 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAixel: A Unified, Adaptive and Extensible System for AI-powered Data Analysis
Oct 14, 2025A growing trend in modern data analysis is the integration of data management with learning, guided by accuracy, latency, and cost requirements. In practice, applications draw data of different formats from many sources. In the meanwhile, the objectives and budgets change over time. Existing systems handle these applications across databases, analysis libraries, and tuning services. Such fragmentation leads to complex user interaction, limited adaptability, suboptimal performance, and poor extensibility across components. To address these challenges, we present Aixel, a unified, adaptive, and extensible system for AI-powered data analysis. The system organizes work across four layers: application, task, model, and data. The task layer provides a declarative interface to capture user intent, which is parsed into an executable operator plan. An optimizer compiles and schedules this plan to meet specified goals in accuracy, latency, and cost. The task layer coordinates the execution of data and model operators, with built-in support for reuse and caching to improve efficiency. The model layer offers versioned storage for index, metadata, tensors, and model artifacts. It supports adaptive construction, task-aligned drift detection, and safe updates that reuse shared components. The data layer provides unified data management capabilities, including indexing, constraint-aware discovery, task-aligned selection, and comprehensive feature management. With the above designed layers, Aixel delivers a user friendly, adaptive, efficient, and extensible system.
A Comprehensive Study of Shapley Value in Data Analytics
Dec 03, 2024



Over the recent years, Shapley value (SV), a solution concept from cooperative game theory, has found numerous applications in data analytics (DA). This paper provides the first comprehensive study of SV used throughout the DA workflow, which involves three main steps: data fabric, data exploration, and result reporting. We summarize existing versatile forms of SV used in these steps by a unified definition and clarify the essential functionalities that SV can provide for data scientists. We categorize the arts in this field based on the technical challenges they tackled, which include computation efficiency, approximation error, privacy preservation, and appropriate interpretations. We discuss these challenges and analyze the corresponding solutions. We also implement SVBench, the first open-sourced benchmark for developing SV applications, and conduct experiments on six DA tasks to validate our analysis and discussions. Based on the qualitative and quantitative results, we identify the limitations of current efforts for applying SV to DA and highlight the directions of future research and engineering.
NeurDB: On the Design and Implementation of an AI-powered Autonomous Database
Aug 06, 2024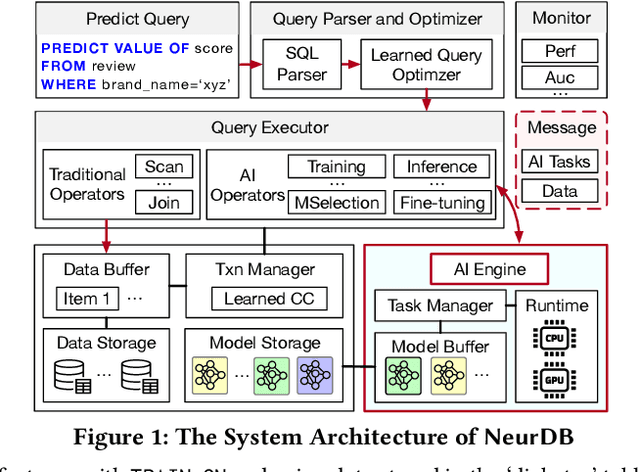
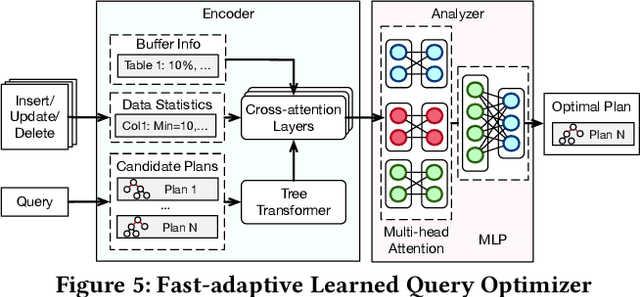
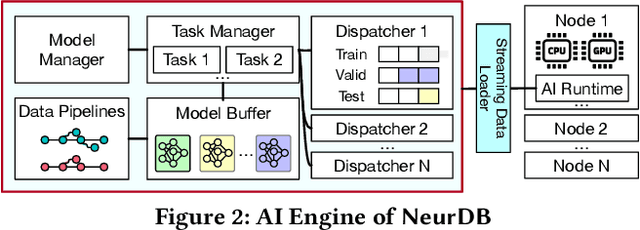
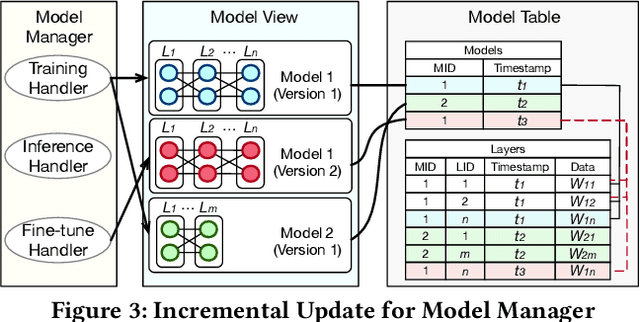
