 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCore Safety Values for Provably Corrigible Agents
Jul 28, 2025We introduce the first implementable framework for corrigibility, with provable guarantees in multi-step, partially observed environments. Our framework replaces a single opaque reward with five *structurally separate* utility heads -- deference, switch-access preservation, truthfulness, low-impact behavior via a belief-based extension of Attainable Utility Preservation, and bounded task reward -- combined lexicographically by strict weight gaps. Theorem 1 proves exact single-round corrigibility in the partially observable off-switch game; Theorem 3 extends the guarantee to multi-step, self-spawning agents, showing that even if each head is \emph{learned} to mean-squared error $\varepsilon$ and the planner is $\varepsilon$-sub-optimal, the probability of violating \emph{any} safety property is bounded while still ensuring net human benefit. In contrast to Constitutional AI or RLHF/RLAIF, which merge all norms into one learned scalar, our separation makes obedience and impact-limits dominate even when incentives conflict. For open-ended settings where adversaries can modify the agent, we prove that deciding whether an arbitrary post-hack agent will ever violate corrigibility is undecidable by reduction to the halting problem, then carve out a finite-horizon ``decidable island'' where safety can be certified in randomized polynomial time and verified with privacy-preserving, constant-round zero-knowledge proofs. Consequently, the remaining challenge is the ordinary ML task of data coverage and generalization: reward-hacking risk is pushed into evaluation quality rather than hidden incentive leak-through, giving clearer implementation guidance for today's LLM assistants and future autonomous systems.
An AI Capability Threshold for Rent-Funded Universal Basic Income in an AI-Automated Economy
May 24, 2025We derive the first closed-form condition under which artificial intelligence (AI) capital profits could sustainably finance a universal basic income (UBI) without additional taxes or new job creation. In a Solow-Zeira economy characterized by a continuum of automatable tasks, a constant net saving rate $s$, and task-elasticity $\sigma < 1$, we analyze how the AI capability threshold--defined as the productivity level of AI relative to pre-AI automation--varies under different economic scenarios. At present economic parameters, we find that AI systems must achieve only approximately 5-6 times existing automation productivity to finance an 11\%-of-GDP UBI, in the worst case situation where \emph{no} new jobs or tasks are created. Our analysis also reveals some specific policy levers: raising public revenue share (e.g. profit taxation) of AI capital from the current 15\% to about 33\% halves the required AI capability threshold to attain UBI to 3 times existing automotion productivity, but gains diminish beyond 50\% public revenue share, especially if regulatory costs increase. Market structure also strongly affects outcomes: monopolistic or concentrated oligopolistic markets reduce the threshold by increasing economic rents, whereas heightened competition significantly raises it. Overall, these results suggest a couple policy recommendations: maximizing public revenue share up to a point so that operating costs are minimized, and strategically managing market competition can ensure AI's growing capabilities translate into meaningful social benefits within realistic technological progress scenarios.
Task-Optimized Convolutional Recurrent Networks Align with Tactile Processing in the Rodent Brain
May 23, 2025



Tactile sensing remains far less understood in neuroscience and less effective in artificial systems compared to more mature modalities such as vision and language. We bridge these gaps by introducing a novel Encoder-Attender-Decoder (EAD) framework to systematically explore the space of task-optimized temporal neural networks trained on realistic tactile input sequences from a customized rodent whisker-array simulator. We identify convolutional recurrent neural networks (ConvRNNs) as superior encoders to purely feedforward and state-space architectures for tactile categorization. Crucially, these ConvRNN-encoder-based EAD models achieve neural representations closely matching rodent somatosensory cortex, saturating the explainable neural variability and revealing a clear linear relationship between supervised categorization performance and neural alignment. Furthermore, contrastive self-supervised ConvRNN-encoder-based EADs, trained with tactile-specific augmentations, match supervised neural fits, serving as an ethologically-relevant, label-free proxy. For neuroscience, our findings highlight nonlinear recurrent processing as important for general-purpose tactile representations in somatosensory cortex, providing the first quantitative characterization of the underlying inductive biases in this system. For embodied AI, our results emphasize the importance of recurrent EAD architectures to handle realistic tactile inputs, along with tailored self-supervised learning methods for achieving robust tactile perception with the same type of sensors animals use to sense in unstructured environments.
