 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-to-Text Benchmark '24: Lessons Learned
Dec 23, 2024

Speech brain-computer interfaces aim to decipher what a person is trying to say from neural activity alone, restoring communication to people with paralysis who have lost the ability to speak intelligibly. The Brain-to-Text Benchmark '24 and associated competition was created to foster the advancement of decoding algorithms that convert neural activity to text. Here, we summarize the lessons learned from the competition ending on June 1, 2024 (the top 4 entrants also presented their experiences in a recorded webinar). The largest improvements in accuracy were achieved using an ensembling approach, where the output of multiple independent decoders was merged using a fine-tuned large language model (an approach used by all 3 top entrants). Performance gains were also found by improving how the baseline recurrent neural network (RNN) model was trained, including by optimizing learning rate scheduling and by using a diphone training objective. Improving upon the model architecture itself proved more difficult, however, with attempts to use deep state space models or transformers not yet appearing to offer a benefit over the RNN baseline. The benchmark will remain open indefinitely to support further work towards increasing the accuracy of brain-to-text algorithms.
Brain-to-Text Decoding with Context-Aware Neural Representations and Large Language Models
Nov 16, 2024



Decoding attempted speech from neural activity offers a promising avenue for restoring communication abilities in individuals with speech impairments. Previous studies have focused on mapping neural activity to text using phonemes as the intermediate target. While successful, decoding neural activity directly to phonemes ignores the context dependent nature of the neural activity-to-phoneme mapping in the brain, leading to suboptimal decoding performance. In this work, we propose the use of diphone - an acoustic representation that captures the transitions between two phonemes - as the context-aware modeling target. We integrate diphones into existing phoneme decoding frameworks through a novel divide-and-conquer strategy in which we model the phoneme distribution by marginalizing over the diphone distribution. Our approach effectively leverages the enhanced context-aware representation of diphones while preserving the manageable class size of phonemes, a key factor in simplifying the subsequent phoneme-to-text conversion task. We demonstrate the effectiveness of our approach on the Brain-to-Text 2024 benchmark, where it achieves state-of-the-art Phoneme Error Rate (PER) of 15.34% compared to 16.62% PER of monophone-based decoding. When coupled with finetuned Large Language Models (LLMs), our method yields a Word Error Rate (WER) of 5.77%, significantly outperforming the 8.93% WER of the leading method in the benchmark.
Towards a Quantitative Analysis of Coarticulation with a Phoneme-to-Articulatory Model
Aug 10, 2024Prior coarticulation studies focus mainly on limited phonemic sequences and specific articulators, providing only approximate descriptions of the temporal extent and magnitude of coarticulation. This paper is an initial attempt to comprehensively investigate coarticulation. We leverage existing Electromagnetic Articulography (EMA) datasets to develop and train a phoneme-to-articulatory (P2A) model that can generate realistic EMA for novel phoneme sequences and replicate known coarticulation patterns. We use model-generated EMA on 9K minimal word pairs to analyze coarticulation magnitude and extent up to eight phonemes from the coarticulation trigger, and compare coarticulation resistance across different consonants. Our findings align with earlier studies and suggest a longer-range coarticulation effect than previously found. This model-based approach can potentially compare coarticulation between adults and children and across languages, offering new insights into speech production.
Plug-and-Play Stability for Intracortical Brain-Computer Interfaces: A One-Year Demonstration of Seamless Brain-to-Text Communication
Nov 06, 2023Intracortical brain-computer interfaces (iBCIs) have shown promise for restoring rapid communication to people with neurological disorders such as amyotrophic lateral sclerosis (ALS). However, to maintain high performance over time, iBCIs typically need frequent recalibration to combat changes in the neural recordings that accrue over days. This requires iBCI users to stop using the iBCI and engage in supervised data collection, making the iBCI system hard to use. In this paper, we propose a method that enables self-recalibration of communication iBCIs without interrupting the user. Our method leverages large language models (LMs) to automatically correct errors in iBCI outputs. The self-recalibration process uses these corrected outputs ("pseudo-labels") to continually update the iBCI decoder online. Over a period of more than one year (403 days), we evaluated our Continual Online Recalibration with Pseudo-labels (CORP) framework with one clinical trial participant. CORP achieved a stable decoding accuracy of 93.84% in an online handwriting iBCI task, significantly outperforming other baseline methods. Notably, this is the longest-running iBCI stability demonstration involving a human participant. Our results provide the first evidence for long-term stabilization of a plug-and-play, high-performance communication iBCI, addressing a major barrier for the clinical translation of iBCIs.
Learning Physical Graph Representations from Visual Scenes
Jun 24, 2020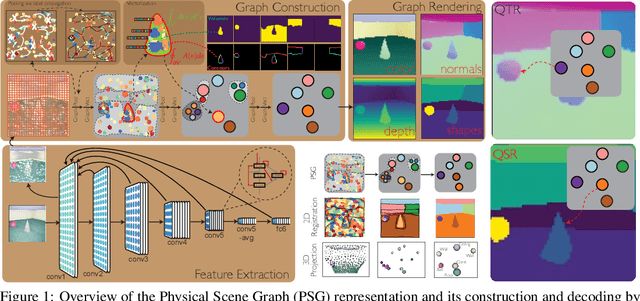
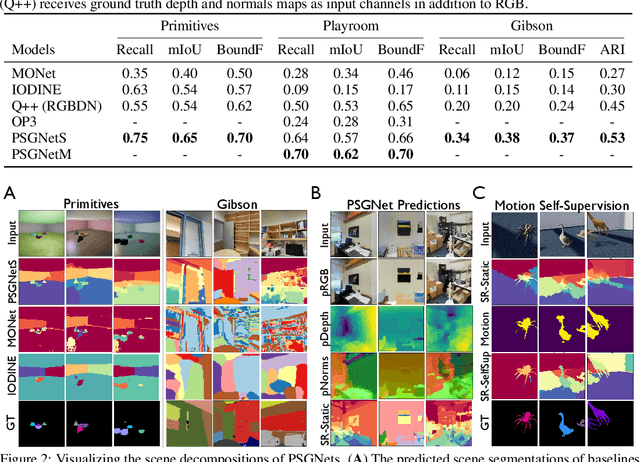
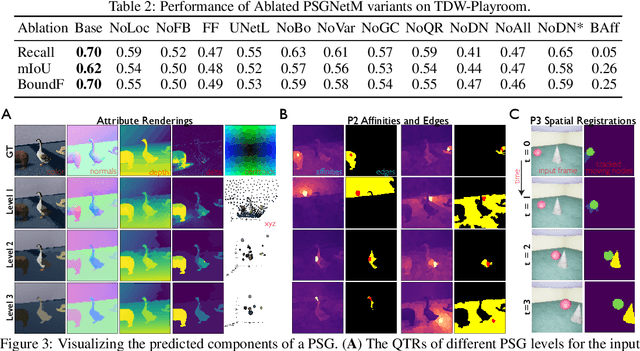