Databases are increasingly embracing AI to provide autonomous system optimization and intelligent in-database analytics, aiming to relieve end-user burdens across various industry sectors. Nonetheless, most existing approaches fail to account for the dynamic nature of databases, which renders them ineffective for real-world applications characterized by evolving data and workloads. This paper introduces NeurDB, an AI-powered autonomous database that deepens the fusion of AI and databases with adaptability to data and workload drift. NeurDB establishes a new in-database AI ecosystem that seamlessly integrates AI workflows within the database. This integration enables efficient and effective in-database AI analytics and fast-adaptive learned system components. Empirical evaluations demonstrate that NeurDB substantially outperforms existing solutions in managing AI analytics tasks, with the proposed learned components more effectively handling environmental dynamism than state-of-the-art approaches.
VecAug: Unveiling Camouflaged Frauds with Cohort Augmentation for Enhanced Detection
Aug 01, 2024



Fraud detection presents a challenging task characterized by ever-evolving fraud patterns and scarce labeled data. Existing methods predominantly rely on graph-based or sequence-based approaches. While graph-based approaches connect users through shared entities to capture structural information, they remain vulnerable to fraudsters who can disrupt or manipulate these connections. In contrast, sequence-based approaches analyze users' behavioral patterns, offering robustness against tampering but overlooking the interactions between similar users. Inspired by cohort analysis in retention and healthcare, this paper introduces VecAug, a novel cohort-augmented learning framework that addresses these challenges by enhancing the representation learning of target users with personalized cohort information. To this end, we first propose a vector burn-in technique for automatic cohort identification, which retrieves a task-specific cohort for each target user. Then, to fully exploit the cohort information, we introduce an attentive cohort aggregation technique for augmenting target user representations. To improve the robustness of such cohort augmentation, we also propose a novel label-aware cohort neighbor separation mechanism to distance negative cohort neighbors and calibrate the aggregated cohort information. By integrating this cohort information with target user representations, VecAug enhances the modeling capacity and generalization capabilities of the model to be augmented. Our framework is flexible and can be seamlessly integrated with existing fraud detection models. We deploy our framework on e-commerce platforms and evaluate it on three fraud detection datasets, and results show that VecAug improves the detection performance of base models by up to 2.48\% in AUC and 22.5\% in R@P$_{0.9}$, outperforming state-of-the-art methods significantly.
NeurDB: An AI-powered Autonomous Data System
May 07, 2024In the wake of rapid advancements in artificial intelligence (AI), we stand on the brink of a transformative leap in data systems. The imminent fusion of AI and DB (AIxDB) promises a new generation of data systems, which will relieve the burden on end-users across all industry sectors by featuring AI-enhanced functionalities, such as personalized and automated in-database AI-powered analytics, self-driving capabilities for improved system performance, etc. In this paper, we explore the evolution of data systems with a focus on deepening the fusion of AI and DB. We present NeurDB, our next-generation data system designed to fully embrace AI design in each major system component and provide in-database AI-powered analytics. We outline the conceptual and architectural overview of NeurDB, discuss its design choices and key components, and report its current development and future plan.