Brain-Model Evaluations Need the NeuroAI Turing Test
Feb 22, 2025What makes an artificial system a good model of intelligence? The classical test proposed by Alan Turing focuses on behavior, requiring that an artificial agent's behavior be indistinguishable from that of a human. While behavioral similarity provides a strong starting point, two systems with very different internal representations can produce the same outputs. Thus, in modeling biological intelligence, the field of NeuroAI often aims to go beyond behavioral similarity and achieve representational convergence between a model's activations and the measured activity of a biological system. This position paper argues that the standard definition of the Turing Test is incomplete for NeuroAI, and proposes a stronger framework called the ``NeuroAI Turing Test'', a benchmark that extends beyond behavior alone and \emph{additionally} requires models to produce internal neural representations that are empirically indistinguishable from those of a brain up to measured individual variability, i.e. the differences between a computational model and the brain is no more than the difference between one brain and another brain. While the brain is not necessarily the ceiling of intelligence, it remains the only universally agreed-upon example, making it a natural reference point for evaluating computational models. By proposing this framework, we aim to shift the discourse from loosely defined notions of brain inspiration to a systematic and testable standard centered on both behavior and internal representations, providing a clear benchmark for neuroscientific modeling and AI development.
Barriers and Pathways to Human-AI Alignment: A Game-Theoretic Approach
Feb 09, 2025Under what conditions can capable AI agents efficiently align their actions with human preferences? More specifically, when they are proficient enough to collaborate with us, how long does coordination take, and when is it computationally feasible? These foundational questions of AI alignment help define what makes an AI agent ``sufficiently safe'' and valuable to humans. Since such generally capable systems do not yet exist, a theoretical analysis is needed to establish when guarantees hold -- and what they even are. We introduce a game-theoretic framework that generalizes prior alignment approaches with fewer assumptions, allowing us to analyze the computational complexity of alignment across $M$ objectives and $N$ agents, providing both upper and lower bounds. Unlike previous work, which often assumes common priors, idealized communication, or implicit tractability, our framework formally characterizes the difficulty of alignment under minimal assumptions. Our main result shows that even when agents are fully rational and computationally \emph{unbounded}, alignment can be achieved with high probability in time \emph{linear} in the task space size. Therefore, in real-world settings, where task spaces are often \emph{exponential} in input length, this remains impractical. More strikingly, our lower bound demonstrates that alignment is \emph{impossible} to speed up when scaling to exponentially many tasks or agents, highlighting a fundamental computational barrier to scalable alignment. Relaxing these idealized assumptions, we study \emph{computationally bounded} agents with noisy messages (representing obfuscated intent), showing that while alignment can still succeed with high probability, it incurs additional \emph{exponential} slowdowns in the task space size, number of agents, and number of tasks. We conclude by identifying conditions that make alignment more feasible.
A Goal-Driven Approach to Systems Neuroscience
Nov 05, 2023Humans and animals exhibit a range of interesting behaviors in dynamic environments, and it is unclear how our brains actively reformat this dense sensory information to enable these behaviors. Experimental neuroscience is undergoing a revolution in its ability to record and manipulate hundreds to thousands of neurons while an animal is performing a complex behavior. As these paradigms enable unprecedented access to the brain, a natural question that arises is how to distill these data into interpretable insights about how neural circuits give rise to intelligent behaviors. The classical approach in systems neuroscience has been to ascribe well-defined operations to individual neurons and provide a description of how these operations combine to produce a circuit-level theory of neural computations. While this approach has had some success for small-scale recordings with simple stimuli, designed to probe a particular circuit computation, often times these ultimately lead to disparate descriptions of the same system across stimuli. Perhaps more strikingly, many response profiles of neurons are difficult to succinctly describe in words, suggesting that new approaches are needed in light of these experimental observations. In this thesis, we offer a different definition of interpretability that we show has promise in yielding unified structural and functional models of neural circuits, and describes the evolutionary constraints that give rise to the response properties of the neural population, including those that have previously been difficult to describe individually. We demonstrate the utility of this framework across multiple brain areas and species to study the roles of recurrent processing in the primate ventral visual pathway; mouse visual processing; heterogeneity in rodent medial entorhinal cortex; and facilitating biological learning.
