 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Prior Thompson Sampling for Cold-Start Exploration in Recommender Systems
Feb 01, 2026Cold-start exploration is a core challenge in large-scale recommender systems: new or data-sparse items must receive traffic to estimate value, but over-exploration harms users and wastes impressions. In practice, Thompson Sampling (TS) is often initialized with a uniform Beta(1,1) prior, implicitly assuming a 50% success rate for unseen items. When true base rates are far lower, this optimistic prior systematically over-allocates to weak items. The impact is amplified by batched policy updates and pipeline latency: for hours, newly launched items can remain effectively "no data," so the prior dominates allocation before feedback is incorporated. We propose Dynamic Prior Thompson Sampling, a prior design that directly controls the probability that a new arm outcompetes the incumbent winner. Our key contribution is a closed-form quadratic solution for the prior mean that enforces P(X_j > Y_k) = epsilon at introduction time, making exploration intensity predictable and tunable while preserving TS Bayesian updates. Across Monte Carlo validation, offline batched simulations, and a large-scale online experiment on a thumbnail personalization system serving millions of users, dynamic priors deliver precise exploration control and improved efficiency versus a uniform-prior baseline.
CoPHo: Classifier-guided Conditional Topology Generation with Persistent Homology
Dec 17, 2025The structure of topology underpins much of the research on performance and robustness, yet available topology data are typically scarce, necessitating the generation of synthetic graphs with desired properties for testing or release. Prior diffusion-based approaches either embed conditions into the diffusion model, requiring retraining for each attribute and hindering real-time applicability, or use classifier-based guidance post-training, which does not account for topology scale and practical constraints. In this paper, we show from a discrete perspective that gradients from a pre-trained graph-level classifier can be incorporated into the discrete reverse diffusion posterior to steer generation toward specified structural properties. Based on this insight, we propose Classifier-guided Conditional Topology Generation with Persistent Homology (CoPHo), which builds a persistent homology filtration over intermediate graphs and interprets features as guidance signals that steer generation toward the desired properties at each denoising step. Experiments on four generic/network datasets demonstrate that CoPHo outperforms existing methods at matching target metrics, and we further validate its transferability on the QM9 molecular dataset.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Can LLMs Grasp Implicit Cultural Values? Benchmarking LLMs' Metacognitive Cultural Intelligence with CQ-Bench
Apr 01, 2025Cultural Intelligence (CQ) refers to the ability to understand unfamiliar cultural contexts-a crucial skill for large language models (LLMs) to effectively engage with globally diverse users. While existing research often focuses on explicitly stated cultural norms, such approaches fail to capture the subtle, implicit values that underlie real-world conversations. To address this gap, we introduce CQ-Bench, a benchmark specifically designed to assess LLMs' capability to infer implicit cultural values from natural conversational contexts. We generate a multi-character conversation-based stories dataset using values from the World Value Survey and GlobalOpinions datasets, with topics including ethical, religious, social, and political. Our dataset construction pipeline includes rigorous validation procedures-incorporation, consistency, and implicitness checks-using GPT-4o, with 98.2% human-model agreement in the final validation. Our benchmark consists of three tasks of increasing complexity: attitude detection, value selection, and value extraction. We find that while o1 and Deepseek-R1 models reach human-level performance in value selection (0.809 and 0.814), they still fall short in nuanced attitude detection, with F1 scores of 0.622 and 0.635, respectively. In the value extraction task, GPT-4o-mini and o3-mini score 0.602 and 0.598, highlighting the difficulty of open-ended cultural reasoning. Notably, fine-tuning smaller models (e.g., LLaMA-3.2-3B) on only 500 culturally rich examples improves performance by over 10%, even outperforming stronger baselines (o3-mini) in some cases. Using CQ-Bench, we provide insights into the current challenges in LLMs' CQ research and suggest practical pathways for enhancing LLMs' cross-cultural reasoning abilities.
