 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Ranking Utility Tuning in the Ad Recommender System at Pinterest
Sep 05, 2025



The ranking utility function in an ad recommender system, which linearly combines predictions of various business goals, plays a central role in balancing values across the platform, advertisers, and users. Traditional manual tuning, while offering simplicity and interpretability, often yields suboptimal results due to its unprincipled tuning objectives, the vast amount of parameter combinations, and its lack of personalization and adaptability to seasonality. In this work, we propose a general Deep Reinforcement Learning framework for Personalized Utility Tuning (DRL-PUT) to address the challenges of multi-objective optimization within ad recommender systems. Our key contributions include: 1) Formulating the problem as a reinforcement learning task: given the state of an ad request, we predict the optimal hyperparameters to maximize a pre-defined reward. 2) Developing an approach to directly learn an optimal policy model using online serving logs, avoiding the need to estimate a value function, which is inherently challenging due to the high variance and unbalanced distribution of immediate rewards. We evaluated DRL-PUT through an online A/B experiment in Pinterest's ad recommender system. Compared to the baseline manual utility tuning approach, DRL-PUT improved the click-through rate by 9.7% and the long click-through rate by 7.7% on the treated segment. We conducted a detailed ablation study on the impact of different reward definitions and analyzed the personalization aspect of the learned policy model.
Requirements Elicitation Follow-Up Question Generation
Jul 03, 2025Interviews are a widely used technique in eliciting requirements to gather stakeholder needs, preferences, and expectations for a software system. Effective interviewing requires skilled interviewers to formulate appropriate interview questions in real time while facing multiple challenges, including lack of familiarity with the domain, excessive cognitive load, and information overload that hinders how humans process stakeholders' speech. Recently, large language models (LLMs) have exhibited state-of-the-art performance in multiple natural language processing tasks, including text summarization and entailment. To support interviewers, we investigate the application of GPT-4o to generate follow-up interview questions during requirements elicitation by building on a framework of common interviewer mistake types. In addition, we describe methods to generate questions based on interviewee speech. We report a controlled experiment to evaluate LLM-generated and human-authored questions with minimal guidance, and a second controlled experiment to evaluate the LLM-generated questions when generation is guided by interviewer mistake types. Our findings demonstrate that, for both experiments, the LLM-generated questions are no worse than the human-authored questions with respect to clarity, relevancy, and informativeness. In addition, LLM-generated questions outperform human-authored questions when guided by common mistakes types. This highlights the potential of using LLMs to help interviewers improve the quality and ease of requirements elicitation interviews in real time.
Task-Optimized Convolutional Recurrent Networks Align with Tactile Processing in the Rodent Brain
May 23, 2025



Tactile sensing remains far less understood in neuroscience and less effective in artificial systems compared to more mature modalities such as vision and language. We bridge these gaps by introducing a novel Encoder-Attender-Decoder (EAD) framework to systematically explore the space of task-optimized temporal neural networks trained on realistic tactile input sequences from a customized rodent whisker-array simulator. We identify convolutional recurrent neural networks (ConvRNNs) as superior encoders to purely feedforward and state-space architectures for tactile categorization. Crucially, these ConvRNN-encoder-based EAD models achieve neural representations closely matching rodent somatosensory cortex, saturating the explainable neural variability and revealing a clear linear relationship between supervised categorization performance and neural alignment. Furthermore, contrastive self-supervised ConvRNN-encoder-based EADs, trained with tactile-specific augmentations, match supervised neural fits, serving as an ethologically-relevant, label-free proxy. For neuroscience, our findings highlight nonlinear recurrent processing as important for general-purpose tactile representations in somatosensory cortex, providing the first quantitative characterization of the underlying inductive biases in this system. For embodied AI, our results emphasize the importance of recurrent EAD architectures to handle realistic tactile inputs, along with tailored self-supervised learning methods for achieving robust tactile perception with the same type of sensors animals use to sense in unstructured environments.
ProTransformer: Robustify Transformers via Plug-and-Play Paradigm
Oct 30, 2024



