 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDictionary-Learning-Based Data Pruning for System Identification
Feb 17, 2025



System identification is normally involved in augmenting time series data by time shifting and nonlinearisation (via polynomial basis), which introduce redundancy both feature-wise and sample-wise. Many research works focus on reducing redundancy feature-wise, while less attention is paid to sample-wise redundancy. This paper proposes a novel data pruning method, called (mini-batch) FastCan, to reduce sample-wise redundancy based on dictionary learning. Time series data is represented by some representative samples, called atoms, via dictionary learning. The useful samples are selected based on their correlation with the atoms. The method is tested on one simulated dataset and two benchmark datasets. The R-squared between the coefficients of models trained on the full and the coefficients of models trained on pruned datasets is adopted to evaluate the performance of data pruning methods. It is found that the proposed method significantly outperforms the random pruning method.
RAG-WM: An Efficient Black-Box Watermarking Approach for Retrieval-Augmented Generation of Large Language Models
Jan 09, 2025



In recent years, tremendous success has been witnessed in Retrieval-Augmented Generation (RAG), widely used to enhance Large Language Models (LLMs) in domain-specific, knowledge-intensive, and privacy-sensitive tasks. However, attackers may steal those valuable RAGs and deploy or commercialize them, making it essential to detect Intellectual Property (IP) infringement. Most existing ownership protection solutions, such as watermarks, are designed for relational databases and texts. They cannot be directly applied to RAGs because relational database watermarks require white-box access to detect IP infringement, which is unrealistic for the knowledge base in RAGs. Meanwhile, post-processing by the adversary's deployed LLMs typically destructs text watermark information. To address those problems, we propose a novel black-box "knowledge watermark" approach, named RAG-WM, to detect IP infringement of RAGs. RAG-WM uses a multi-LLM interaction framework, comprising a Watermark Generator, Shadow LLM & RAG, and Watermark Discriminator, to create watermark texts based on watermark entity-relationship tuples and inject them into the target RAG. We evaluate RAG-WM across three domain-specific and two privacy-sensitive tasks on four benchmark LLMs. Experimental results show that RAG-WM effectively detects the stolen RAGs in various deployed LLMs. Furthermore, RAG-WM is robust against paraphrasing, unrelated content removal, knowledge insertion, and knowledge expansion attacks. Lastly, RAG-WM can also evade watermark detection approaches, highlighting its promising application in detecting IP infringement of RAG systems.
HoneyGPT: Breaking the Trilemma in Terminal Honeypots with Large Language Model
Jun 04, 2024



Honeypots, as a strategic cyber-deception mechanism designed to emulate authentic interactions and bait unauthorized entities, continue to struggle with balancing flexibility, interaction depth, and deceptive capability despite their evolution over decades. Often they also lack the capability of proactively adapting to an attacker's evolving tactics, which restricts the depth of engagement and subsequent information gathering. Under this context, the emergent capabilities of large language models, in tandem with pioneering prompt-based engineering techniques, offer a transformative shift in the design and deployment of honeypot technologies. In this paper, we introduce HoneyGPT, a pioneering honeypot architecture based on ChatGPT, heralding a new era of intelligent honeypot solutions characterized by their cost-effectiveness, high adaptability, and enhanced interactivity, coupled with a predisposition for proactive attacker engagement. Furthermore, we present a structured prompt engineering framework that augments long-term interaction memory and robust security analytics. This framework, integrating thought of chain tactics attuned to honeypot contexts, enhances interactivity and deception, deepens security analytics, and ensures sustained engagement. The evaluation of HoneyGPT includes two parts: a baseline comparison based on a collected dataset and a field evaluation in real scenarios for four weeks. The baseline comparison demonstrates HoneyGPT's remarkable ability to strike a balance among flexibility, interaction depth, and deceptive capability. The field evaluation further validates HoneyGPT's efficacy, showing its marked superiority in enticing attackers into more profound interactive engagements and capturing a wider array of novel attack vectors in comparison to existing honeypot technologies.
A Novel Framework for Multimodal Named Entity Recognition with Multi-level Alignments
May 15, 2023



