 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Jailbreak Attacks on LLMs through Intent Concealment and Diversion
May 20, 2025Although large language models (LLMs) have achieved remarkable advancements, their security remains a pressing concern. One major threat is jailbreak attacks, where adversarial prompts bypass model safeguards to generate harmful or objectionable content. Researchers study jailbreak attacks to understand security and robustness of LLMs. However, existing jailbreak attack methods face two main challenges: (1) an excessive number of iterative queries, and (2) poor generalization across models. In addition, recent jailbreak evaluation datasets focus primarily on question-answering scenarios, lacking attention to text generation tasks that require accurate regeneration of toxic content. To tackle these challenges, we propose two contributions: (1) ICE, a novel black-box jailbreak method that employs Intent Concealment and divErsion to effectively circumvent security constraints. ICE achieves high attack success rates (ASR) with a single query, significantly improving efficiency and transferability across different models. (2) BiSceneEval, a comprehensive dataset designed for assessing LLM robustness in question-answering and text-generation tasks. Experimental results demonstrate that ICE outperforms existing jailbreak techniques, revealing critical vulnerabilities in current defense mechanisms. Our findings underscore the necessity of a hybrid security strategy that integrates predefined security mechanisms with real-time semantic decomposition to enhance the security of LLMs.
Divide and Conquer: A Hybrid Strategy Defeats Multimodal Large Language Models
Dec 21, 2024Large language models (LLMs) are widely applied in various fields of society due to their powerful reasoning, understanding, and generation capabilities. However, the security issues associated with these models are becoming increasingly severe. Jailbreaking attacks, as an important method for detecting vulnerabilities in LLMs, have been explored by researchers who attempt to induce these models to generate harmful content through various attack methods. Nevertheless, existing jailbreaking methods face numerous limitations, such as excessive query counts, limited coverage of jailbreak modalities, low attack success rates, and simplistic evaluation methods. To overcome these constraints, this paper proposes a multimodal jailbreaking method: JMLLM. This method integrates multiple strategies to perform comprehensive jailbreak attacks across text, visual, and auditory modalities. Additionally, we contribute a new and comprehensive dataset for multimodal jailbreaking research: TriJail, which includes jailbreak prompts for all three modalities. Experiments on the TriJail dataset and the benchmark dataset AdvBench, conducted on 13 popular LLMs, demonstrate advanced attack success rates and significant reduction in time overhead.
Low-Resource Fast Text Classification Based on Intra-Class and Inter-Class Distance Calculation
Dec 13, 2024In recent years, text classification methods based on neural networks and pre-trained models have gained increasing attention and demonstrated excellent performance. However, these methods still have some limitations in practical applications: (1) They typically focus only on the matching similarity between sentences. However, there exists implicit high-value information both within sentences of the same class and across different classes, which is very crucial for classification tasks. (2) Existing methods such as pre-trained language models and graph-based approaches often consume substantial memory for training and text-graph construction. (3) Although some low-resource methods can achieve good performance, they often suffer from excessively long processing times. To address these challenges, we propose a low-resource and fast text classification model called LFTC. Our approach begins by constructing a compressor list for each class to fully mine the regularity information within intra-class data. We then remove redundant information irrelevant to the target classification to reduce processing time. Finally, we compute the similarity distance between text pairs for classification. We evaluate LFTC on 9 publicly available benchmark datasets, and the results demonstrate significant improvements in performance and processing time, especially under limited computational and data resources, highlighting its superior advantages.
GEGA: Graph Convolutional Networks and Evidence Retrieval Guided Attention for Enhanced Document-level Relation Extraction
Jul 31, 2024Document-level relation extraction (DocRE) aims to extract relations between entities from unstructured document text. Compared to sentence-level relation extraction, it requires more complex semantic understanding from a broader text context. Currently, some studies are utilizing logical rules within evidence sentences to enhance the performance of DocRE. However, in the data without provided evidence sentences, researchers often obtain a list of evidence sentences for the entire document through evidence retrieval (ER). Therefore, DocRE suffers from two challenges: firstly, the relevance between evidence and entity pairs is weak; secondly, there is insufficient extraction of complex cross-relations between long-distance multi-entities. To overcome these challenges, we propose GEGA, a novel model for DocRE. The model leverages graph neural networks to construct multiple weight matrices, guiding attention allocation to evidence sentences. It also employs multi-scale representation aggregation to enhance ER. Subsequently, we integrate the most efficient evidence information to implement both fully supervised and weakly supervised training processes for the model. We evaluate the GEGA model on three widely used benchmark datasets: DocRED, Re-DocRED, and Revisit-DocRED. The experimental results indicate that our model has achieved comprehensive improvements compared to the existing SOTA model.
Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning
Apr 10, 2024