FLAC: A Robust Failure-Aware Atomic Commit Protocol for Distributed Transactions
Mar 02, 2023



In distributed transaction processing, atomic commit protocol (ACP) is used to ensure database consistency. With the use of commodity compute nodes and networks, failures such as system crashes and network partitioning are common. It is therefore important for ACP to dynamically adapt to the operating condition for efficiency while ensuring the consistency of the database. Existing ACPs often assume stable operating conditions, hence, they are either non-generalizable to different environments or slow in practice. In this paper, we propose a novel and practical ACP, called Failure-Aware Atomic Commit (FLAC). In essence, FLAC includes three protocols, which are specifically designed for three different environments: (i) no failure occurs, (ii) participant nodes might crash but there is no delayed connection, or (iii) both crashed nodes and delayed connection can occur. It models these environments as the failure-free, crash-failure, and network-failure robustness levels. During its operation, FLAC can monitor if any failure occurs and dynamically switch to operate the most suitable protocol, using a robustness level state machine, whose parameters are fine-tuned by reinforcement learning. Consequently, it improves both the response time and throughput, and effectively handles nodes distributed across the Internet where crash and network failures might occur. We implement FLAC in a distributed transactional key-value storage system based on Google Percolator and evaluate its performance with both a micro benchmark and a macro benchmark of real workload. The results show that FLAC achieves up to 2.22x throughput improvement and 2.82x latency speedup, compared to existing ACPs for high-contention workloads.
Sense The Physical, Walkthrough The Virtual, Manage The Metaverse: A Data-centric Perspective
Jun 14, 2022
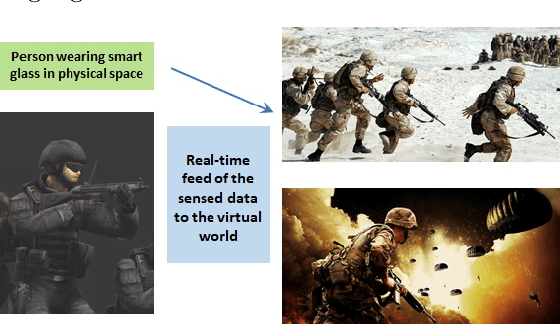
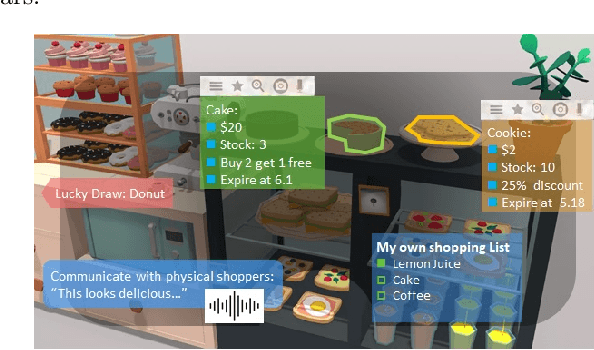

In the Metaverse, the physical space and the virtual space co-exist, and interact simultaneously. While the physical space is virtually enhanced with information, the virtual space is continuously refreshed with real-time, real-world information. To allow users to process and manipulate information seamlessly between the real and digital spaces, novel technologies must be developed. These include smart interfaces, new augmented realities, efficient storage and data management and dissemination techniques. In this paper, we first discuss some promising co-space applications. These applications offer experiences and opportunities that neither of the spaces can realize on its own. We then argue that the database community has much to offer to this field. Finally, we present several challenges that we, as a community, can contribute towards managing the Metaverse.
