 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceMind++: Toward Allocentric Cognitive Maps for Spatially Grounded Video MLLMs
May 10, 2026Recent multimodal large language models (MLLMs) have made remarkable progress in visual understanding and language-based reasoning, yet they lack a persistent world-centered representation for spatially consistent reasoning in 3D environments. Inspired by the mammalian dual-stream system, where semantic and spatial cues are processed separately and integrated into an allocentric cognitive map, we propose SpaceMind++, a video MLLM architecture that explicitly builds a voxelized cognitive map from RGB videos. This map reorganizes fragmented egocentric observations into a shared 3D metric representation, enabling the model to preserve object permanence and spatial topology across changing viewpoints. To make this allocentric representation usable by a pretrained video MLLM without disrupting its native visual-token interface, we introduce Coordinate-Guided Deep Iterative Fusion, a new mechanism that relays map-level spatial knowledge back into the original 2D visual features. This fusion is explicitly guided by coordinate embeddings and 3D Rotary Positional Encoding, which ground semantic interactions in metric 3D space, resembling the entorhinal binding of sensory features to metric space. Extensive experiments show that SpaceMind++ achieves new state-of-the-art performance on VSI-Bench. Furthermore, it demonstrates superior out-of-distribution generalization on SPBench, SITE-Bench, and SPAR-Bench, underscoring its robustness in unseen 3D environments.
Task-Specific Sparse Feature Masks for Molecular Toxicity Prediction with Chemical Language Models
Dec 12, 2025Reliable in silico molecular toxicity prediction is a cornerstone of modern drug discovery, offering a scalable alternative to experimental screening. However, the black-box nature of state-of-the-art models remains a significant barrier to adoption, as high-stakes safety decisions demand verifiable structural insights alongside predictive performance. To address this, we propose a novel multi-task learning (MTL) framework designed to jointly enhance accuracy and interpretability. Our architecture integrates a shared chemical language model with task-specific attention modules. By imposing an L1 sparsity penalty on these modules, the framework is constrained to focus on a minimal set of salient molecular fragments for each distinct toxicity endpoint. The resulting framework is trained end-to-end and is readily adaptable to various transformer-based backbones. Evaluated on the ClinTox, SIDER, and Tox21 benchmark datasets, our approach consistently outperforms both single-task and standard MTL baselines. Crucially, the sparse attention weights provide chemically intuitive visualizations that reveal the specific fragments influencing predictions, thereby enhancing insight into the model's decision-making process.
NeuralDB: Scaling Knowledge Editing in LLMs to 100,000 Facts with Neural KV Database
Jul 24, 2025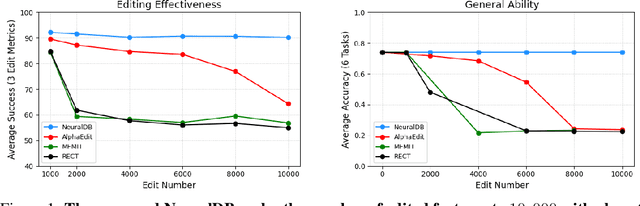
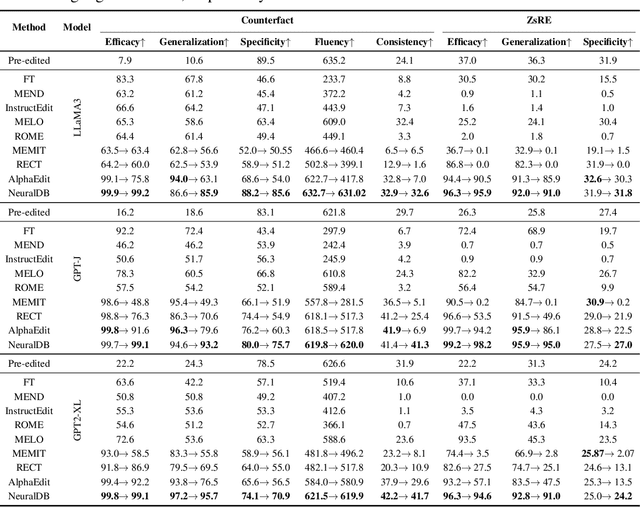
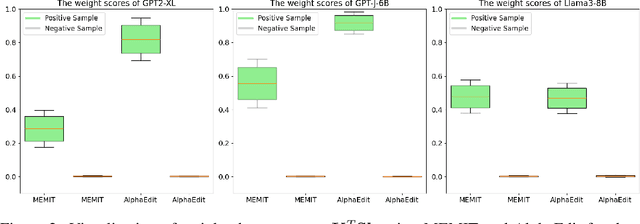