Mining structured knowledge from tweets using named entity recognition (NER) can be beneficial for many downstream applications such as recommendation and intention under standing. With tweet posts tending to be multimodal, multimodal named entity recognition (MNER) has attracted more attention. In this paper, we propose a novel approach, which can dynamically align the image and text sequence and achieve the multi-level cross-modal learning to augment textual word representation for MNER improvement. To be specific, our framework can be split into three main stages: the first stage focuses on intra-modality representation learning to derive the implicit global and local knowledge of each modality, the second evaluates the relevance between the text and its accompanying image and integrates different grained visual information based on the relevance, the third enforces semantic refinement via iterative cross-modal interactions and co-attention. We conduct experiments on two open datasets, and the results and detailed analysis demonstrate the advantage of our model.
Improving the Modality Representation with Multi-View Contrastive Learning for Multimodal Sentiment Analysis
Oct 28, 2022


Modality representation learning is an important problem for multimodal sentiment analysis (MSA), since the highly distinguishable representations can contribute to improving the analysis effect. Previous works of MSA have usually focused on multimodal fusion strategies, and the deep study of modal representation learning was given less attention. Recently, contrastive learning has been confirmed effective at endowing the learned representation with stronger discriminate ability. Inspired by this, we explore the improvement approaches of modality representation with contrastive learning in this study. To this end, we devise a three-stages framework with multi-view contrastive learning to refine representations for the specific objectives. At the first stage, for the improvement of unimodal representations, we employ the supervised contrastive learning to pull samples within the same class together while the other samples are pushed apart. At the second stage, a self-supervised contrastive learning is designed for the improvement of the distilled unimodal representations after cross-modal interaction. At last, we leverage again the supervised contrastive learning to enhance the fused multimodal representation. After all the contrast trainings, we next achieve the classification task based on frozen representations. We conduct experiments on three open datasets, and results show the advance of our model.
CEntRE: A paragraph-level Chinese dataset for Relation Extraction among Enterprises
Oct 19, 2022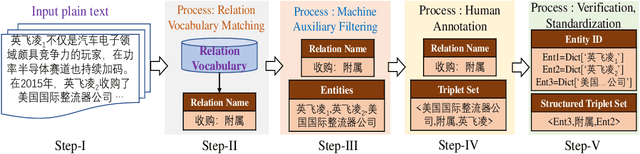