LEDiT: Your Length-Extrapolatable Diffusion Transformer without Positional Encoding
Mar 07, 2025

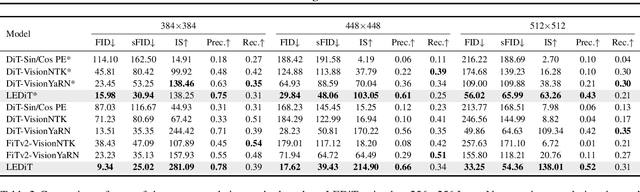
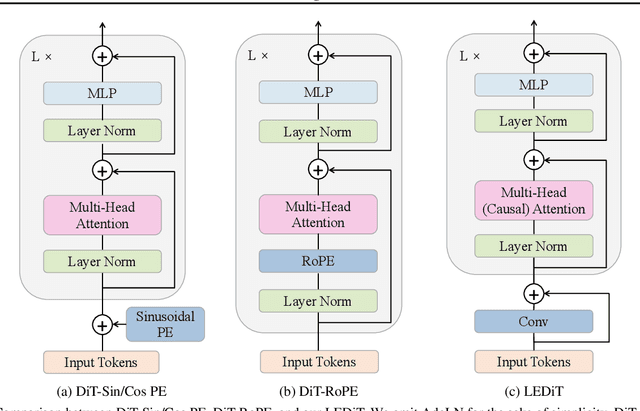
Diffusion transformers(DiTs) struggle to generate images at resolutions higher than their training resolutions. The primary obstacle is that the explicit positional encodings(PE), such as RoPE, need extrapolation which degrades performance when the inference resolution differs from training. In this paper, we propose a Length-Extrapolatable Diffusion Transformer(LEDiT), a simple yet powerful architecture to overcome this limitation. LEDiT needs no explicit PEs, thereby avoiding extrapolation. The key innovations of LEDiT are introducing causal attention to implicitly impart global positional information to tokens, while enhancing locality to precisely distinguish adjacent tokens. Experiments on 256x256 and 512x512 ImageNet show that LEDiT can scale the inference resolution to 512x512 and 1024x1024, respectively, while achieving better image quality compared to current state-of-the-art length extrapolation methods(NTK-aware, YaRN). Moreover, LEDiT achieves strong extrapolation performance with just 100K steps of fine-tuning on a pretrained DiT, demonstrating its potential for integration into existing text-to-image DiTs. Project page: https://shenzhang2145.github.io/ledit/
