 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Temporal Awareness in LLMs for Temporal Point Processes
Dec 29, 2025Temporal point processes (TPPs) are crucial for analyzing events over time and are widely used in fields such as finance, healthcare, and social systems. These processes are particularly valuable for understanding how events unfold over time, accounting for their irregularity and dependencies. Despite the success of large language models (LLMs) in sequence modeling, applying them to temporal point processes remains challenging. A key issue is that current methods struggle to effectively capture the complex interaction between temporal information and semantic context, which is vital for accurate event modeling. In this context, we introduce TPP-TAL (Temporal Point Processes with Enhanced Temporal Awareness in LLMs), a novel plug-and-play framework designed to enhance temporal reasoning within LLMs. Rather than using the conventional method of simply concatenating event time and type embeddings, TPP-TAL explicitly aligns temporal dynamics with contextual semantics before feeding this information into the LLM. This alignment allows the model to better perceive temporal dependencies and long-range interactions between events and their surrounding contexts. Through comprehensive experiments on several benchmark datasets, it is shown that TPP-TAL delivers substantial improvements in temporal likelihood estimation and event prediction accuracy, highlighting the importance of enhancing temporal awareness in LLMs for continuous-time event modeling. The code is made available at https://github.com/chenlilil/TPP-TAL
Graph Attention-based Adaptive Transfer Learning for Link Prediction
Dec 24, 2025Graph neural networks (GNNs) have brought revolutionary advancements to the field of link prediction (LP), providing powerful tools for mining potential relationships in graphs. However, existing methods face challenges when dealing with large-scale sparse graphs and the need for a high degree of alignment between different datasets in transfer learning. Besides, although self-supervised methods have achieved remarkable success in many graph tasks, prior research has overlooked the potential of transfer learning to generalize across different graph datasets. To address these limitations, we propose a novel Graph Attention Adaptive Transfer Network (GAATNet). It combines the advantages of pre-training and fine-tuning to capture global node embedding information across datasets of different scales, ensuring efficient knowledge transfer and improved LP performance. To enhance the model's generalization ability and accelerate training, we design two key strategies: 1) Incorporate distant neighbor embeddings as biases in the self-attention module to capture global features. 2) Introduce a lightweight self-adapter module during fine-tuning to improve training efficiency. Comprehensive experiments on seven public datasets demonstrate that GAATNet achieves state-of-the-art performance in LP tasks. This study provides a general and scalable solution for LP tasks to effectively integrate GNNs with transfer learning. The source code and datasets are publicly available at https://github.com/DSI-Lab1/GAATNet
Graph Diffusion Network for Drug-Gene Prediction
Feb 13, 2025


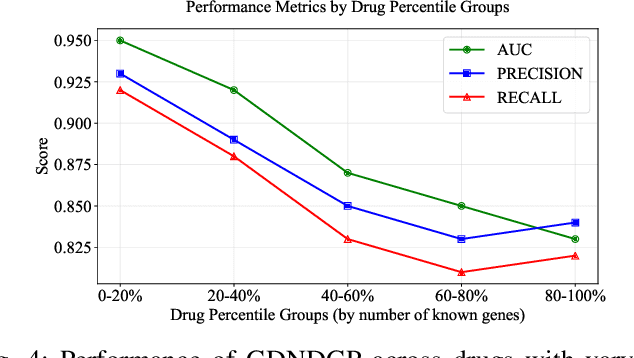
Predicting drug-gene associations is crucial for drug development and disease treatment. While graph neural networks (GNN) have shown effectiveness in this task, they face challenges with data sparsity and efficient contrastive learning implementation. We introduce a graph diffusion network for drug-gene prediction (GDNDGP), a framework that addresses these limitations through two key innovations. First, it employs meta-path-based homogeneous graph learning to capture drug-drug and gene-gene relationships, ensuring similar entities share embedding spaces. Second, it incorporates a parallel diffusion network that generates hard negative samples during training, eliminating the need for exhaustive negative sample retrieval. Our model achieves superior performance on the DGIdb 4.0 dataset and demonstrates strong generalization capability on tripartite drug-gene-disease networks. Results show significant improvements over existing methods in drug-gene prediction tasks, particularly in handling complex heterogeneous relationships. The source code is publicly available at https://github.com/csjywu1/GDNDGP.