Few-shot named entity recognition can identify new types of named entities based on a few labeled examples. Previous methods employing token-level or span-level metric learning suffer from the computational burden and a large number of negative sample spans. In this paper, we propose the Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning (MsFNER), which splits the general NER into two stages: entity-span detection and entity classification. There are 3 processes for introducing MsFNER: training, finetuning, and inference. In the training process, we train and get the best entity-span detection model and the entity classification model separately on the source domain using meta-learning, where we create a contrastive learning module to enhance entity representations for entity classification. During finetuning, we finetune the both models on the support dataset of target domain. In the inference process, for the unlabeled data, we first detect the entity-spans, then the entity-spans are jointly determined by the entity classification model and the KNN. We conduct experiments on the open FewNERD dataset and the results demonstrate the advance of MsFNER.
A Novel Framework for Multimodal Named Entity Recognition with Multi-level Alignments
May 15, 2023



Mining structured knowledge from tweets using named entity recognition (NER) can be beneficial for many downstream applications such as recommendation and intention under standing. With tweet posts tending to be multimodal, multimodal named entity recognition (MNER) has attracted more attention. In this paper, we propose a novel approach, which can dynamically align the image and text sequence and achieve the multi-level cross-modal learning to augment textual word representation for MNER improvement. To be specific, our framework can be split into three main stages: the first stage focuses on intra-modality representation learning to derive the implicit global and local knowledge of each modality, the second evaluates the relevance between the text and its accompanying image and integrates different grained visual information based on the relevance, the third enforces semantic refinement via iterative cross-modal interactions and co-attention. We conduct experiments on two open datasets, and the results and detailed analysis demonstrate the advantage of our model.
Improving the Modality Representation with Multi-View Contrastive Learning for Multimodal Sentiment Analysis
Oct 28, 2022


Modality representation learning is an important problem for multimodal sentiment analysis (MSA), since the highly distinguishable representations can contribute to improving the analysis effect. Previous works of MSA have usually focused on multimodal fusion strategies, and the deep study of modal representation learning was given less attention. Recently, contrastive learning has been confirmed effective at endowing the learned representation with stronger discriminate ability. Inspired by this, we explore the improvement approaches of modality representation with contrastive learning in this study. To this end, we devise a three-stages framework with multi-view contrastive learning to refine representations for the specific objectives. At the first stage, for the improvement of unimodal representations, we employ the supervised contrastive learning to pull samples within the same class together while the other samples are pushed apart. At the second stage, a self-supervised contrastive learning is designed for the improvement of the distilled unimodal representations after cross-modal interaction. At last, we leverage again the supervised contrastive learning to enhance the fused multimodal representation. After all the contrast trainings, we next achieve the classification task based on frozen representations. We conduct experiments on three open datasets, and results show the advance of our model.
CEntRE: A paragraph-level Chinese dataset for Relation Extraction among Enterprises
Oct 19, 2022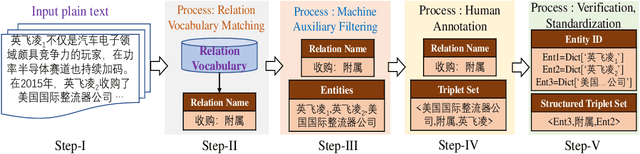

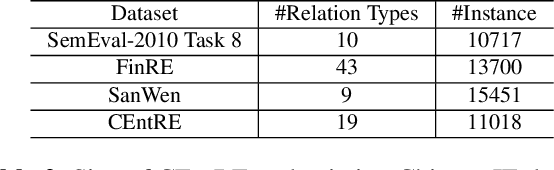

Enterprise relation extraction aims to detect pairs of enterprise entities and identify the business relations between them from unstructured or semi-structured text data, and it is crucial for several real-world applications such as risk analysis, rating research and supply chain security. However, previous work mainly focuses on getting attribute information about enterprises like personnel and corporate business, and pays little attention to enterprise relation extraction. To encourage further progress in the research, we introduce the CEntRE, a new dataset constructed from publicly available business news data with careful human annotation and intelligent data processing. Extensive experiments on CEntRE with six excellent models demonstrate the challenges of our proposed dataset.
Multi-features based Semantic Augmentation Networks for Named Entity Recognition in Threat Intelligence
Jul 01, 2022



Extracting cybersecurity entities such as attackers and vulnerabilities from unstructured network texts is an important part of security analysis. However, the sparsity of intelligence data resulted from the higher frequency variations and the randomness of cybersecurity entity names makes it difficult for current methods to perform well in extracting security-related concepts and entities. To this end, we propose a semantic augmentation method which incorporates different linguistic features to enrich the representation of input tokens to detect and classify the cybersecurity names over unstructured text. In particular, we encode and aggregate the constituent feature, morphological feature and part of speech feature for each input token to improve the robustness of the method. More than that, a token gets augmented semantic information from its most similar K words in cybersecurity domain corpus where an attentive module is leveraged to weigh differences of the words, and from contextual clues based on a large-scale general field corpus. We have conducted experiments on the cybersecurity datasets DNRTI and MalwareTextDB, and the results demonstrate the effectiveness of the proposed method.