Transformer-based architectures have dominated various areas of machine learning in recent years. In this paper, we introduce a novel robust attention mechanism designed to enhance the resilience of transformer-based architectures. Crucially, this technique can be integrated into existing transformers as a plug-and-play layer, improving their robustness without the need for additional training or fine-tuning. Through comprehensive experiments and ablation studies, we demonstrate that our ProTransformer significantly enhances the robustness of transformer models across a variety of prediction tasks, attack mechanisms, backbone architectures, and data domains. Notably, without further fine-tuning, the ProTransformer consistently improves the performance of vanilla transformers by 19.5%, 28.3%, 16.1%, and 11.4% for BERT, ALBERT, DistilBERT, and RoBERTa, respectively, under the classical TextFooler attack. Furthermore, ProTransformer shows promising resilience in large language models (LLMs) against prompting-based attacks, improving the performance of T5 and LLaMA by 24.8% and 17.8%, respectively, and enhancing Vicuna by an average of 10.4% against the Jailbreaking attack. Beyond the language domain, ProTransformer also demonstrates outstanding robustness in both vision and graph domains.
Chemistry-Inspired Diffusion with Non-Differentiable Guidance
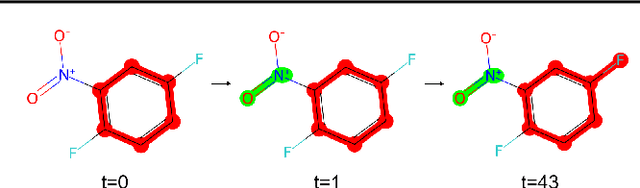
Oct 09, 2024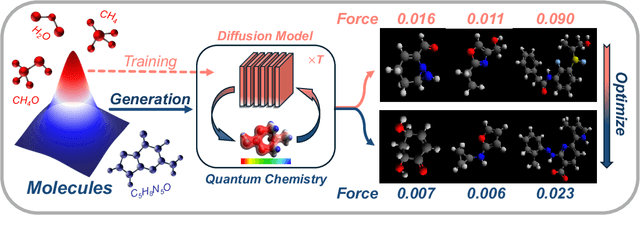

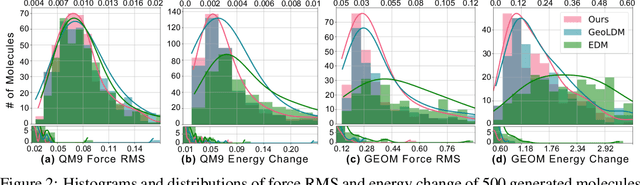

Recent advances in diffusion models have shown remarkable potential in the conditional generation of novel molecules. These models can be guided in two ways: (i) explicitly, through additional features representing the condition, or (ii) implicitly, using a property predictor. However, training property predictors or conditional diffusion models requires an abundance of labeled data and is inherently challenging in real-world applications. We propose a novel approach that attenuates the limitations of acquiring large labeled datasets by leveraging domain knowledge from quantum chemistry as a non-differentiable oracle to guide an unconditional diffusion model. Instead of relying on neural networks, the oracle provides accurate guidance in the form of estimated gradients, allowing the diffusion process to sample from a conditional distribution specified by quantum chemistry. We show that this results in more precise conditional generation of novel and stable molecular structures. Our experiments demonstrate that our method: (1) significantly reduces atomic forces, enhancing the validity of generated molecules when used for stability optimization; (2) is compatible with both explicit and implicit guidance in diffusion models, enabling joint optimization of molecular properties and stability; and (3) generalizes effectively to molecular optimization tasks beyond stability optimization.
Zero-shot Outlier Detection via Prior-data Fitted Networks: Model Selection Bygone!
Sep 09, 2024Outlier detection (OD) has a vast literature as it finds numerous applications in environmental monitoring, cybersecurity, finance, and medicine to name a few. Being an inherently unsupervised task, model selection is a key bottleneck for OD (both algorithm and hyperparameter selection) without label supervision. There is a long list of techniques to choose from -- both classical algorithms and deep neural architectures -- and while several studies report their hyperparameter sensitivity, the literature is quite slim on unsupervised model selection -- limiting the effective use of OD in practice. In this paper we present FoMo-0D, for zero/0-shot OD exploring a transformative new direction that bypasses the hurdle of model selection altogether (!), thus breaking new ground. The fundamental idea behind FoMo-0D is the Prior-data Fitted Networks, recently introduced by Muller et al.(2022), which trains a Transformer model on a large body of synthetically generated data from a prior data distribution. In essence, FoMo-0D is a pretrained Foundation Model for zero/0-shot OD on tabular data, which can directly predict the (outlier/inlier) label of any test data at inference time, by merely a single forward pass -- making obsolete the need for choosing an algorithm/architecture, tuning its associated hyperparameters, and even training any model parameters when given a new OD dataset. Extensive experiments on 57 public benchmark datasets against 26 baseline methods show that FoMo-0D performs statistically no different from the top 2nd baseline, while significantly outperforming the majority of the baselines, with an average inference time of 7.7 ms per test sample.
GraphBPE: Molecular Graphs Meet Byte-Pair Encoding
Jul 26, 2024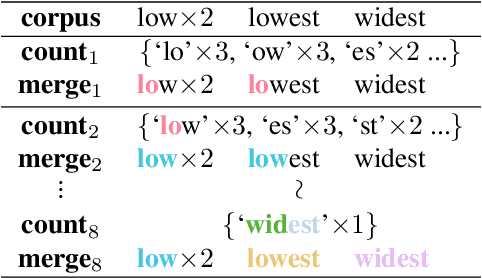
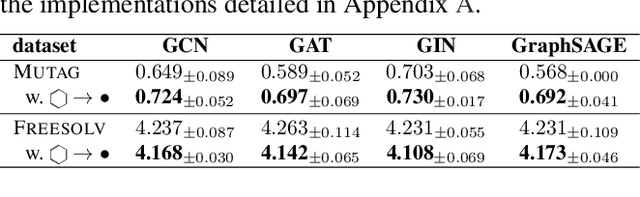
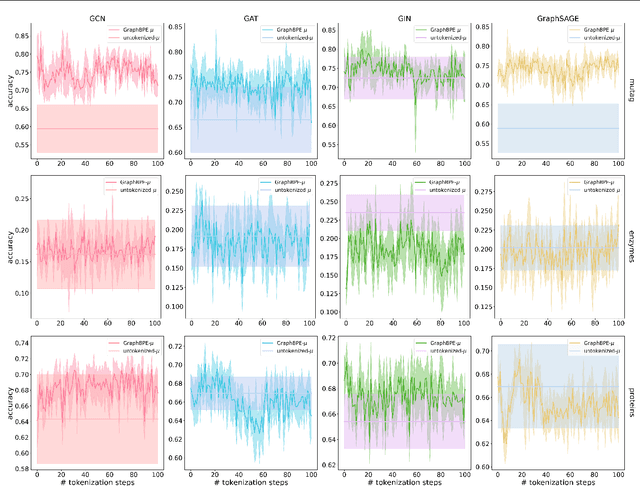
With the increasing attention to molecular machine learning, various innovations have been made in designing better models or proposing more comprehensive benchmarks. However, less is studied on the data preprocessing schedule for molecular graphs, where a different view of the molecular graph could potentially boost the model's performance. Inspired by the Byte-Pair Encoding (BPE) algorithm, a subword tokenization method popularly adopted in Natural Language Processing, we propose GraphBPE, which tokenizes a molecular graph into different substructures and acts as a preprocessing schedule independent of the model architectures. Our experiments on 3 graph-level classification and 3 graph-level regression datasets show that data preprocessing could boost the performance of models for molecular graphs, and GraphBPE is effective for small classification datasets and it performs on par with other tokenization methods across different model architectures.
OpinSummEval: Revisiting Automated Evaluation for Opinion Summarization
Oct 27, 2023