Graph Contrastive Learning on Multi-label Classification for Recommendations
Jan 13, 2025



In business analysis, providing effective recommendations is essential for enhancing company profits. The utilization of graph-based structures, such as bipartite graphs, has gained popularity for their ability to analyze complex data relationships. Link prediction is crucial for recommending specific items to users. Traditional methods in this area often involve identifying patterns in the graph structure or using representational techniques like graph neural networks (GNNs). However, these approaches encounter difficulties as the volume of data increases. To address these challenges, we propose a model called Graph Contrastive Learning for Multi-label Classification (MCGCL). MCGCL leverages contrastive learning to enhance recommendation effectiveness. The model incorporates two training stages: a main task and a subtask. The main task is holistic user-item graph learning to capture user-item relationships. The homogeneous user-user (item-item) subgraph is constructed to capture user-user and item-item relationships in the subtask. We assessed the performance using real-world datasets from Amazon Reviews in multi-label classification tasks. Comparative experiments with state-of-the-art methods confirm the effectiveness of MCGCL, highlighting its potential for improving recommendation systems.
ADKGD: Anomaly Detection in Knowledge Graphs with Dual-Channel Training
Jan 13, 2025
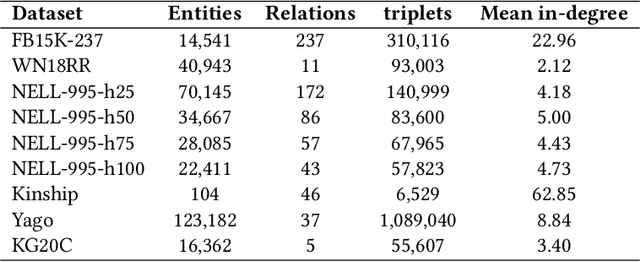
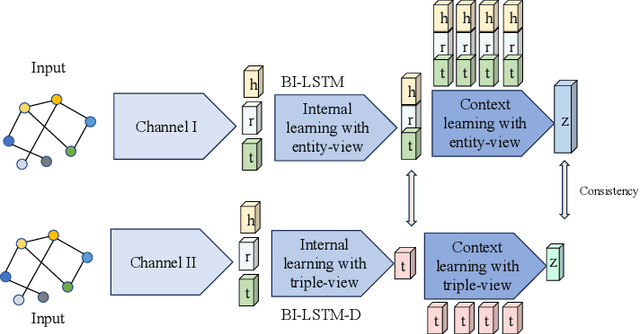

In the current development of large language models (LLMs), it is important to ensure the accuracy and reliability of the underlying data sources. LLMs are critical for various applications, but they often suffer from hallucinations and inaccuracies due to knowledge gaps in the training data. Knowledge graphs (KGs), as a powerful structural tool, could serve as a vital external information source to mitigate the aforementioned issues. By providing a structured and comprehensive understanding of real-world data, KGs enhance the performance and reliability of LLMs. However, it is common that errors exist in KGs while extracting triplets from unstructured data to construct KGs. This could lead to degraded performance in downstream tasks such as question-answering and recommender systems. Therefore, anomaly detection in KGs is essential to identify and correct these errors. This paper presents an anomaly detection algorithm in knowledge graphs with dual-channel learning (ADKGD). ADKGD leverages a dual-channel learning approach to enhance representation learning from both the entity-view and triplet-view perspectives. Furthermore, using a cross-layer approach, our framework integrates internal information aggregation and context information aggregation. We introduce a kullback-leibler (KL)-loss component to improve the accuracy of the scoring function between the dual channels. To evaluate ADKGD's performance, we conduct empirical studies on three real-world KGs: WN18RR, FB15K, and NELL-995. Experimental results demonstrate that ADKGD outperforms the state-of-the-art anomaly detection algorithms. The source code and datasets are publicly available at https://github.com/csjywu1/ADKGD.