Efficiently editing knowledge stored in large language models (LLMs) enables model updates without large-scale training. One possible solution is Locate-and-Edit (L\&E), allowing simultaneous modifications of a massive number of facts. However, such editing may compromise the general abilities of LLMs and even result in forgetting edited facts when scaling up to thousands of edits. In this paper, we model existing linear L\&E methods as querying a Key-Value (KV) database. From this perspective, we then propose NeuralDB, an editing framework that explicitly represents the edited facts as a neural KV database equipped with a non-linear gated retrieval module, % In particular, our gated module only operates when inference involves the edited facts, effectively preserving the general abilities of LLMs. Comprehensive experiments involving the editing of 10,000 facts were conducted on the ZsRE and CounterFacts datasets, using GPT2-XL, GPT-J (6B) and Llama-3 (8B). The results demonstrate that NeuralDB not only excels in editing efficacy, generalization, specificity, fluency, and consistency, but also preserves overall performance across six representative text understanding and generation tasks. Further experiments indicate that NeuralDB maintains its effectiveness even when scaled to 100,000 facts (\textbf{50x} more than in prior work).
Representation Entanglement for Generation:Training Diffusion Transformers Is Much Easier Than You Think
Jul 02, 2025
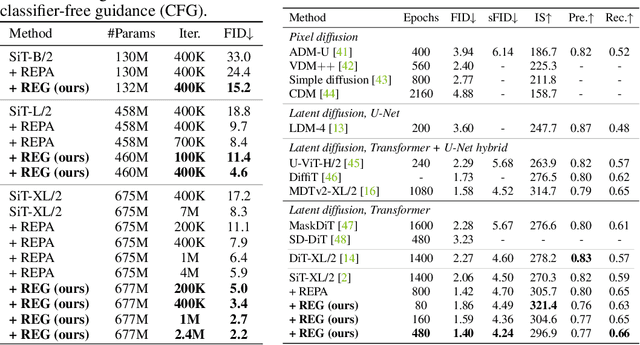
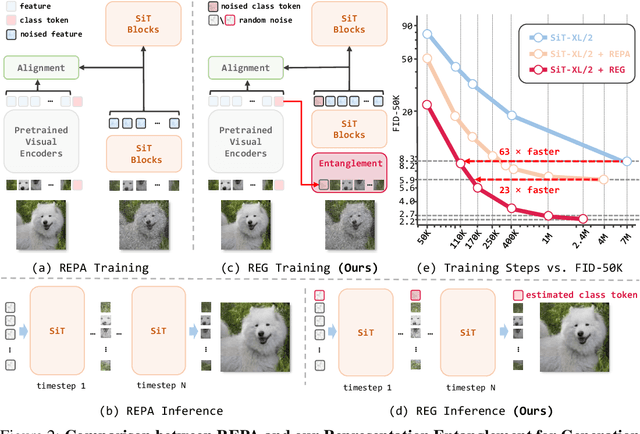
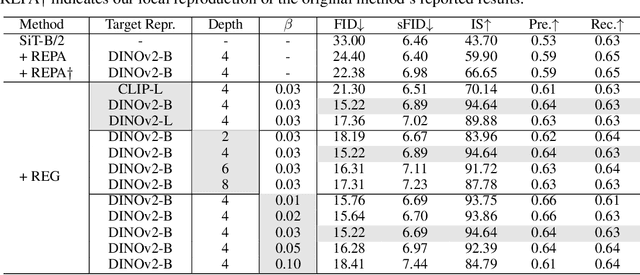
REPA and its variants effectively mitigate training challenges in diffusion models by incorporating external visual representations from pretrained models, through alignment between the noisy hidden projections of denoising networks and foundational clean image representations. We argue that the external alignment, which is absent during the entire denoising inference process, falls short of fully harnessing the potential of discriminative representations. In this work, we propose a straightforward method called Representation Entanglement for Generation (REG), which entangles low-level image latents with a single high-level class token from pretrained foundation models for denoising. REG acquires the capability to produce coherent image-class pairs directly from pure noise, substantially improving both generation quality and training efficiency. This is accomplished with negligible additional inference overhead, requiring only one single additional token for denoising (<0.5\% increase in FLOPs and latency). The inference process concurrently reconstructs both image latents and their corresponding global semantics, where the acquired semantic knowledge actively guides and enhances the image generation process. On ImageNet 256$\times$256, SiT-XL/2 + REG demonstrates remarkable convergence acceleration, achieving $\textbf{63}\times$ and $\textbf{23}\times$ faster training than SiT-XL/2 and SiT-XL/2 + REPA, respectively. More impressively, SiT-L/2 + REG trained for merely 400K iterations outperforms SiT-XL/2 + REPA trained for 4M iterations ($\textbf{10}\times$ longer). Code is available at: https://github.com/Martinser/REG.
