 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of Shapley Value in Data Analytics
Dec 03, 2024



Over the recent years, Shapley value (SV), a solution concept from cooperative game theory, has found numerous applications in data analytics (DA). This paper provides the first comprehensive study of SV used throughout the DA workflow, which involves three main steps: data fabric, data exploration, and result reporting. We summarize existing versatile forms of SV used in these steps by a unified definition and clarify the essential functionalities that SV can provide for data scientists. We categorize the arts in this field based on the technical challenges they tackled, which include computation efficiency, approximation error, privacy preservation, and appropriate interpretations. We discuss these challenges and analyze the corresponding solutions. We also implement SVBench, the first open-sourced benchmark for developing SV applications, and conduct experiments on six DA tasks to validate our analysis and discussions. Based on the qualitative and quantitative results, we identify the limitations of current efforts for applying SV to DA and highlight the directions of future research and engineering.
FL-GUARD: A Holistic Framework for Run-Time Detection and Recovery of Negative Federated Learning
Mar 07, 2024Federated learning (FL) is a promising approach for learning a model from data distributed on massive clients without exposing data privacy. It works effectively in the ideal federation where clients share homogeneous data distribution and learning behavior. However, FL may fail to function appropriately when the federation is not ideal, amid an unhealthy state called Negative Federated Learning (NFL), in which most clients gain no benefit from participating in FL. Many studies have tried to address NFL. However, their solutions either (1) predetermine to prevent NFL in the entire learning life-cycle or (2) tackle NFL in the aftermath of numerous learning rounds. Thus, they either (1) indiscriminately incur extra costs even if FL can perform well without such costs or (2) waste numerous learning rounds. Additionally, none of the previous work takes into account the clients who may be unwilling/unable to follow the proposed NFL solutions when using those solutions to upgrade an FL system in use. This paper introduces FL-GUARD, a holistic framework that can be employed on any FL system for tackling NFL in a run-time paradigm. That is, to dynamically detect NFL at the early stage (tens of rounds) of learning and then to activate recovery measures when necessary. Specifically, we devise a cost-effective NFL detection mechanism, which relies on an estimation of performance gain on clients. Only when NFL is detected, we activate the NFL recovery process, in which each client learns in parallel an adapted model when training the global model. Extensive experiment results confirm the effectiveness of FL-GUARD in detecting NFL and recovering from NFL to a healthy learning state. We also show that FL-GUARD is compatible with previous NFL solutions and robust against clients unwilling/unable to take any recovery measures.
