 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-TGExplainer: Disentangling Stability and Transition Patterns for Temporal GNN Interpretability
May 19, 2026Temporal graph neural networks (TGNNs) have gained significant traction for solving real-world temporal graph tasks. However, their interpretability remains limited, as most TGNNs fail to identify which historical interactions most influence a given prediction. Despite promising progress on interpretable TGNNs, existing methods predominantly focus on previously seen historical interactions, which we term stability patterns, while overlooking newly emerging first-time interactions, which we term transition patterns. Both types of patterns are essential for faithful temporal explanations. To address this limitation, we propose ST-TGExplainer, a self-explainable TGNN that disentangles Stability and Transition patterns in temporal graphs for a more faithful Temporal GNN Explainer. Guided by a disentangled information bottleneck objective, ST-TGExplainer learns a compact explanatory subgraph that remains predictive of the event label while explicitly suppressing label-conditioned redundancy between stability and transition patterns. Extensive experiments demonstrate that ST-TGExplainer achieves strong predictive performance and yields more faithful explanations. Code is available at https://github.com/hjchen-hdu/ST-TGExplainer.
Bridging Sequence and Graph Structure for Epigenetic Age Prediction
May 11, 2026Epigenetic clocks based on DNA methylation have emerged as powerful tools for estimating biological age, with broad applications in aging research, age-related disease studies, and longevity science. Despite advances across machine learning approaches to epigenetic age prediction, spanning penalised linear regression, deep feedforward networks, residual architectures, and graph neural networks, no existing method jointly models co-methylation graph structure and site-specific DNA sequence context within a unified framework. We propose a unified sequence--graph integration framework for epigenetic age prediction that addresses this gap, integrating eight-dimensional DNA sequence statistical features through a lightweight gated modulation mechanism that adaptively scales each site's methylation signal according to its sequence-determined biological relevance prior to graph convolution. Evaluated on 3,707 blood methylation samples against a comprehensive set of baselines, our method achieves a test MAE of 3.149 years, a 12.8\% improvement over the strongest graph-based baseline. Biologically informed statistical features outperform CNN-based sequence encoding, demonstrating that handcrafted sequence features are more effective than end-to-end learned representations in this data regime. Post-hoc interpretability analysis identifies CpG density and local adenine frequency as features with age-dependent importance shifts, consistent with known mechanisms of age-related hypermethylation at CpG-dense promoter regions. Our code is at https://github.com/yaoli2022/graphage-seq.
GoAgent: Group-of-Agents Communication Topology Generation for LLM-based Multi-Agent Systems
Mar 20, 2026Large language model (LLM)-based multi-agent systems (MAS) have demonstrated exceptional capabilities in solving complex tasks, yet their effectiveness depends heavily on the underlying communication topology that coordinates agent interactions. Within these systems, successful problem-solving often necessitates task-specific group structures to divide and conquer subtasks. However, most existing approaches generate communication topologies in a node-centric manner, leaving group structures to emerge implicitly from local connectivity decisions rather than modeling them explicitly, often leading to suboptimal coordination and unnecessary communication overhead. To address this limitation, we propose GoAgent (Group-of-Agents), a communication topology generation method that explicitly treats collaborative groups as the atomic units of MAS construction. Specifically, GoAgent first enumerates task-relevant candidate groups through an LLM and then autoregressively selects and connects these groups as atomic units to construct the final communication graph, jointly capturing intra-group cohesion and inter-group coordination. To mitigate communication redundancy and noise propagation inherent in expanding topologies, we further introduce a conditional information bottleneck (CIB) objective that compresses inter-group communication, preserving task-relevant signals while filtering out redundant historical noise. Extensive experiments on six benchmarks demonstrate the state-of-the-art performance of GoAgent with 93.84% average accuracy while reducing token consumption by about 17%.
Spiking Graph Predictive Coding for Reliable OOD Generalization
Feb 22, 2026Graphs provide a powerful basis for modeling Web-based relational data, with expressive GNNs to support the effective learning in dynamic web environments. However, real-world deployment is hindered by pervasive out-of-distribution (OOD) shifts, where evolving user activity and changing content semantics alter feature distributions and labeling criteria. These shifts often lead to unstable or overconfident predictions, undermining the trustworthiness required for Web4Good applications. Achieving reliable OOD generalization demands principled and interpretable uncertainty estimation; however, existing methods are largely post-hoc, insensitive to distribution shifts, and unable to explain where uncertainty arises especially in high-stakes settings. To address these limitations, we introduce SpIking GrapH predicTive coding (SIGHT), an uncertainty-aware plug-in graph learning module for reliable OOD Generalization. SIGHT performs iterative, error-driven correction over spiking graph states, enabling models to expose internal mismatch signals that reveal where predictions become unreliable. Across multiple graph benchmarks and diverse OOD scenarios, SIGHT consistently enhances predictive accuracy, uncertainty estimation, and interpretability when integrated with GNNs.