Feature-interactive Siamese graph encoder-based image analysis to predict STAS from histopathology images in lung cancer
Nov 22, 2024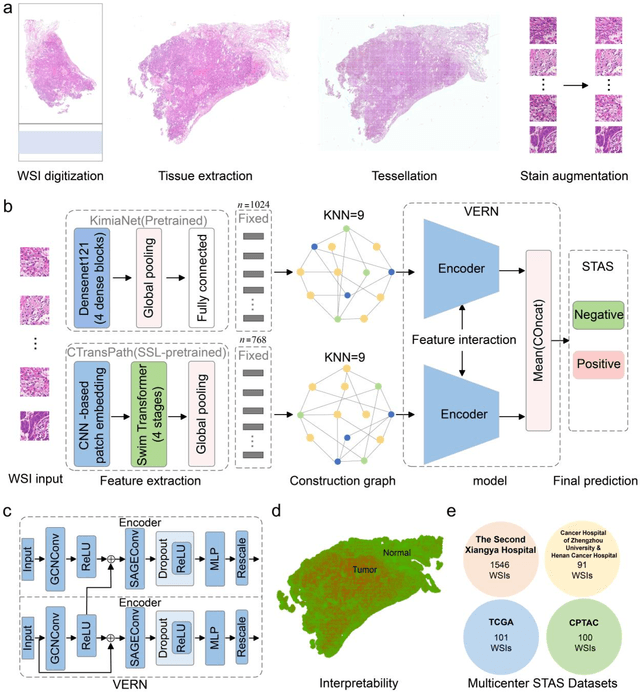
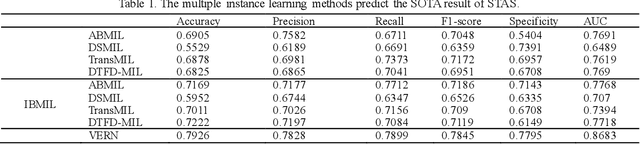
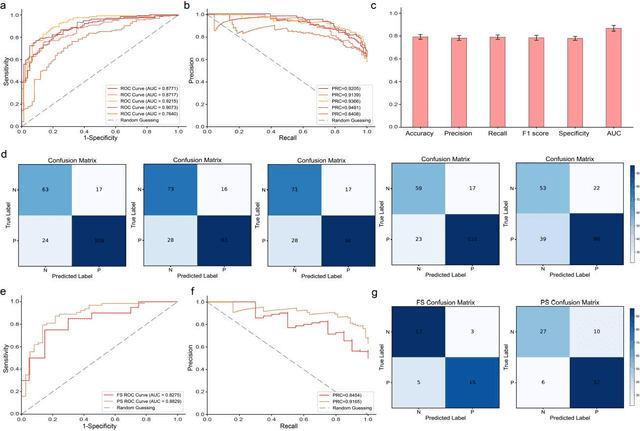
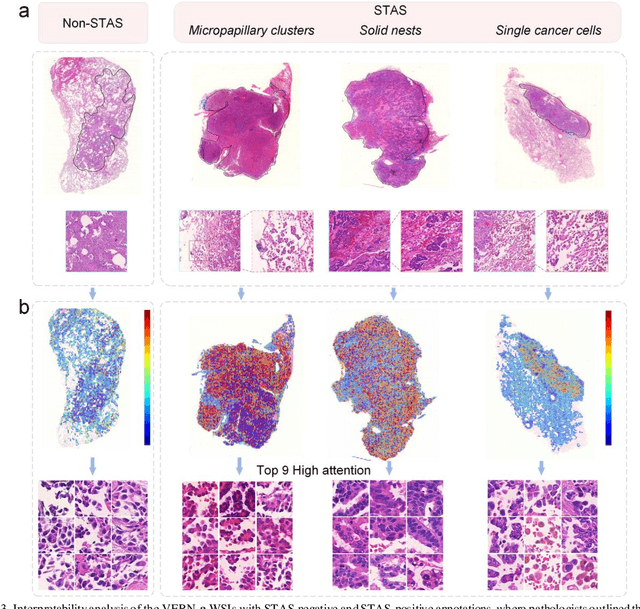
Spread through air spaces (STAS) is a distinct invasion pattern in lung cancer, crucial for prognosis assessment and guiding surgical decisions. Histopathology is the gold standard for STAS detection, yet traditional methods are subjective, time-consuming, and prone to misdiagnosis, limiting large-scale applications. We present VERN, an image analysis model utilizing a feature-interactive Siamese graph encoder to predict STAS from lung cancer histopathological images. VERN captures spatial topological features with feature sharing and skip connections to enhance model training. Using 1,546 histopathology slides, we built a large single-cohort STAS lung cancer dataset. VERN achieved an AUC of 0.9215 in internal validation and AUCs of 0.8275 and 0.8829 in frozen and paraffin-embedded test sections, respectively, demonstrating clinical-grade performance. Validated on a single-cohort and three external datasets, VERN showed robust predictive performance and generalizability, providing an open platform (http://plr.20210706.xyz:5000/) to enhance STAS diagnosis efficiency and accuracy.