Neural Foundations of Mental Simulation: Future Prediction of Latent Representations on Dynamic Scenes
May 19, 2023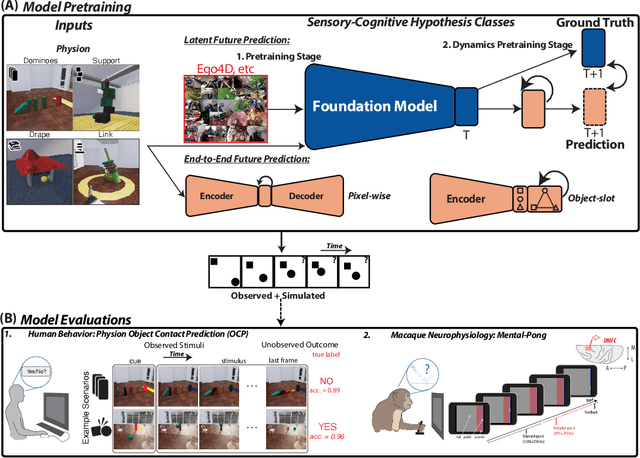
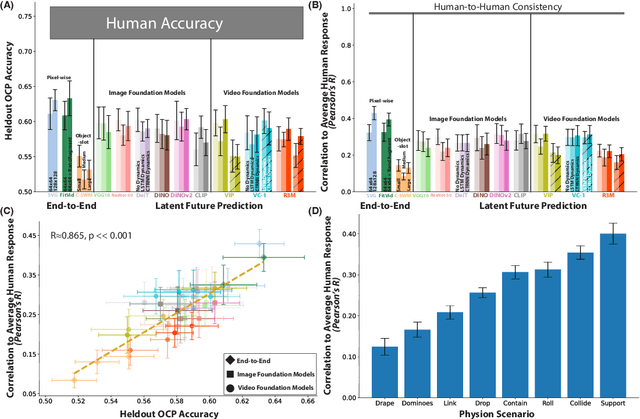
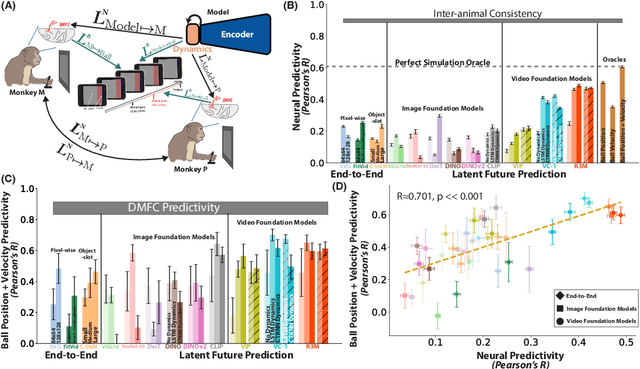
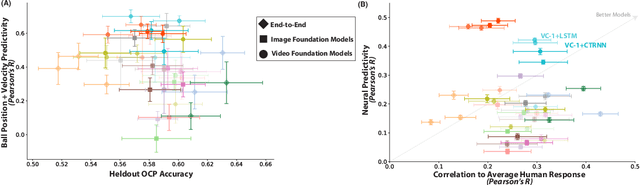
Humans and animals have a rich and flexible understanding of the physical world, which enables them to infer the underlying dynamical trajectories of objects and events, plausible future states, and use that to plan and anticipate the consequences of actions. However, the neural mechanisms underlying these computations are unclear. We combine a goal-driven modeling approach with dense neurophysiological data and high-throughput human behavioral readouts to directly impinge on this question. Specifically, we construct and evaluate several classes of sensory-cognitive networks to predict the future state of rich, ethologically-relevant environments, ranging from self-supervised end-to-end models with pixel-wise or object-centric objectives, to models that future predict in the latent space of purely static image-based or dynamic video-based pretrained foundation models. We find strong differentiation across these model classes in their ability to predict neural and behavioral data both within and across diverse environments. In particular, we find that neural responses are currently best predicted by models trained to predict the future state of their environment in the latent space of pretrained foundation models optimized for dynamic scenes in a self-supervised manner. Notably, models that future predict in the latent space of video foundation models that are optimized to support a diverse range of sensorimotor tasks, reasonably match both human behavioral error patterns and neural dynamics across all environmental scenarios that we were able to test. Overall, these findings suggest that the neural mechanisms and behaviors of primate mental simulation are thus far most consistent with being optimized to future predict on dynamic, reusable visual representations that are useful for embodied AI more generally.