Artificial Intelligence in Landscape Architecture: A Survey
Aug 26, 2024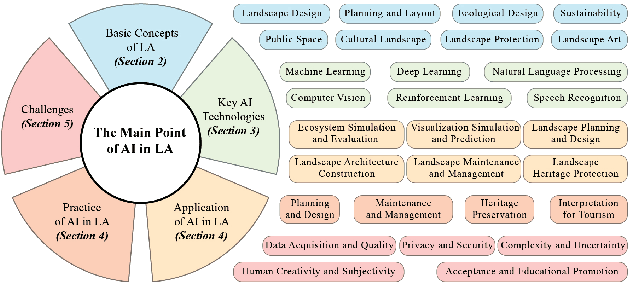
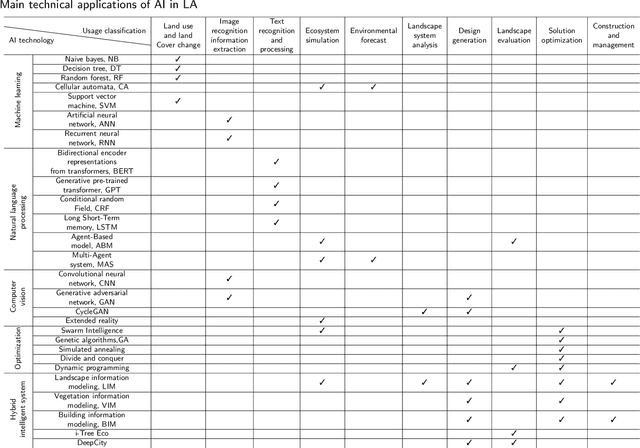
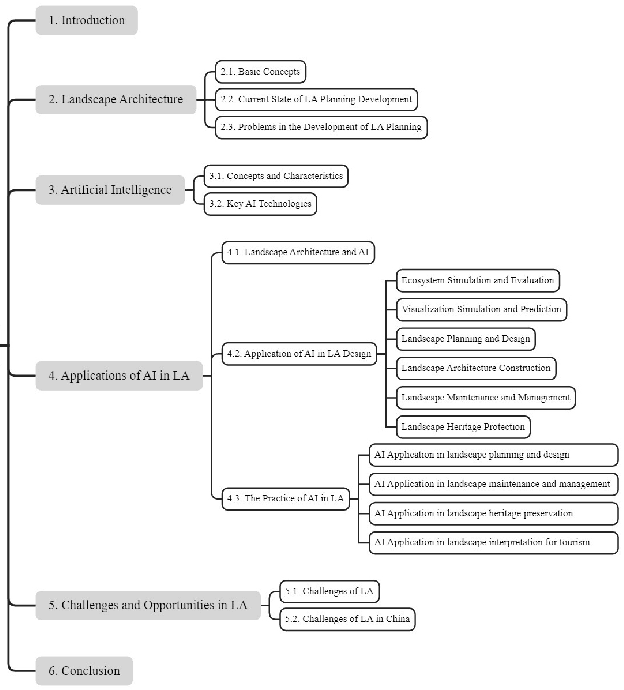
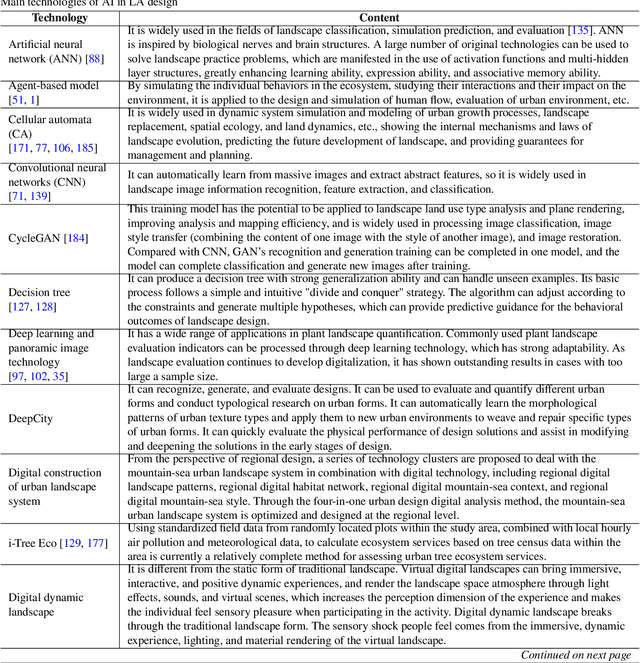
The development history of landscape architecture (LA) reflects the human pursuit of environmental beautification and ecological balance. With the advancement of artificial intelligence (AI) technologies that simulate and extend human intelligence, immense opportunities have been provided for LA, offering scientific and technological support throughout the entire workflow. In this article, we comprehensively review the applications of AI technology in the field of LA. First, we introduce the many potential benefits that AI brings to the design, planning, and management aspects of LA. Secondly, we discuss how AI can assist the LA field in solving its current development problems, including urbanization, environmental degradation and ecological decline, irrational planning, insufficient management and maintenance, and lack of public participation. Furthermore, we summarize the key technologies and practical cases of applying AI in the LA domain, from design assistance to intelligent management, all of which provide innovative solutions for the planning, design, and maintenance of LA. Finally, we look ahead to the problems and opportunities in LA, emphasizing the need to combine human expertise and judgment for rational decision-making. This article provides both theoretical and practical guidance for LA designers, researchers, and technology developers. The successful integration of AI technology into LA holds great promise for enhancing the field's capabilities and achieving more sustainable, efficient, and user-friendly outcomes.