Towards Robust Cross-domain Image Understanding with Unsupervised Noise Removal
Sep 09, 2021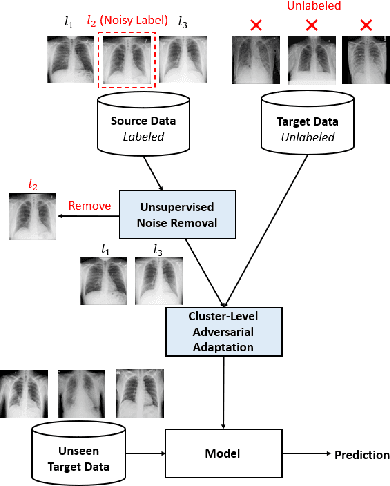
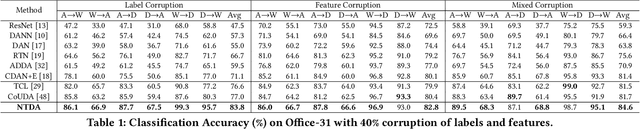
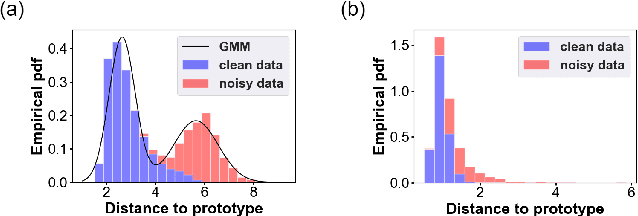
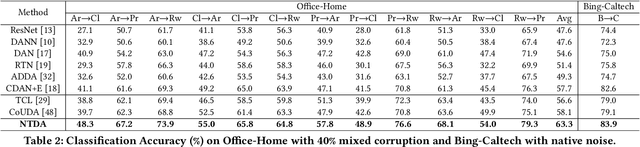
Deep learning models usually require a large amount of labeled data to achieve satisfactory performance. In multimedia analysis, domain adaptation studies the problem of cross-domain knowledge transfer from a label rich source domain to a label scarce target domain, thus potentially alleviates the annotation requirement for deep learning models. However, we find that contemporary domain adaptation methods for cross-domain image understanding perform poorly when source domain is noisy. Weakly Supervised Domain Adaptation (WSDA) studies the domain adaptation problem under the scenario where source data can be noisy. Prior methods on WSDA remove noisy source data and align the marginal distribution across domains without considering the fine-grained semantic structure in the embedding space, which have the problem of class misalignment, e.g., features of cats in the target domain might be mapped near features of dogs in the source domain. In this paper, we propose a novel method, termed Noise Tolerant Domain Adaptation, for WSDA. Specifically, we adopt the cluster assumption and learn cluster discriminatively with class prototypes in the embedding space. We propose to leverage the location information of the data points in the embedding space and model the location information with a Gaussian mixture model to identify noisy source data. We then design a network which incorporates the Gaussian mixture noise model as a sub-module for unsupervised noise removal and propose a novel cluster-level adversarial adaptation method which aligns unlabeled target data with the less noisy class prototypes for mapping the semantic structure across domains. We conduct extensive experiments to evaluate the effectiveness of our method on both general images and medical images from COVID-19 and e-commerce datasets. The results show that our method significantly outperforms state-of-the-art WSDA methods.
A Survey on Deep Reinforcement Learning for Data Processing and Analytics
Aug 11, 2021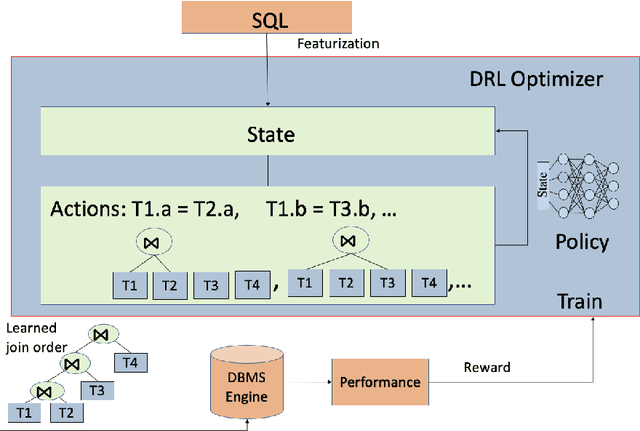
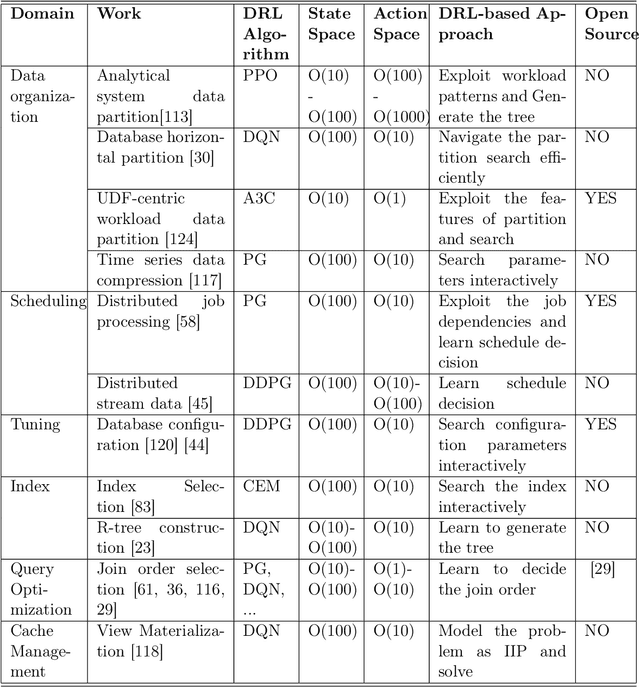
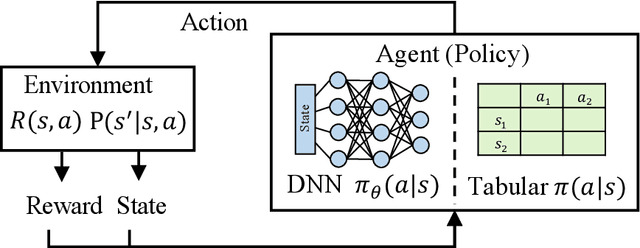