Causal Feature Selection Method for Contextual Multi-Armed Bandits in Recommender System
Sep 20, 2024


Features (a.k.a. context) are critical for contextual multi-armed bandits (MAB) performance. In practice of large scale online system, it is important to select and implement important features for the model: missing important features can led to sub-optimal reward outcome, and including irrelevant features can cause overfitting, poor model interpretability, and implementation cost. However, feature selection methods for conventional machine learning models fail short for contextual MAB use cases, as conventional methods select features correlated with the outcome variable, but not necessarily causing heterogeneuous treatment effect among arms which are truely important for contextual MAB. In this paper, we introduce model-free feature selection methods designed for contexutal MAB problem, based on heterogeneous causal effect contributed by the feature to the reward distribution. Empirical evaluation is conducted based on synthetic data as well as real data from an online experiment for optimizing content cover image in a recommender system. The results show this feature selection method effectively selects the important features that lead to higher contextual MAB reward than unimportant features. Compared with model embedded method, this model-free method has advantage of fast computation speed, ease of implementation, and prune of model mis-specification issues.
Opportunities and challenges in the application of large artificial intelligence models in radiology
Mar 24, 2024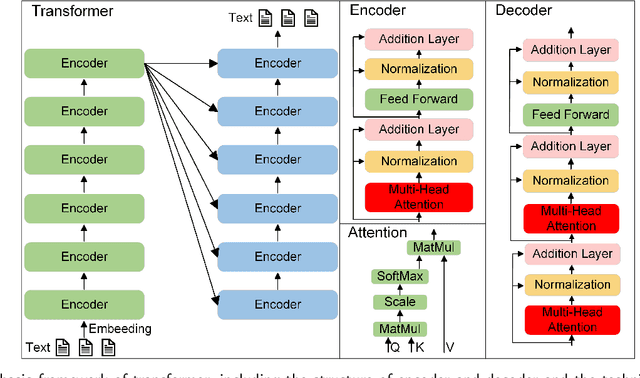

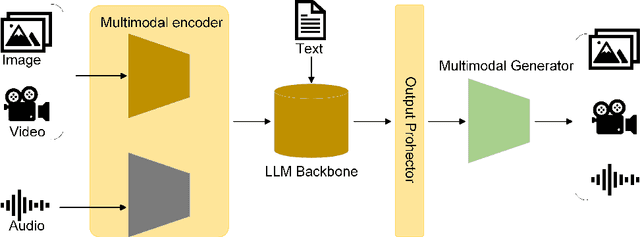
Influenced by ChatGPT, artificial intelligence (AI) large models have witnessed a global upsurge in large model research and development. As people enjoy the convenience by this AI large model, more and more large models in subdivided fields are gradually being proposed, especially large models in radiology imaging field. This article first introduces the development history of large models, technical details, workflow, working principles of multimodal large models and working principles of video generation large models. Secondly, we summarize the latest research progress of AI large models in radiology education, radiology report generation, applications of unimodal and multimodal radiology. Finally, this paper also summarizes some of the challenges of large AI models in radiology, with the aim of better promoting the rapid revolution in the field of radiography.
Integrating Active Learning in Causal Inference with Interference: A Novel Approach in Online Experiments
Feb 20, 2024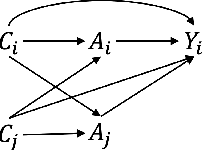
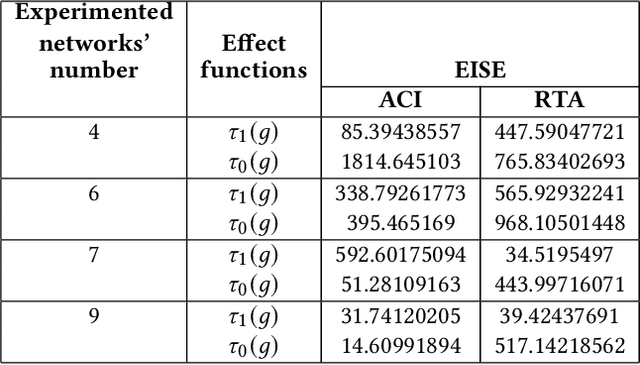
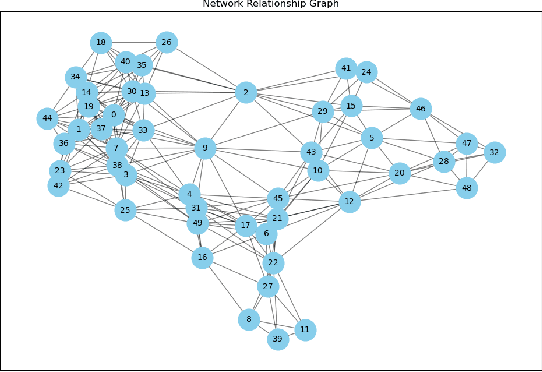
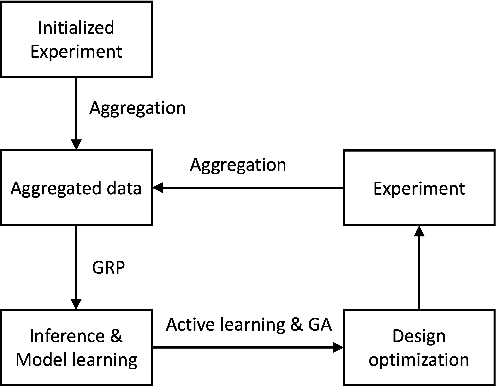