Momentum LMS Theory beyond Stationarity: Stability, Tracking, and Regret
Feb 12, 2026In large-scale data processing scenarios, data often arrive in sequential streams generated by complex systems that exhibit drifting distributions and time-varying system parameters. This nonstationarity challenges theoretical analysis, as it violates classical assumptions of i.i.d. (independent and identically distributed) samples, necessitating algorithms capable of real-time updates without expensive retraining. An effective approach should process each sample in a single pass, while maintaining computational and memory complexities independent of the data stream length. Motivated by these challenges, this paper investigates the Momentum Least Mean Squares (MLMS) algorithm as an adaptive identification tool, leveraging its computational simplicity and online processing capabilities. Theoretically, we derive tracking performance and regret bounds for the MLMS in time-varying stochastic linear systems under various practical conditions. Unlike classical LMS, whose stability can be characterized by first-order random vector difference equations, MLMS introduces an additional dynamical state due to momentum, leading to second-order time-varying random vector difference equations whose stability analysis hinges on more complicated products of random matrices, which poses a substantially challenging problem to resolve. Experiments on synthetic and real-world data streams demonstrate that MLMS achieves rapid adaptation and robust tracking, in agreement with our theoretical results especially in nonstationary settings, highlighting its promise for modern streaming and online learning applications.
OASIS: Harnessing Diffusion Adversarial Network for Ocean Salinity Imputation using Sparse Drifter Trajectories
Aug 29, 2025Ocean salinity plays a vital role in circulation, climate, and marine ecosystems, yet its measurement is often sparse, irregular, and noisy, especially in drifter-based datasets. Traditional approaches, such as remote sensing and optimal interpolation, rely on linearity and stationarity, and are limited by cloud cover, sensor drift, and low satellite revisit rates. While machine learning models offer flexibility, they often fail under severe sparsity and lack principled ways to incorporate physical covariates without specialized sensors. In this paper, we introduce the OceAn Salinity Imputation System (OASIS), a novel diffusion adversarial framework designed to address these challenges.
Explain Before You Answer: A Survey on Compositional Visual Reasoning
Aug 24, 2025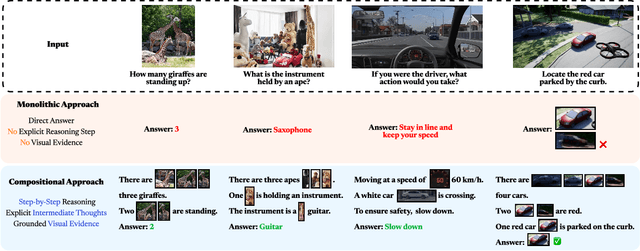
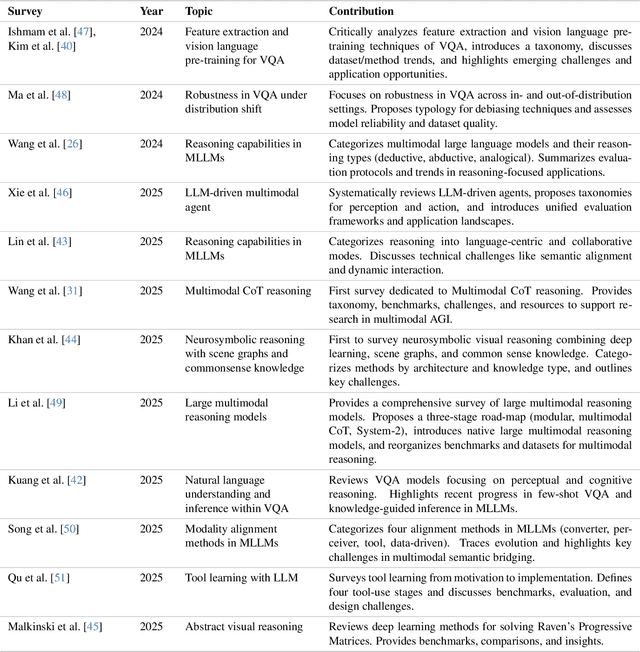
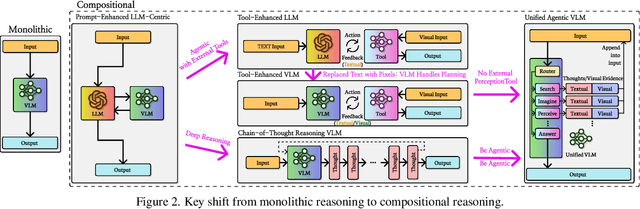
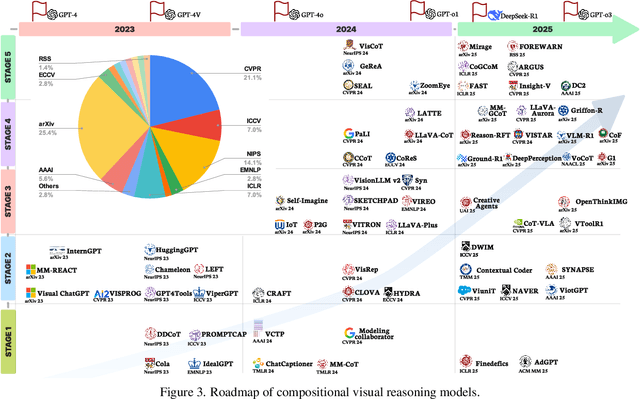
