 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-based Video Trimming
Dec 12, 2024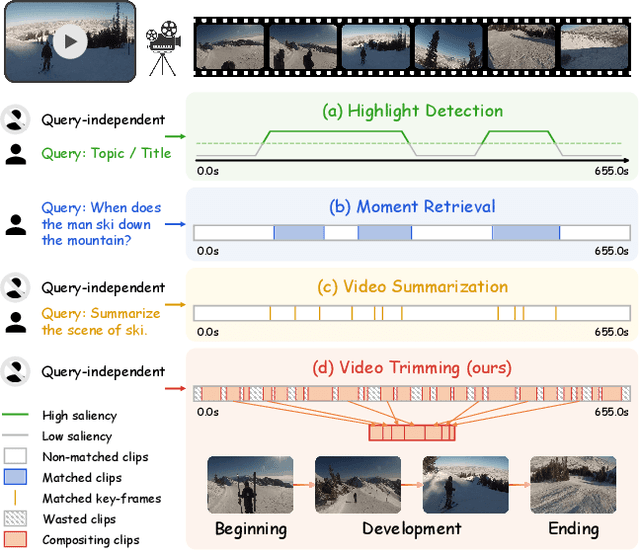
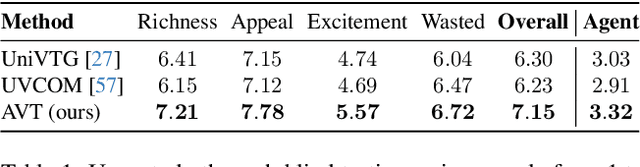
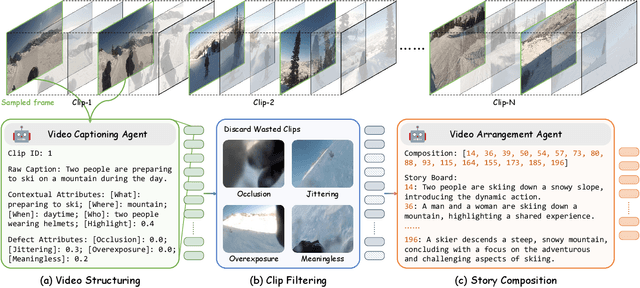
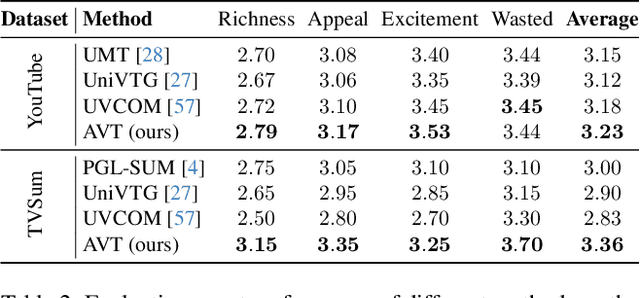
As information becomes more accessible, user-generated videos are increasing in length, placing a burden on viewers to sift through vast content for valuable insights. This trend underscores the need for an algorithm to extract key video information efficiently. Despite significant advancements in highlight detection, moment retrieval, and video summarization, current approaches primarily focus on selecting specific time intervals, often overlooking the relevance between segments and the potential for segment arranging. In this paper, we introduce a novel task called Video Trimming (VT), which focuses on detecting wasted footage, selecting valuable segments, and composing them into a final video with a coherent story. To address this task, we propose Agent-based Video Trimming (AVT), structured into three phases: Video Structuring, Clip Filtering, and Story Composition. Specifically, we employ a Video Captioning Agent to convert video slices into structured textual descriptions, a Filtering Module to dynamically discard low-quality footage based on the structured information of each clip, and a Video Arrangement Agent to select and compile valid clips into a coherent final narrative. For evaluation, we develop a Video Evaluation Agent to assess trimmed videos, conducting assessments in parallel with human evaluations. Additionally, we curate a new benchmark dataset for video trimming using raw user videos from the internet. As a result, AVT received more favorable evaluations in user studies and demonstrated superior mAP and precision on the YouTube Highlights, TVSum, and our own dataset for the highlight detection task. The code and models are available at https://ylingfeng.github.io/AVT.
Object-Level Representation Learning for Few-Shot Image Classification
May 28, 2018
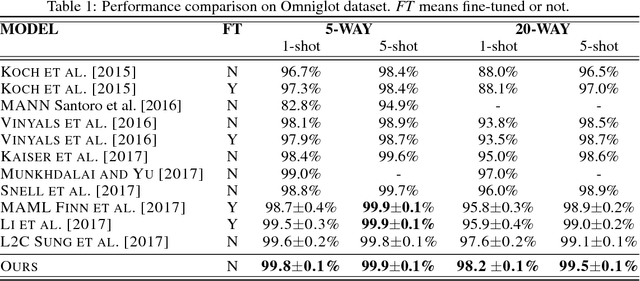
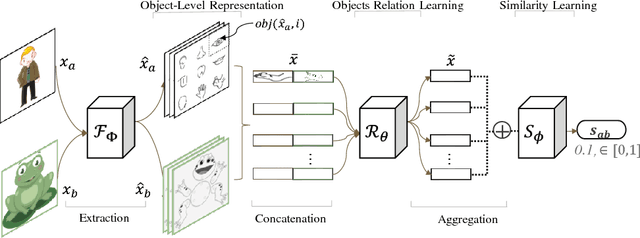

Few-shot learning that trains image classifiers over few labeled examples per category is a challenging task. In this paper, we propose to exploit an additional big dataset with different categories to improve the accuracy of few-shot learning over our target dataset. Our approach is based on the observation that images can be decomposed into objects, which may appear in images from both the additional dataset and our target dataset. We use the object-level relation learned from the additional dataset to infer the similarity of images in our target dataset with unseen categories. Nearest neighbor search is applied to do image classification, which is a non-parametric model and thus does not need fine-tuning. We evaluate our algorithm on two popular datasets, namely Omniglot and MiniImagenet. We obtain 8.5\% and 2.7\% absolute improvements for 5-way 1-shot and 5-way 5-shot experiments on MiniImagenet, respectively. Source code will be published upon acceptance.