Large Language Models for Medicine: A Survey
May 20, 2024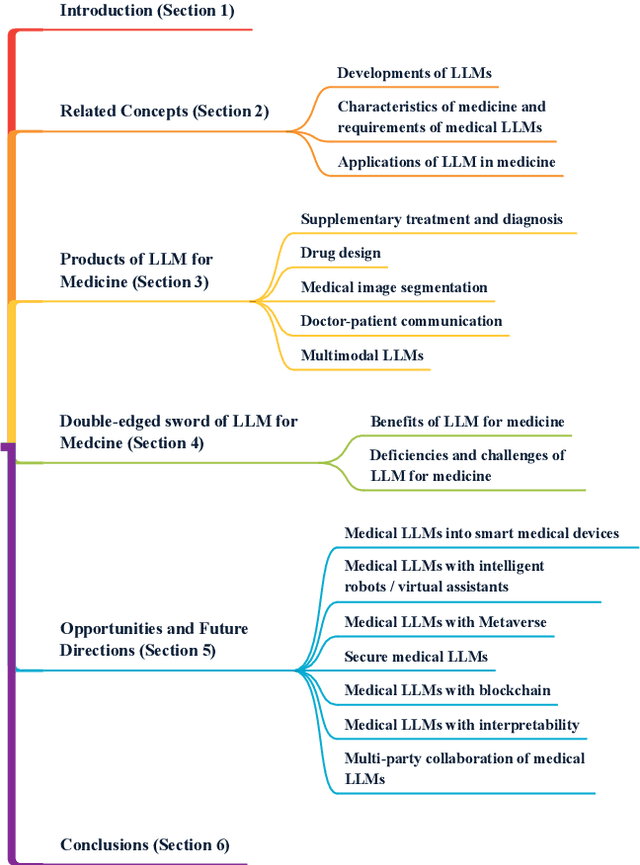
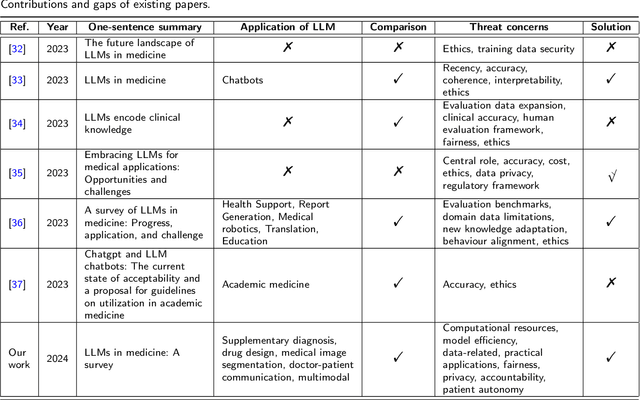
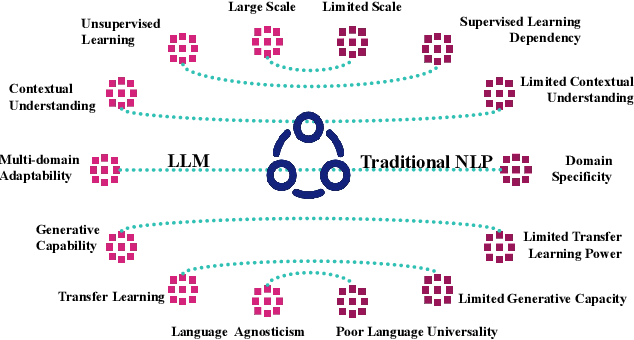
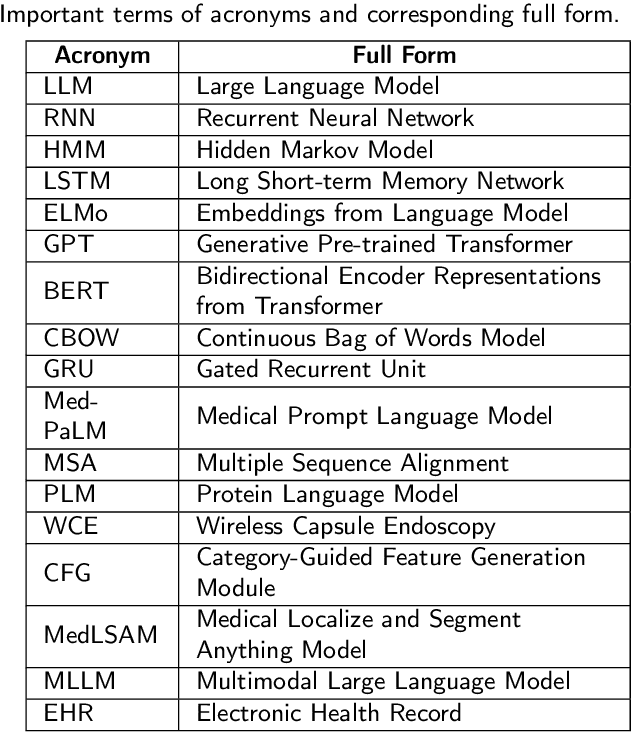
To address challenges in the digital economy's landscape of digital intelligence, large language models (LLMs) have been developed. Improvements in computational power and available resources have significantly advanced LLMs, allowing their integration into diverse domains for human life. Medical LLMs are essential application tools with potential across various medical scenarios. In this paper, we review LLM developments, focusing on the requirements and applications of medical LLMs. We provide a concise overview of existing models, aiming to explore advanced research directions and benefit researchers for future medical applications. We emphasize the advantages of medical LLMs in applications, as well as the challenges encountered during their development. Finally, we suggest directions for technical integration to mitigate challenges and potential research directions for the future of medical LLMs, aiming to meet the demands of the medical field better.