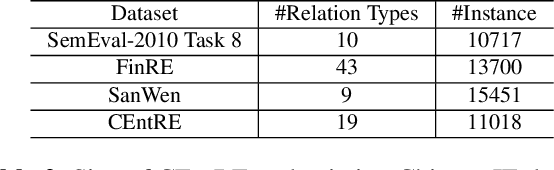

Enterprise relation extraction aims to detect pairs of enterprise entities and identify the business relations between them from unstructured or semi-structured text data, and it is crucial for several real-world applications such as risk analysis, rating research and supply chain security. However, previous work mainly focuses on getting attribute information about enterprises like personnel and corporate business, and pays little attention to enterprise relation extraction. To encourage further progress in the research, we introduce the CEntRE, a new dataset constructed from publicly available business news data with careful human annotation and intelligent data processing. Extensive experiments on CEntRE with six excellent models demonstrate the challenges of our proposed dataset.
Neural Modal ODEs: Integrating Physics-based Modeling with Neural ODEs for Modeling High Dimensional Monitored Structures
Jul 16, 2022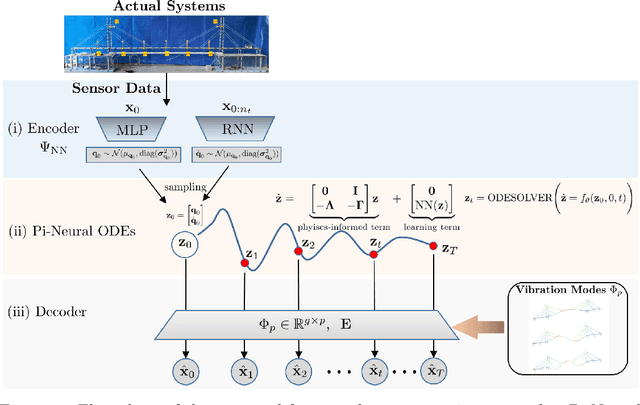
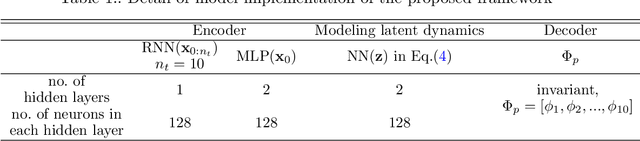
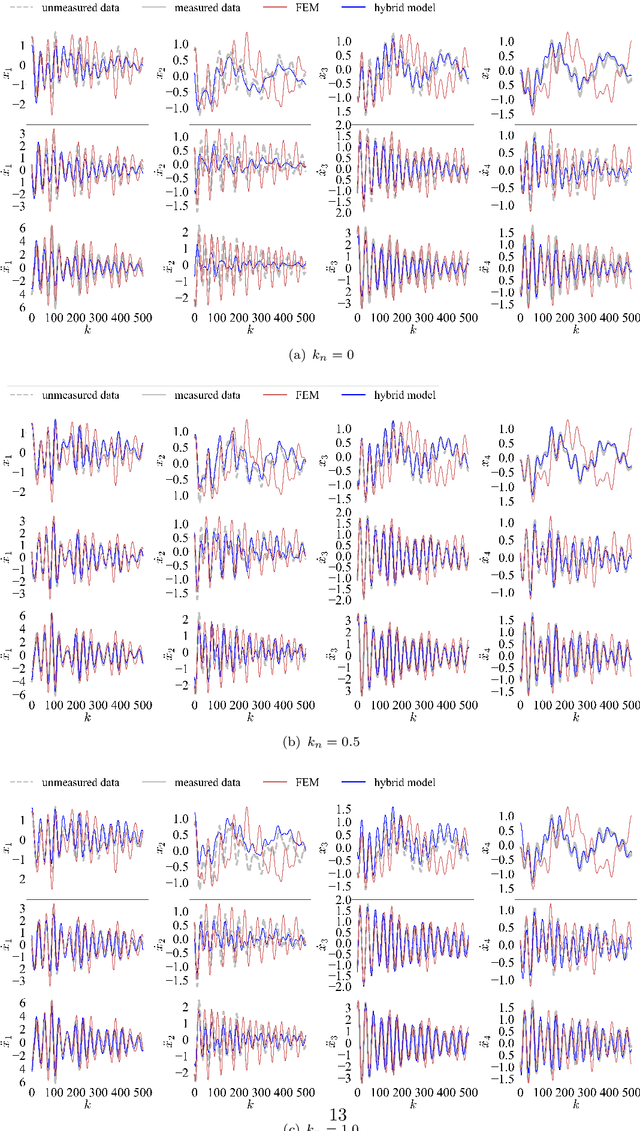
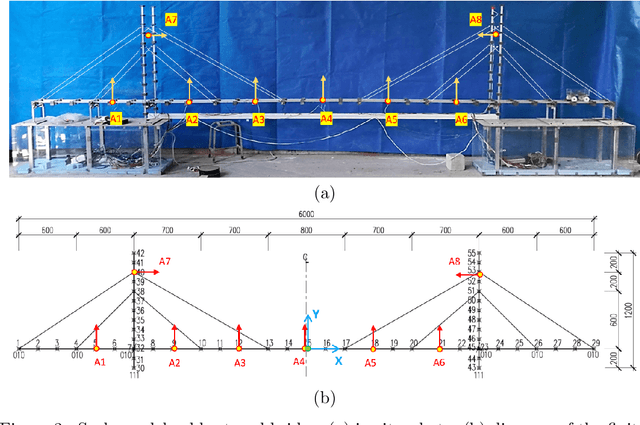
The order/dimension of models derived on the basis of data is commonly restricted by the number of observations, or in the context of monitored systems, sensing nodes. This is particularly true for structural systems (e.g. civil or mechanical structures), which are typically high-dimensional in nature. In the scope of physics-informed machine learning, this paper proposes a framework - termed Neural Modal ODEs - to integrate physics-based modeling with deep learning (particularly, Neural Ordinary Differential Equations -- Neural ODEs) for modeling the dynamics of monitored and high-dimensional engineered systems. In this initiating exploration, we restrict ourselves to linear or mildly nonlinear systems. We propose an architecture that couples a dynamic version of variational autoencoders with physics-informed Neural ODEs (Pi-Neural ODEs). An encoder, as a part of the autoencoder, learns the abstract mappings from the first few items of observational data to the initial values of the latent variables, which drive the learning of embedded dynamics via physics-informed Neural ODEs, imposing a \textit{modal model} structure to that latent space. The decoder of the proposed model adopts the eigenmodes derived from an eigen-analysis applied to the linearized portion of a physics-based model: a process implicitly carrying the spatial relationship between degrees-of-freedom (DOFs). The framework is validated on a numerical example, and an experimental dataset of a scaled cable-stayed bridge, where the learned hybrid model is shown to outperform a purely physics-based approach to modeling. We further show the functionality of the proposed scheme within the context of virtual sensing, i.e., the recovery of generalized response quantities in unmeasured DOFs from spatially sparse data.
Threat Detection for General Social Engineering Attack Using Machine Learning Techniques
Mar 17, 2022