In the domain of causal inference research, the prevalent potential outcomes framework, notably the Rubin Causal Model (RCM), often overlooks individual interference and assumes independent treatment effects. This assumption, however, is frequently misaligned with the intricate realities of real-world scenarios, where interference is not merely a possibility but a common occurrence. Our research endeavors to address this discrepancy by focusing on the estimation of direct and spillover treatment effects under two assumptions: (1) network-based interference, where treatments on neighbors within connected networks affect one's outcomes, and (2) non-random treatment assignments influenced by confounders. To improve the efficiency of estimating potentially complex effects functions, we introduce an novel active learning approach: Active Learning in Causal Inference with Interference (ACI). This approach uses Gaussian process to flexibly model the direct and spillover treatment effects as a function of a continuous measure of neighbors' treatment assignment. The ACI framework sequentially identifies the experimental settings that demand further data. It further optimizes the treatment assignments under the network interference structure using genetic algorithms to achieve efficient learning outcome. By applying our method to simulation data and a Tencent game dataset, we demonstrate its feasibility in achieving accurate effects estimations with reduced data requirements. This ACI approach marks a significant advancement in the realm of data efficiency for causal inference, offering a robust and efficient alternative to traditional methodologies, particularly in scenarios characterized by complex interference patterns.
HiDiffusion: Unlocking High-Resolution Creativity and Efficiency in Low-Resolution Trained Diffusion Models
Nov 29, 2023We introduce HiDiffusion, a tuning-free framework comprised of Resolution-Aware U-Net (RAU-Net) and Modified Shifted Window Multi-head Self-Attention (MSW-MSA) to enable pretrained large text-to-image diffusion models to efficiently generate high-resolution images (e.g. 1024$\times$1024) that surpass the training image resolution. Pretrained diffusion models encounter unreasonable object duplication in generating images beyond the training image resolution. We attribute it to the mismatch between the feature map size of high-resolution images and the receptive field of U-Net's convolution. To address this issue, we propose a simple yet scalable method named RAU-Net. RAU-Net dynamically adjusts the feature map size to match the convolution's receptive field in the deep block of U-Net. Another obstacle in high-resolution synthesis is the slow inference speed of U-Net. Our observations reveal that the global self-attention in the top block, which exhibits locality, however, consumes the majority of computational resources. To tackle this issue, we propose MSW-MSA. Unlike previous window attention mechanisms, our method uses a much larger window size and dynamically shifts windows to better accommodate diffusion models. Extensive experiments demonstrate that our HiDiffusion can scale diffusion models to generate 1024$\times$1024, 2048$\times$2048, or even 4096$\times$4096 resolution images, while simultaneously reducing inference time by 40\%-60\%, achieving state-of-the-art performance on high-resolution image synthesis. The most significant revelation of our work is that a pretrained diffusion model on low-resolution images is scalable for high-resolution generation without further tuning. We hope this revelation can provide insights for future research on the scalability of diffusion models.