Agent-based Video Trimming
Dec 12, 2024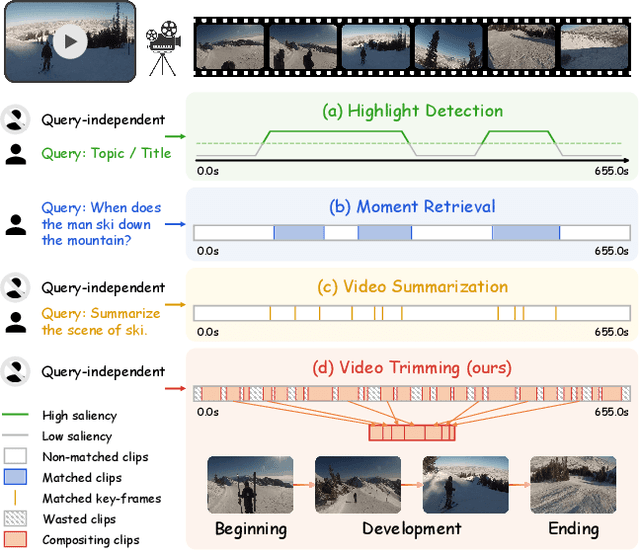
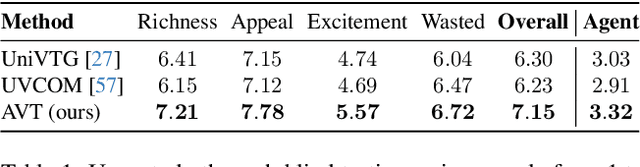
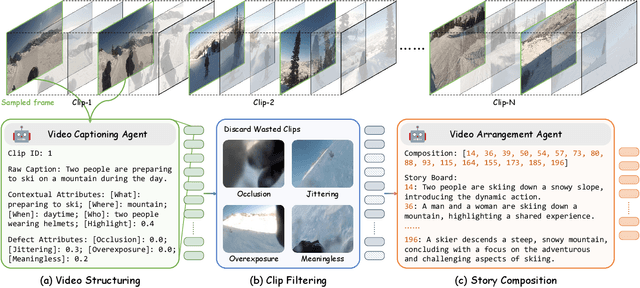
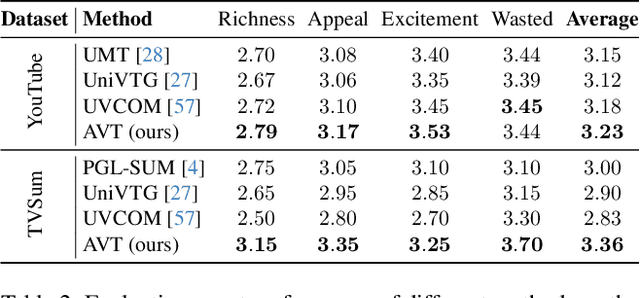
As information becomes more accessible, user-generated videos are increasing in length, placing a burden on viewers to sift through vast content for valuable insights. This trend underscores the need for an algorithm to extract key video information efficiently. Despite significant advancements in highlight detection, moment retrieval, and video summarization, current approaches primarily focus on selecting specific time intervals, often overlooking the relevance between segments and the potential for segment arranging. In this paper, we introduce a novel task called Video Trimming (VT), which focuses on detecting wasted footage, selecting valuable segments, and composing them into a final video with a coherent story. To address this task, we propose Agent-based Video Trimming (AVT), structured into three phases: Video Structuring, Clip Filtering, and Story Composition. Specifically, we employ a Video Captioning Agent to convert video slices into structured textual descriptions, a Filtering Module to dynamically discard low-quality footage based on the structured information of each clip, and a Video Arrangement Agent to select and compile valid clips into a coherent final narrative. For evaluation, we develop a Video Evaluation Agent to assess trimmed videos, conducting assessments in parallel with human evaluations. Additionally, we curate a new benchmark dataset for video trimming using raw user videos from the internet. As a result, AVT received more favorable evaluations in user studies and demonstrated superior mAP and precision on the YouTube Highlights, TVSum, and our own dataset for the highlight detection task. The code and models are available at https://ylingfeng.github.io/AVT.