This paper explores the threat detection for general Social Engineering (SE) attack using Machine Learning (ML) techniques, rather than focusing on or limited to a specific SE attack type, e.g. email phishing. Firstly, this paper processes and obtains more SE threat data from the previous Knowledge Graph (KG), and then extracts different threat features and generates new datasets corresponding with three different feature combinations. Finally, 9 types of ML models are created and trained using the three datasets, respectively, and their performance are compared and analyzed with 27 threat detectors and 270 times of experiments. The experimental results and analyses show that: 1) the ML techniques are feasible in detecting general SE attacks and some ML models are quite effective; ML-based SE threat detection is complementary with KG-based approaches; 2) the generated datasets are usable and the SE domain ontology proposed in previous work can dissect SE attacks and deliver the SE threat features, allowing it to be used as a data model for future research. Besides, more conclusions and analyses about the characteristics of different ML detectors and the datasets are discussed.
Discontinuous Named Entity Recognition as Maximal Clique Discovery
Jun 01, 2021
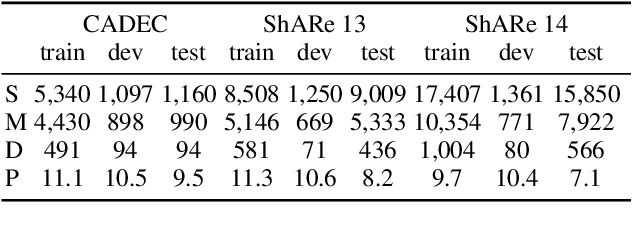
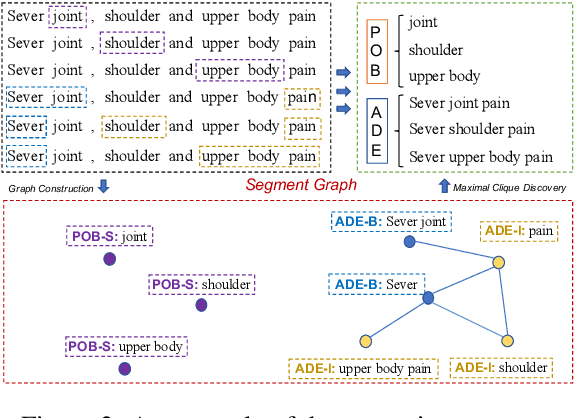
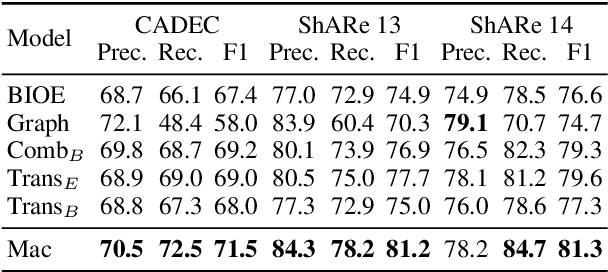
Named entity recognition (NER) remains challenging when entity mentions can be discontinuous. Existing methods break the recognition process into several sequential steps. In training, they predict conditioned on the golden intermediate results, while at inference relying on the model output of the previous steps, which introduces exposure bias. To solve this problem, we first construct a segment graph for each sentence, in which each node denotes a segment (a continuous entity on its own, or a part of discontinuous entities), and an edge links two nodes that belong to the same entity. The nodes and edges can be generated respectively in one stage with a grid tagging scheme and learned jointly using a novel architecture named Mac. Then discontinuous NER can be reformulated as a non-parametric process of discovering maximal cliques in the graph and concatenating the spans in each clique. Experiments on three benchmarks show that our method outperforms the state-of-the-art (SOTA) results, with up to 3.5 percentage points improvement on F1, and achieves 5x speedup over the SOTA model.
TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
Oct 26, 2020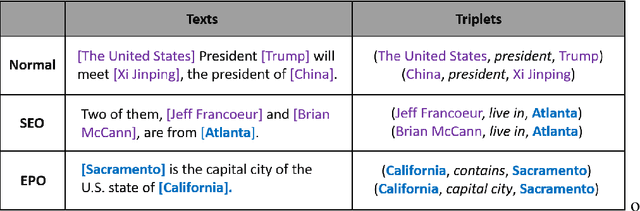

