 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunities and challenges in the application of large artificial intelligence models in radiology
Mar 24, 2024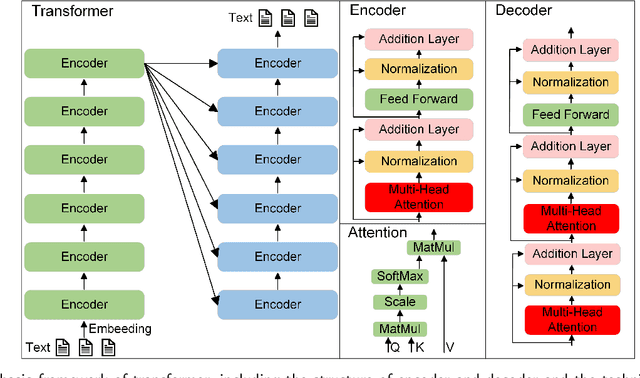

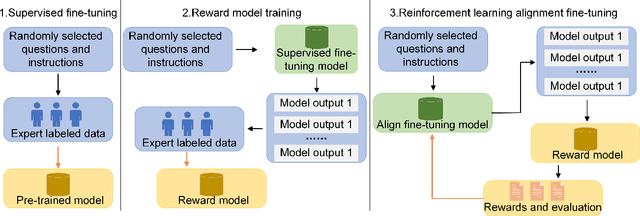
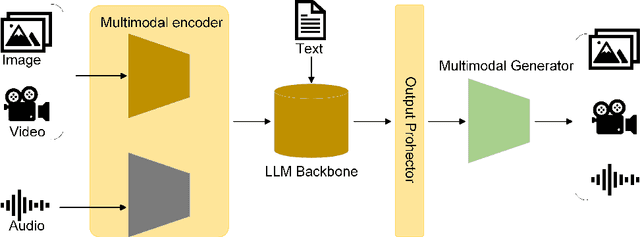
Influenced by ChatGPT, artificial intelligence (AI) large models have witnessed a global upsurge in large model research and development. As people enjoy the convenience by this AI large model, more and more large models in subdivided fields are gradually being proposed, especially large models in radiology imaging field. This article first introduces the development history of large models, technical details, workflow, working principles of multimodal large models and working principles of video generation large models. Secondly, we summarize the latest research progress of AI large models in radiology education, radiology report generation, applications of unimodal and multimodal radiology. Finally, this paper also summarizes some of the challenges of large AI models in radiology, with the aim of better promoting the rapid revolution in the field of radiography.
Training-Free Instance Segmentation from Semantic Image Segmentation Masks
Aug 02, 2023



In recent years, the development of instance segmentation has garnered significant attention in a wide range of applications. However, the training of a fully-supervised instance segmentation model requires costly both instance-level and pixel-level annotations. In contrast, weakly-supervised instance segmentation methods (i.e., with image-level class labels or point labels) struggle to satisfy the accuracy and recall requirements of practical scenarios. In this paper, we propose a novel paradigm for instance segmentation called training-free instance segmentation (TFISeg), which achieves instance segmentation results from image masks predicted using off-the-shelf semantic segmentation models. TFISeg does not require training a semantic or/and instance segmentation model and avoids the need for instance-level image annotations. Therefore, it is highly efficient. Specifically, we first obtain a semantic segmentation mask of the input image via