HazyDet: Open-source Benchmark for Drone-view Object Detection with Depth-cues in Hazy Scenes
Sep 30, 2024



Drone-based object detection in adverse weather conditions is crucial for enhancing drones' environmental perception, yet it remains largely unexplored due to the lack of relevant benchmarks. To bridge this gap, we introduce HazyDet, a large-scale dataset tailored for drone-based object detection in hazy scenes. It encompasses 383,000 real-world instances, collected from both naturally hazy environments and normal scenes with synthetically imposed haze effects to simulate adverse weather conditions. By observing the significant variations in object scale and clarity under different depth and haze conditions, we designed a Depth Conditioned Detector (DeCoDet) to incorporate this prior knowledge. DeCoDet features a Multi-scale Depth-aware Detection Head that seamlessly integrates depth perception, with the resulting depth cues harnessed by a dynamic Depth Condition Kernel module. Furthermore, we propose a Scale Invariant Refurbishment Loss to facilitate the learning of robust depth cues from pseudo-labels. Extensive evaluations on the HazyDet dataset demonstrate the flexibility and effectiveness of our method, yielding significant performance improvements. Our dataset and toolkit are available at https://github.com/GrokCV/HazyDet.
Revisiting Prompt Pretraining of Vision-Language Models
Sep 10, 2024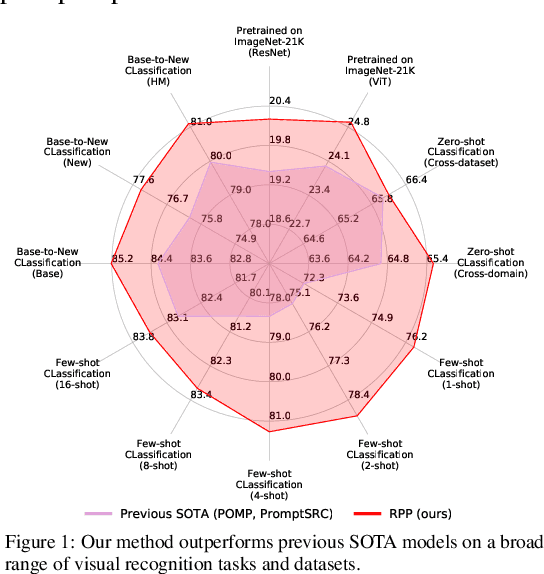

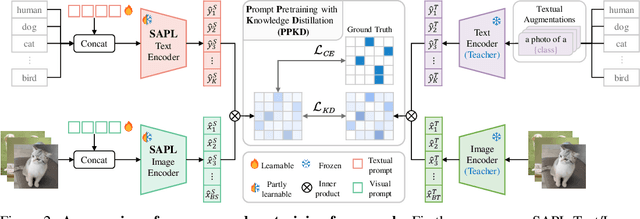
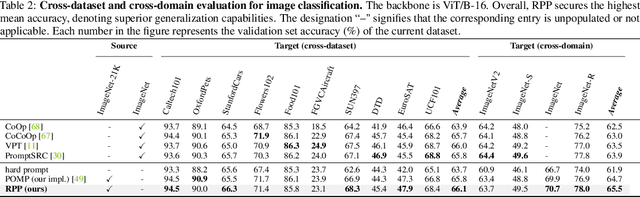
Prompt learning is an effective method to customize Vision-Language Models (VLMs) for various downstream tasks, involving tuning very few parameters of input prompt tokens. Recently, prompt pretraining in large-scale dataset (e.g., ImageNet-21K) has played a crucial role in prompt learning for universal visual discrimination. However, we revisit and observe that the limited learnable prompts could face underfitting risks given the extensive images during prompt pretraining, simultaneously leading to poor generalization. To address the above issues, in this paper, we propose a general framework termed Revisiting Prompt Pretraining (RPP), which targets at improving the fitting and generalization ability from two aspects: prompt structure and prompt supervision. For prompt structure, we break the restriction in common practice where query, key, and value vectors are derived from the shared learnable prompt token. Instead, we introduce unshared individual query, key, and value learnable prompts, thereby enhancing the model's fitting capacity through increased parameter diversity. For prompt supervision, we additionally utilize soft labels derived from zero-shot probability predictions provided by a pretrained Contrastive Language Image Pretraining (CLIP) teacher model. These soft labels yield more nuanced and general insights into the inter-class relationships, thereby endowing the pretraining process with better generalization ability. RPP produces a more resilient prompt initialization, enhancing its robust transferability across diverse visual recognition tasks. Experiments across various benchmarks consistently confirm the state-of-the-art (SOTA) performance of our pretrained prompts. Codes and models will be made available soon.