Data Scarcity in Recommendation Systems: A Survey
Dec 08, 2023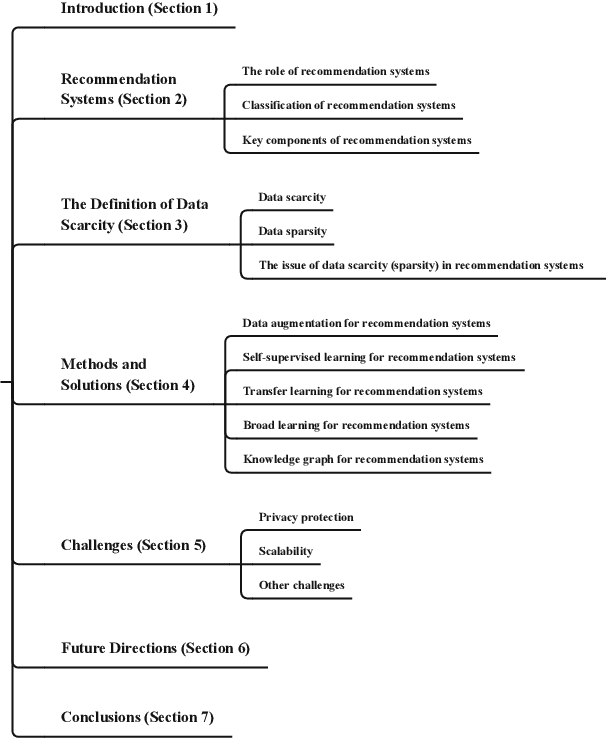
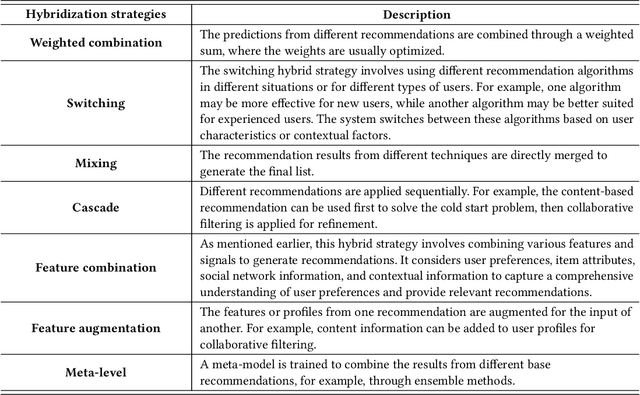
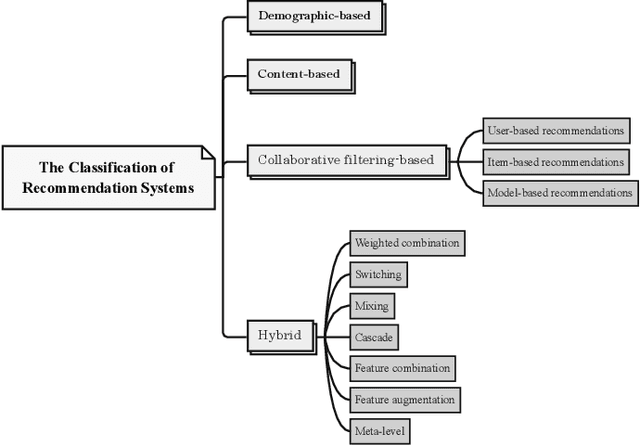
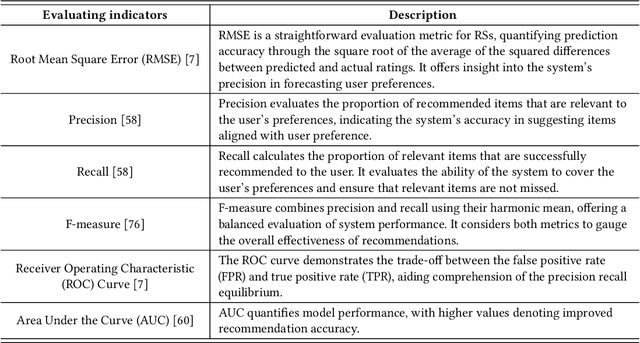
The prevalence of online content has led to the widespread adoption of recommendation systems (RSs), which serve diverse purposes such as news, advertisements, and e-commerce recommendations. Despite their significance, data scarcity issues have significantly impaired the effectiveness of existing RS models and hindered their progress. To address this challenge, the concept of knowledge transfer, particularly from external sources like pre-trained language models, emerges as a potential solution to alleviate data scarcity and enhance RS development. However, the practice of knowledge transfer in RSs is intricate. Transferring knowledge between domains introduces data disparities, and the application of knowledge transfer in complex RS scenarios can yield negative consequences if not carefully designed. Therefore, this article contributes to this discourse by addressing the implications of data scarcity on RSs and introducing various strategies, such as data augmentation, self-supervised learning, transfer learning, broad learning, and knowledge graph utilization, to mitigate this challenge. Furthermore, it delves into the challenges and future direction within the RS domain, offering insights that are poised to facilitate the development and implementation of robust RSs, particularly when confronted with data scarcity. We aim to provide valuable guidance and inspiration for researchers and practitioners, ultimately driving advancements in the field of RS.
AI-Generated Content (AIGC): A Survey
Mar 26, 2023

To address the challenges of digital intelligence in the digital economy, artificial intelligence-generated content (AIGC) has emerged. AIGC uses artificial intelligence to assist or replace manual content generation by generating content based on user-inputted keywords or requirements. The development of large model algorithms has significantly strengthened the capabilities of AIGC, which makes AIGC products a promising generative tool and adds convenience to our lives. As an upstream technology, AIGC has unlimited potential to support different downstream applications. It is important to analyze AIGC's current capabilities and shortcomings to understand how it can be best utilized in future applications. Therefore, this paper provides an extensive overview of AIGC, covering its definition, essential conditions, cutting-edge capabilities, and advanced features. Moreover, it discusses the benefits of large-scale pre-trained models and the industrial chain of AIGC. Furthermore, the article explores the distinctions between auxiliary generation and automatic generation within AIGC, providing examples of text generation. The paper also examines the potential integration of AIGC with the Metaverse. Lastly, the article highlights existing issues and suggests some future directions for application.