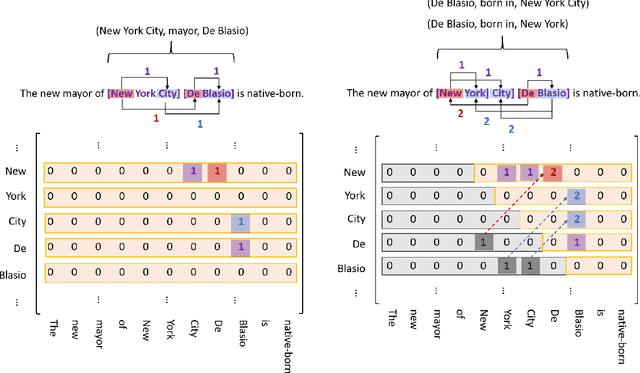

Extracting entities and relations from unstructured text has attracted increasing attention in recent years but remains challenging, due to the intrinsic difficulty in identifying overlapping relations with shared entities. Prior works show that joint learning can result in a noticeable performance gain. However, they usually involve sequential interrelated steps and suffer from the problem of exposure bias. At training time, they predict with the ground truth conditions while at inference it has to make extraction from scratch. This discrepancy leads to error accumulation. To mitigate the issue, we propose in this paper a one-stage joint extraction model, namely, TPLinker, which is capable of discovering overlapping relations sharing one or both entities while immune from the exposure bias. TPLinker formulates joint extraction as a token pair linking problem and introduces a novel handshaking tagging scheme that aligns the boundary tokens of entity pairs under each relation type. Experiment results show that TPLinker performs significantly better on overlapping and multiple relation extraction, and achieves state-of-the-art performance on two public datasets.