Compositional visual reasoning has emerged as a key research frontier in multimodal AI, aiming to endow machines with the human-like ability to decompose visual scenes, ground intermediate concepts, and perform multi-step logical inference. While early surveys focus on monolithic vision-language models or general multimodal reasoning, a dedicated synthesis of the rapidly expanding compositional visual reasoning literature is still missing. We fill this gap with a comprehensive survey spanning 2023 to 2025 that systematically reviews 260+ papers from top venues (CVPR, ICCV, NeurIPS, ICML, ACL, etc.). We first formalize core definitions and describe why compositional approaches offer advantages in cognitive alignment, semantic fidelity, robustness, interpretability, and data efficiency. Next, we trace a five-stage paradigm shift: from prompt-enhanced language-centric pipelines, through tool-enhanced LLMs and tool-enhanced VLMs, to recently minted chain-of-thought reasoning and unified agentic VLMs, highlighting their architectural designs, strengths, and limitations. We then catalog 60+ benchmarks and corresponding metrics that probe compositional visual reasoning along dimensions such as grounding accuracy, chain-of-thought faithfulness, and high-resolution perception. Drawing on these analyses, we distill key insights, identify open challenges (e.g., limitations of LLM-based reasoning, hallucination, a bias toward deductive reasoning, scalable supervision, tool integration, and benchmark limitations), and outline future directions, including world-model integration, human-AI collaborative reasoning, and richer evaluation protocols. By offering a unified taxonomy, historical roadmap, and critical outlook, this survey aims to serve as a foundational reference and inspire the next generation of compositional visual reasoning research.
Adaptive Sentencing Prediction with Guaranteed Accuracy and Legal Interpretability
May 20, 2025



Existing research on judicial sentencing prediction predominantly relies on end-to-end models, which often neglect the inherent sentencing logic and lack interpretability-a critical requirement for both scholarly research and judicial practice. To address this challenge, we make three key contributions:First, we propose a novel Saturated Mechanistic Sentencing (SMS) model, which provides inherent legal interpretability by virtue of its foundation in China's Criminal Law. We also introduce the corresponding Momentum Least Mean Squares (MLMS) adaptive algorithm for this model. Second, for the MLMS algorithm based adaptive sentencing predictor, we establish a mathematical theory on the accuracy of adaptive prediction without resorting to any stationarity and independence assumptions on the data. We also provide a best possible upper bound for the prediction accuracy achievable by the best predictor designed in the known parameters case. Third, we construct a Chinese Intentional Bodily Harm (CIBH) dataset. Utilizing this real-world data, extensive experiments demonstrate that our approach achieves a prediction accuracy that is not far from the best possible theoretical upper bound, validating both the model's suitability and the algorithm's accuracy.
