 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphBPE: Molecular Graphs Meet Byte-Pair Encoding
Paper and Code
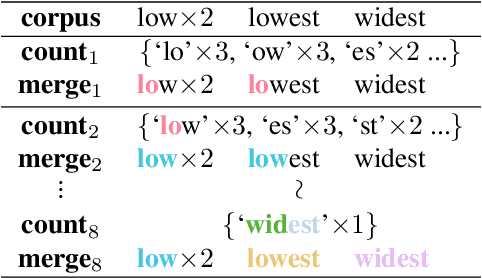
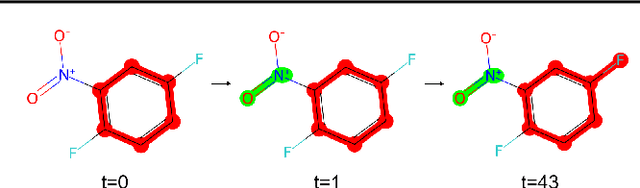
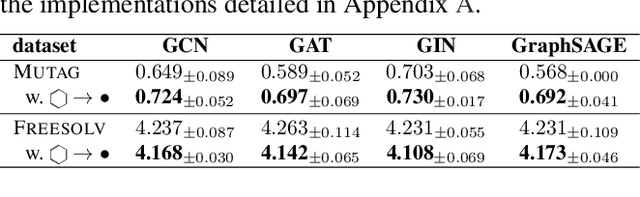
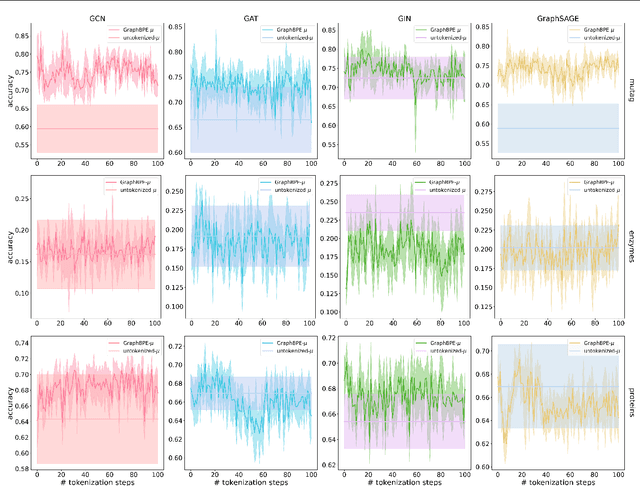
With the increasing attention to molecular machine learning, various innovations have been made in designing better models or proposing more comprehensive benchmarks. However, less is studied on the data preprocessing schedule for molecular graphs, where a different view of the molecular graph could potentially boost the model's performance. Inspired by the Byte-Pair Encoding (BPE) algorithm, a subword tokenization method popularly adopted in Natural Language Processing, we propose GraphBPE, which tokenizes a molecular graph into different substructures and acts as a preprocessing schedule independent of the model architectures. Our experiments on 3 graph-level classification and 3 graph-level regression datasets show that data preprocessing could boost the performance of models for molecular graphs, and GraphBPE is effective for small classification datasets and it performs on par with other tokenization methods across different model architectures.