Data processing and analytics are fundamental and pervasive. Algorithms play a vital role in data processing and analytics where many algorithm designs have incorporated heuristics and general rules from human knowledge and experience to improve their effectiveness. Recently, reinforcement learning, deep reinforcement learning (DRL) in particular, is increasingly explored and exploited in many areas because it can learn better strategies in complicated environments it is interacting with than statically designed algorithms. Motivated by this trend, we provide a comprehensive review of recent works focusing on utilizing deep reinforcement learning to improve data processing and analytics. First, we present an introduction to key concepts, theories, and methods in deep reinforcement learning. Next, we discuss deep reinforcement learning deployment on database systems, facilitating data processing and analytics in various aspects, including data organization, scheduling, tuning, and indexing. Then, we survey the application of deep reinforcement learning in data processing and analytics, ranging from data preparation, natural language interface to healthcare, fintech, etc. Finally, we discuss important open challenges and future research directions of using deep reinforcement learning in data processing and analytics.
SINGA-Easy: An Easy-to-Use Framework for MultiModal Analysis
Aug 03, 2021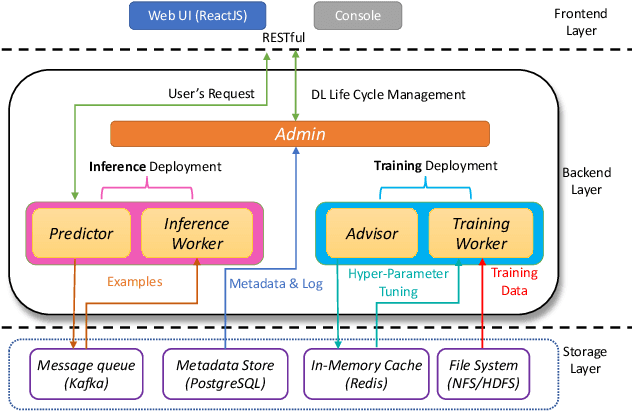

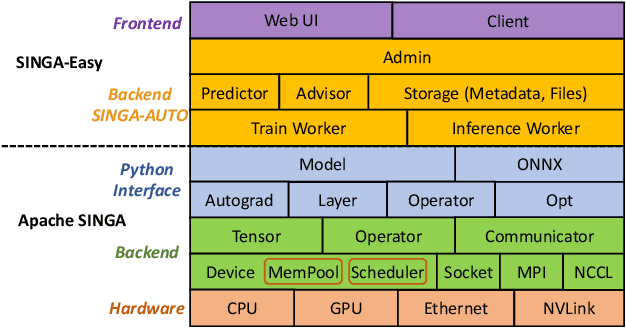

Deep learning has achieved great success in a wide spectrum of multimedia applications such as image classification, natural language processing and multimodal data analysis. Recent years have seen the development of many deep learning frameworks that provide a high-level programming interface for users to design models, conduct training and deploy inference. However, it remains challenging to build an efficient end-to-end multimedia application with most existing frameworks. Specifically, in terms of usability, it is demanding for non-experts to implement deep learning models, obtain the right settings for the entire machine learning pipeline, manage models and datasets, and exploit external data sources all together. Further, in terms of adaptability, elastic computation solutions are much needed as the actual serving workload fluctuates constantly, and scaling the hardware resources to handle the fluctuating workload is typically infeasible. To address these challenges, we introduce SINGA-Easy, a new deep learning framework that provides distributed hyper-parameter tuning at the training stage, dynamic computational cost control at the inference stage, and intuitive user interactions with multimedia contents facilitated by model explanation. Our experiments on the training and deployment of multi-modality data analysis applications show that the framework is both usable and adaptable to dynamic inference loads. We implement SINGA-Easy on top of Apache SINGA and demonstrate our system with the entire machine learning life cycle.