Convolutional Neural Networks (CNNs) have proved exceptional at learning representations for visual object categorization. However, CNNs do not explicitly encode objects, parts, and their physical properties, which has limited CNNs' success on tasks that require structured understanding of visual scenes. To overcome these limitations, we introduce the idea of Physical Scene Graphs (PSGs), which represent scenes as hierarchical graphs, with nodes in the hierarchy corresponding intuitively to object parts at different scales, and edges to physical connections between parts. Bound to each node is a vector of latent attributes that intuitively represent object properties such as surface shape and texture. We also describe PSGNet, a network architecture that learns to extract PSGs by reconstructing scenes through a PSG-structured bottleneck. PSGNet augments standard CNNs by including: recurrent feedback connections to combine low and high-level image information; graph pooling and vectorization operations that convert spatially-uniform feature maps into object-centric graph structures; and perceptual grouping principles to encourage the identification of meaningful scene elements. We show that PSGNet outperforms alternative self-supervised scene representation algorithms at scene segmentation tasks, especially on complex real-world images, and generalizes well to unseen object types and scene arrangements. PSGNet is also able learn from physical motion, enhancing scene estimates even for static images. We present a series of ablation studies illustrating the importance of each component of the PSGNet architecture, analyses showing that learned latent attributes capture intuitive scene properties, and illustrate the use of PSGs for compositional scene inference.