a trained semantic segmentation model. Then, we calculate a displacement field vector for each pixel based on the segmentation mask, which can indicate representations belonging to the same class but different instances, i.e., obtaining the instance-level object information. Finally, instance segmentation results are obtained after being refined by a learnable category-agnostic object boundary branch. Extensive experimental results on two challenging datasets and representative semantic segmentation baselines (including CNNs and Transformers) demonstrate that TFISeg can achieve competitive results compared to the state-of-the-art fully-supervised instance segmentation methods without the need for additional human resources or increased computational costs. The code is available at: TFISeg
Learning to Reduce Information Bottleneck for Object Detection in Aerial Images
Apr 05, 2022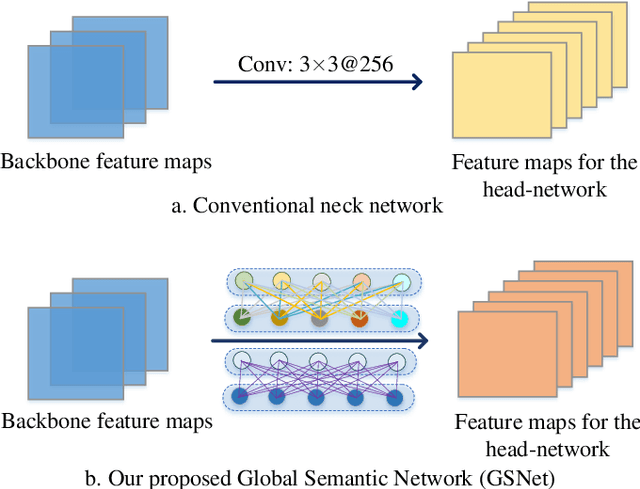
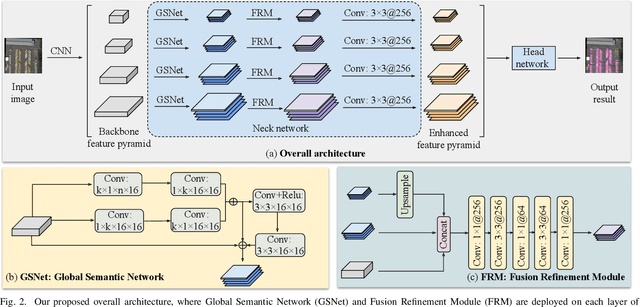
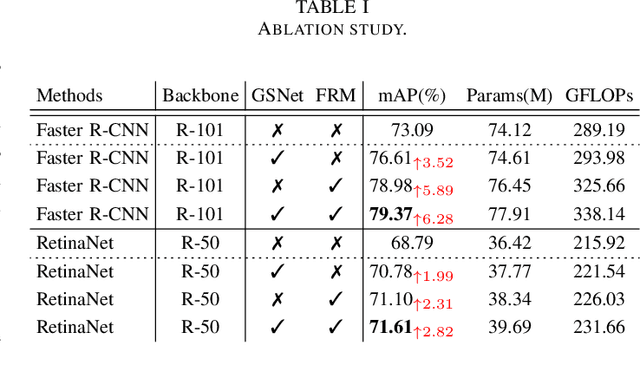
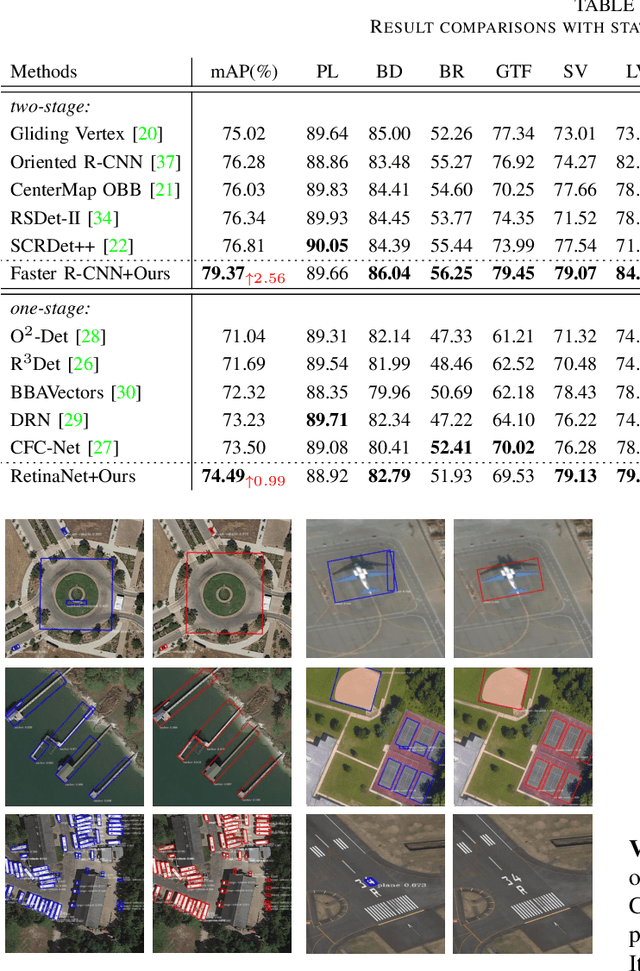
Object detection in aerial images is a fundamental research topic in the domain of geoscience and remote sensing. However, advanced progresses on this topic are mainly focused on the designment of backbone networks or header networks, but surprisingly ignored the neck ones. In this letter, we first analyse the importance of the neck network in object detection frameworks from the theory of information bottleneck. Then, to alleviate the information loss problem in the current neck network, we propose a global semantic network, which acts as a bridge from the backbone to the head network in a bidirectional global convolution manner. Compared to the existing neck networks, our method has advantages of capturing rich detailed information and less computational costs. Moreover, we further propose a fusion refinement module, which is used for feature fusion with rich details from different scales. To demonstrate the effectiveness and efficiency of our method, experiments are carried out on two challenging datasets (i.e., DOTA and HRSC2016). Results in terms of accuracy and computational complexity both can verify the superiority of our method.