Opinion summarization sets itself apart from other types of summarization tasks due to its distinctive focus on aspects and sentiments. Although certain automated evaluation methods like ROUGE have gained popularity, we have found them to be unreliable measures for assessing the quality of opinion summaries. In this paper, we present OpinSummEval, a dataset comprising human judgments and outputs from 14 opinion summarization models. We further explore the correlation between 24 automatic metrics and human ratings across four dimensions. Our findings indicate that metrics based on neural networks generally outperform non-neural ones. However, even metrics built on powerful backbones, such as BART and GPT-3/3.5, do not consistently correlate well across all dimensions, highlighting the need for advancements in automated evaluation methods for opinion summarization. The code and data are publicly available at https://github.com/A-Chicharito-S/OpinSummEval/tree/main.
Training-Free Instance Segmentation from Semantic Image Segmentation Masks
Aug 02, 2023



In recent years, the development of instance segmentation has garnered significant attention in a wide range of applications. However, the training of a fully-supervised instance segmentation model requires costly both instance-level and pixel-level annotations. In contrast, weakly-supervised instance segmentation methods (i.e., with image-level class labels or point labels) struggle to satisfy the accuracy and recall requirements of practical scenarios. In this paper, we propose a novel paradigm for instance segmentation called training-free instance segmentation (TFISeg), which achieves instance segmentation results from image masks predicted using off-the-shelf semantic segmentation models. TFISeg does not require training a semantic or/and instance segmentation model and avoids the need for instance-level image annotations. Therefore, it is highly efficient. Specifically, we first obtain a semantic segmentation mask of the input image via a trained semantic segmentation model. Then, we calculate a displacement field vector for each pixel based on the segmentation mask, which can indicate representations belonging to the same class but different instances, i.e., obtaining the instance-level object information. Finally, instance segmentation results are obtained after being refined by a learnable category-agnostic object boundary branch. Extensive experimental results on two challenging datasets and representative semantic segmentation baselines (including CNNs and Transformers) demonstrate that TFISeg can achieve competitive results compared to the state-of-the-art fully-supervised instance segmentation methods without the need for additional human resources or increased computational costs. The code is available at: TFISeg
Label-Driven Denoising Framework for Multi-Label Few-Shot Aspect Category Detection
Oct 09, 2022Multi-Label Few-Shot Aspect Category Detection (FS-ACD) is a new sub-task of aspect-based sentiment analysis, which aims to detect aspect categories accurately with limited training instances. Recently, dominant works use the prototypical network to accomplish this task, and employ the attention mechanism to extract keywords of aspect category from the sentences to produce the prototype for each aspect. However, they still suffer from serious noise problems: (1) due to lack of sufficient supervised data, the previous methods easily catch noisy words irrelevant to the current aspect category, which largely affects the quality of the generated prototype; (2) the semantically-close aspect categories usually generate similar prototypes, which are mutually noisy and confuse the classifier seriously. In this paper, we resort to the label information of each aspect to tackle the above problems, along with proposing a novel Label-Driven Denoising Framework (LDF). Extensive experimental results show that our framework achieves better performance than other state-of-the-art methods.