Identifying Learning Rules From Neural Network Observables
Oct 22, 2020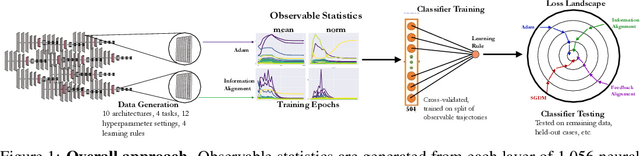


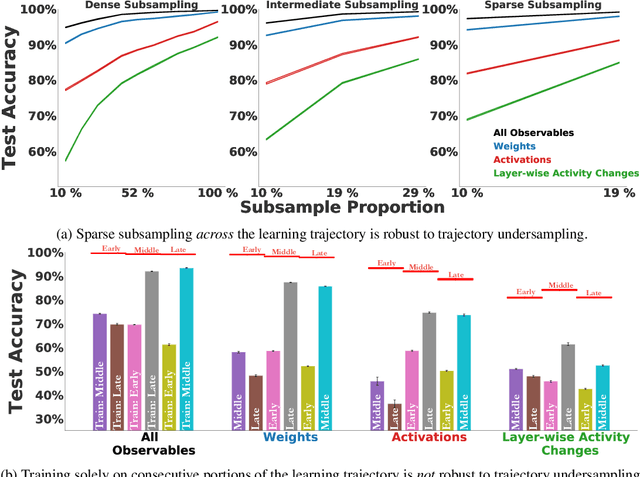
The brain modifies its synaptic strengths during learning in order to better adapt to its environment. However, the underlying plasticity rules that govern learning are unknown. Many proposals have been suggested, including Hebbian mechanisms, explicit error backpropagation, and a variety of alternatives. It is an open question as to what specific experimental measurements would need to be made to determine whether any given learning rule is operative in a real biological system. In this work, we take a "virtual experimental" approach to this problem. Simulating idealized neuroscience experiments with artificial neural networks, we generate a large-scale dataset of learning trajectories of aggregate statistics measured in a variety of neural network architectures, loss functions, learning rule hyperparameters, and parameter initializations. We then take a discriminative approach, training linear and simple non-linear classifiers to identify learning rules from features based on these observables. We show that different classes of learning rules can be separated solely on the basis of aggregate statistics of the weights, activations, or instantaneous layer-wise activity changes, and that these results generalize to limited access to the trajectory and held-out architectures and learning curricula. We identify the statistics of each observable that are most relevant for rule identification, finding that statistics from network activities across training are more robust to unit undersampling and measurement noise than those obtained from the synaptic strengths. Our results suggest that activation patterns, available from electrophysiological recordings of post-synaptic activities on the order of several hundred units, frequently measured at wider intervals over the course of learning, may provide a good basis on which to identify learning rules.
Learning Physical Graph Representations from Visual Scenes
Jun 24, 2020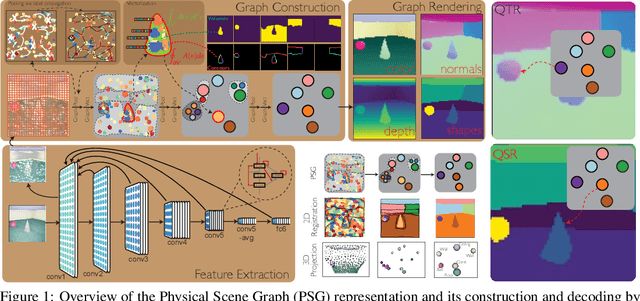
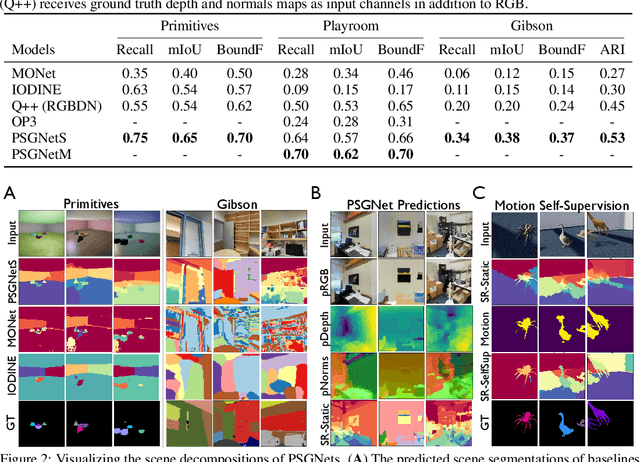
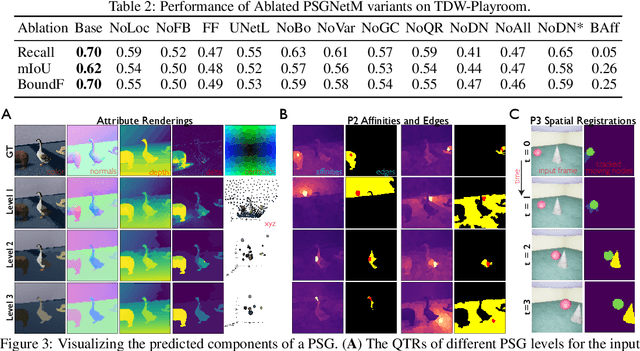

Convolutional Neural Networks (CNNs) have proved exceptional at learning representations for visual object categorization. However, CNNs do not explicitly encode objects, parts, and their physical properties, which has limited CNNs' success on tasks that require structured understanding of visual scenes. To overcome these limitations, we introduce the idea of Physical Scene Graphs (PSGs), which represent scenes as hierarchical graphs, with nodes in the hierarchy corresponding intuitively to object parts at different scales, and edges to physical connections between parts. Bound to each node is a vector of latent attributes that intuitively represent object properties such