HiDiffusion: Unlocking High-Resolution Creativity and Efficiency in Low-Resolution Trained Diffusion Models
Nov 29, 2023We introduce HiDiffusion, a tuning-free framework comprised of Resolution-Aware U-Net (RAU-Net) and Modified Shifted Window Multi-head Self-Attention (MSW-MSA) to enable pretrained large text-to-image diffusion models to efficiently generate high-resolution images (e.g. 1024$\times$1024) that surpass the training image resolution. Pretrained diffusion models encounter unreasonable object duplication in generating images beyond the training image resolution. We attribute it to the mismatch between the feature map size of high-resolution images and the receptive field of U-Net's convolution. To address this issue, we propose a simple yet scalable method named RAU-Net. RAU-Net dynamically adjusts the feature map size to match the convolution's receptive field in the deep block of U-Net. Another obstacle in high-resolution synthesis is the slow inference speed of U-Net. Our observations reveal that the global self-attention in the top block, which exhibits locality, however, consumes the majority of computational resources. To tackle this issue, we propose MSW-MSA. Unlike previous window attention mechanisms, our method uses a much larger window size and dynamically shifts windows to better accommodate diffusion models. Extensive experiments demonstrate that our HiDiffusion can scale diffusion models to generate 1024$\times$1024, 2048$\times$2048, or even 4096$\times$4096 resolution images, while simultaneously reducing inference time by 40\%-60\%, achieving state-of-the-art performance on high-resolution image synthesis. The most significant revelation of our work is that a pretrained diffusion model on low-resolution images is scalable for high-resolution generation without further tuning. We hope this revelation can provide insights for future research on the scalability of diffusion models.
LID 2020: The Learning from Imperfect Data Challenge Results
Oct 17, 2020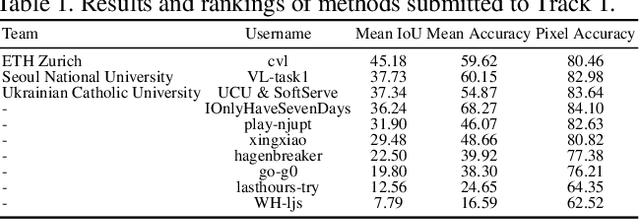
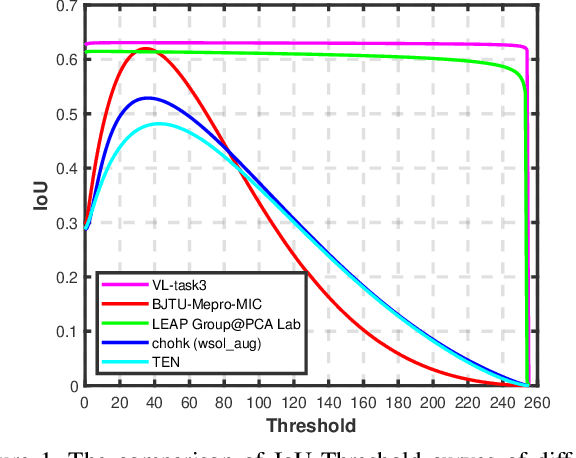

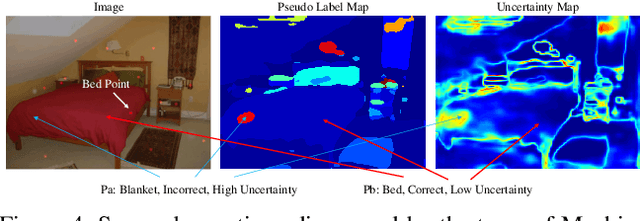
Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io