A Label-Free Heterophily-Guided Approach for Unsupervised Graph Fraud Detection
Feb 18, 2025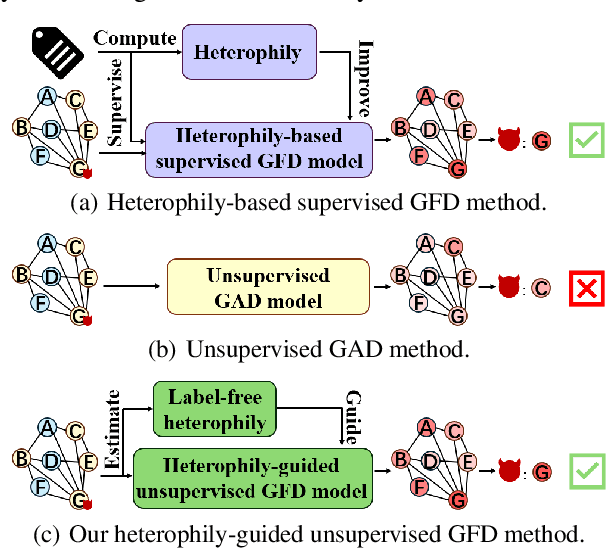

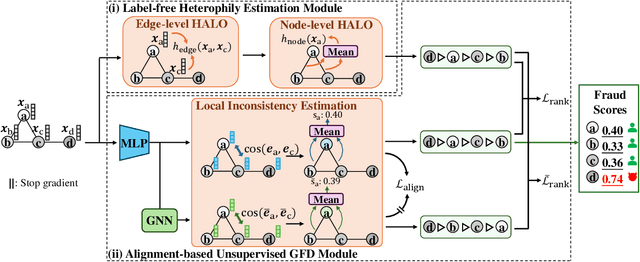
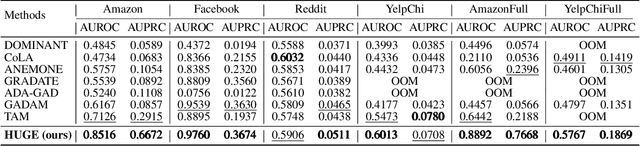
Graph fraud detection (GFD) has rapidly advanced in protecting online services by identifying malicious fraudsters. Recent supervised GFD research highlights that heterophilic connections between fraudsters and users can greatly impact detection performance, since fraudsters tend to camouflage themselves by building more connections to benign users. Despite the promising performance of supervised GFD methods, the reliance on labels limits their applications to unsupervised scenarios; Additionally, accurately capturing complex and diverse heterophily patterns without labels poses a further challenge. To fill the gap, we propose a Heterophily-guided Unsupervised Graph fraud dEtection approach (HUGE) for unsupervised GFD, which contains two essential components: a heterophily estimation module and an alignment-based fraud detection module. In the heterophily estimation module, we design a novel label-free heterophily metric called HALO, which captures the critical graph properties for GFD, enabling its outstanding ability to estimate heterophily from node attributes. In the alignment-based fraud detection module, we develop a joint MLP-GNN architecture with ranking loss and asymmetric alignment loss. The ranking loss aligns the predicted fraud score with the relative order of HALO, providing an extra robustness guarantee by comparing heterophily among non-adjacent nodes. Moreover, the asymmetric alignment loss effectively utilizes structural information while alleviating the feature-smooth effects of GNNs.Extensive experiments on 6 datasets demonstrate that HUGE significantly outperforms competitors, showcasing its effectiveness and robustness. The source code of HUGE is at https://github.com/CampanulaBells/HUGE-GAD.
FedSA: A Unified Representation Learning via Semantic Anchors for Prototype-based Federated Learning
Jan 09, 2025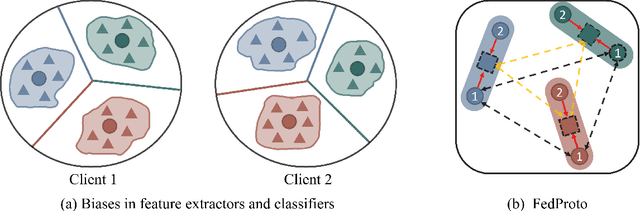



Prototype-based federated learning has emerged as a promising approach that shares lightweight prototypes to transfer knowledge among clients with data heterogeneity in a model-agnostic manner. However, existing methods often collect prototypes directly from local models, which inevitably introduce inconsistencies into representation learning due to the biased data distributions and differing model architectures among clients. In this paper, we identify that both statistical and model heterogeneity create a vicious cycle of representation inconsistency, classifier divergence, and skewed prototype alignment, which negatively impacts the performance of clients. To break the vicious cycle, we propose a novel framework named Federated Learning via Semantic Anchors (FedSA) to decouple the generation of prototypes from local representation learning. We introduce a novel perspective that uses simple yet effective semantic anchors serving as prototypes to guide local models in learning consistent representations. By incorporating semantic anchors, we further propose anchor-based regularization with margin-enhanced contrastive learning and anchor-based classifier calibration to correct feature extractors and calibrate classifiers across clients, achieving intra-class compactness and inter-class separability of prototypes while ensuring consistent decision boundaries. We then update the semantic anchors with these consistent and discriminative prototypes, which iteratively encourage clients to collaboratively learn a unified data representation with robust generalization. Extensive experiments under both statistical and model heterogeneity settings show that FedSA significantly outperforms existing prototype-based FL methods on various classification tasks.