as surface shape and texture. We also describe PSGNet, a network architecture that learns to extract PSGs by reconstructing scenes through a PSG-structured bottleneck. PSGNet augments standard CNNs by including: recurrent feedback connections to combine low and high-level image information; graph pooling and vectorization operations that convert spatially-uniform feature maps into object-centric graph structures; and perceptual grouping principles to encourage the identification of meaningful scene elements. We show that PSGNet outperforms alternative self-supervised scene representation algorithms at scene segmentation tasks, especially on complex real-world images, and generalizes well to unseen object types and scene arrangements. PSGNet is also able learn from physical motion, enhancing scene estimates even for static images. We present a series of ablation studies illustrating the importance of each component of the PSGNet architecture, analyses showing that learned latent attributes capture intuitive scene properties, and illustrate the use of PSGs for compositional scene inference.
Two Routes to Scalable Credit Assignment without Weight Symmetry
Feb 28, 2020


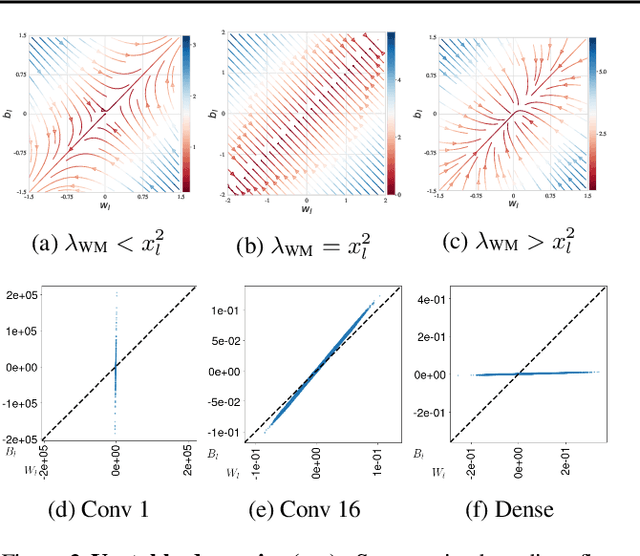
The neural plausibility of backpropagation has long been disputed, primarily for its use of non-local weight transport - the biologically dubious requirement that one neuron instantaneously measure the synaptic weights of another. Until recently, attempts to create local learning rules that avoid weight transport have typically failed in the large-scale learning scenarios where backpropagation shines, e.g. ImageNet categorization with deep convolutional networks. Here, we investigate a recently proposed local learning rule that yields competitive performance with backpropagation and find that it is highly sensitive to metaparameter choices, requiring laborious tuning that does not transfer across network architecture. Our analysis indicates the underlying mathematical reason for this instability, allowing us to identify a more robust local learning rule that better transfers without metaparameter tuning. Nonetheless, we find a performance and stability gap between this local rule and backpropagation that widens with increasing model depth. We then investigate several non-local learning rules that relax the need for instantaneous weight transport into a more biologically-plausible "weight estimation" process, showing that these rules match state-of-the-art performance on deep networks and operate effectively in the presence of noisy updates. Taken together, our results suggest two routes towards the discovery of neural implementations for credit assignment without weight symmetry: further improvement of local rules so that they perform consistently across architectures and the identification of biological implementations for non-local learning mechanisms.