to a digital pathology image to modify high-frequency image information deteriorated by the scanner's optics and quantify the focus quality at the patch level. We show in several experiments that our method correlates better with ground-truth $z$-level data than other methods, and is more computationally efficient. We also extend our method to generate a local slide-level focus quality heatmap, which can be used for automated slide quality control, and demonstrate the utility of our method for clinical scan quality control by comparison with subjective slide quality scores.