Federated Learning Attacks and Defenses: A Survey
Nov 27, 2022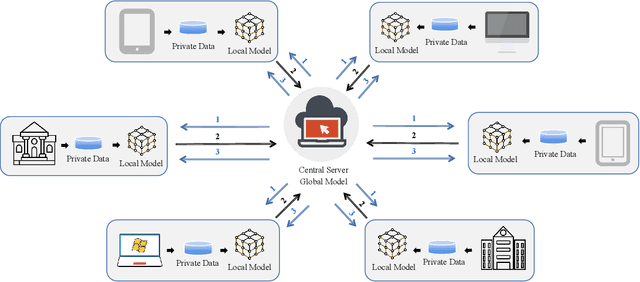
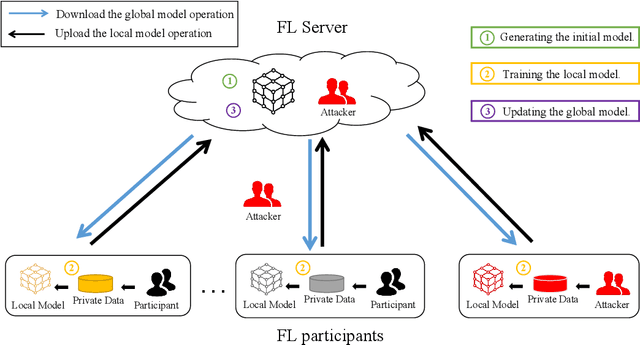
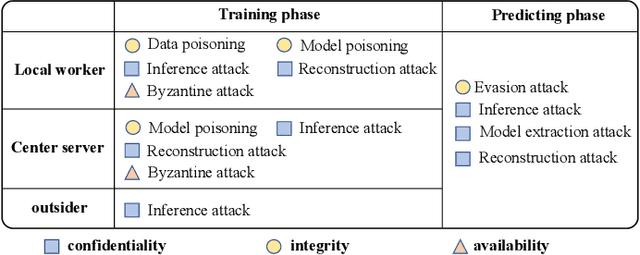
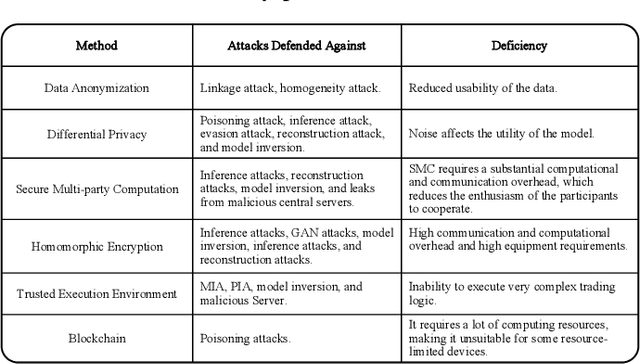
In terms of artificial intelligence, there are several security and privacy deficiencies in the traditional centralized training methods of machine learning models by a server. To address this limitation, federated learning (FL) has been proposed and is known for breaking down ``data silos" and protecting the privacy of users. However, FL has not yet gained popularity in the industry, mainly due to its security, privacy, and high cost of communication. For the purpose of advancing the research in this field, building a robust FL system, and realizing the wide application of FL, this paper sorts out the possible attacks and corresponding defenses of the current FL system systematically. Firstly, this paper briefly introduces the basic workflow of FL and related knowledge of attacks and defenses. It reviews a great deal of research about privacy theft and malicious attacks that have been studied in recent years. Most importantly, in view of the current three classification criteria, namely the three stages of machine learning, the three different roles in federated learning, and the CIA (Confidentiality, Integrity, and Availability) guidelines on privacy protection, we divide attack approaches into two categories according to the training stage and the prediction stage in machine learning. Furthermore, we also identify the CIA property violated for each attack method and potential attack role. Various defense mechanisms are then analyzed separately from the level of privacy and security. Finally, we summarize the possible challenges in the application of FL from the aspect of attacks and defenses and discuss the future development direction of FL systems. In this way, the designed FL system has the ability to resist different attacks and is more secure and stable.
LINDT: Tackling Negative Federated Learning with Local Adaptation
Nov 23, 2020
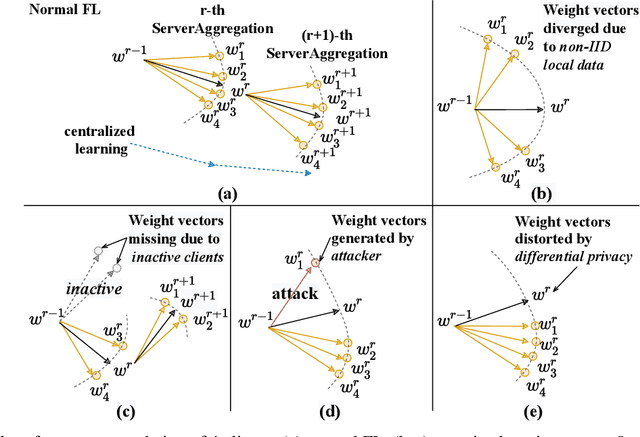
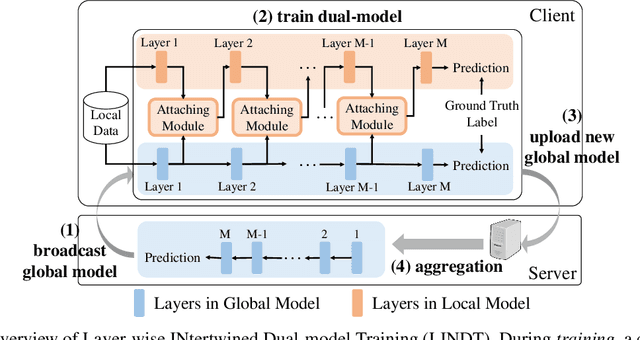

Federated Learning (FL) is a promising distributed learning paradigm, which allows a number of data owners (also called clients) to collaboratively learn a shared model without disclosing each client's data. However, FL may fail to proceed properly, amid a state that we call negative federated learning (NFL). This paper addresses the problem of negative federated learning. We formulate a rigorous definition of NFL and analyze its essential cause. We propose a novel framework called LINDT for tackling NFL in run-time. The framework can potentially work with any neural-network-based FL systems for NFL detection and recovery. Specifically, we introduce a metric for detecting NFL from the server. On occasion of NFL recovery, the framework makes adaptation to the federated model on each client's local data by learning a Layer-wise Intertwined Dual-model. Experiment results show that the proposed approach can significantly improve the performance of FL on local data in various scenarios of NFL.