Data Scarcity in Recommendation Systems: A Survey
Dec 08, 2023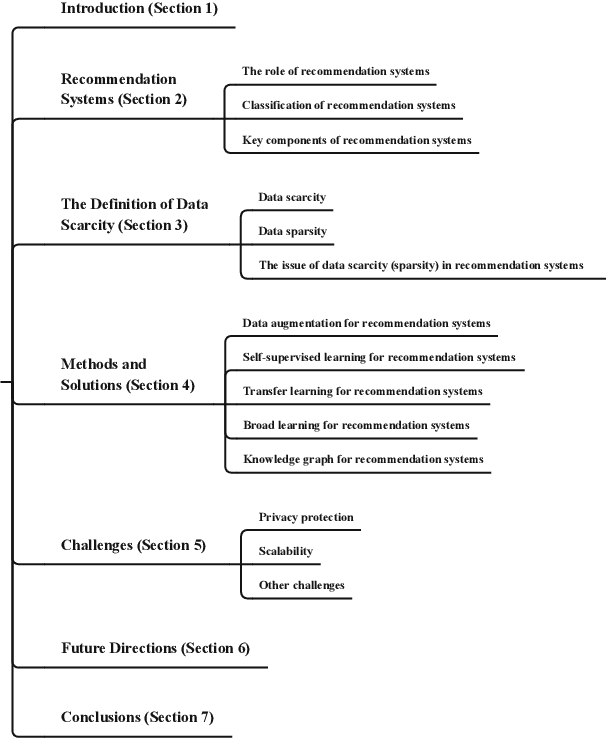
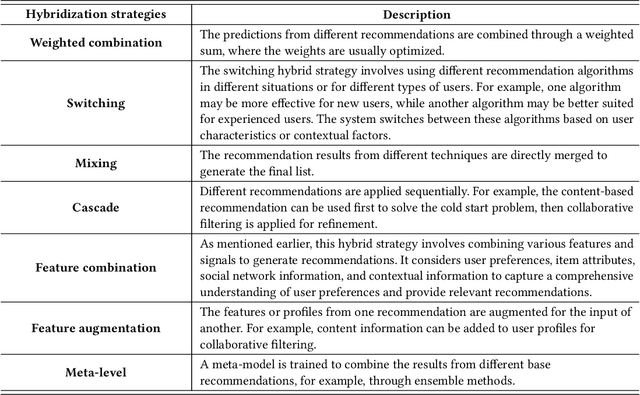
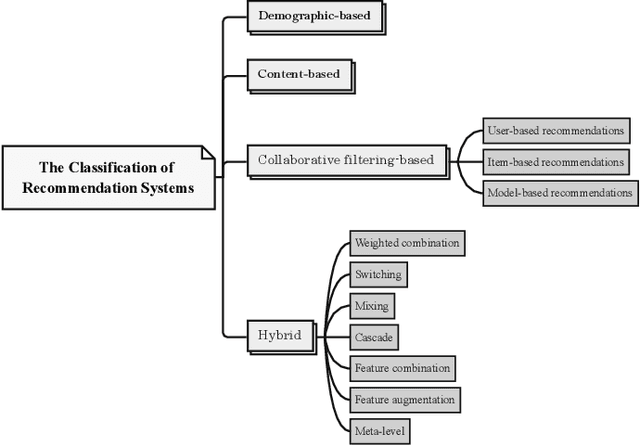
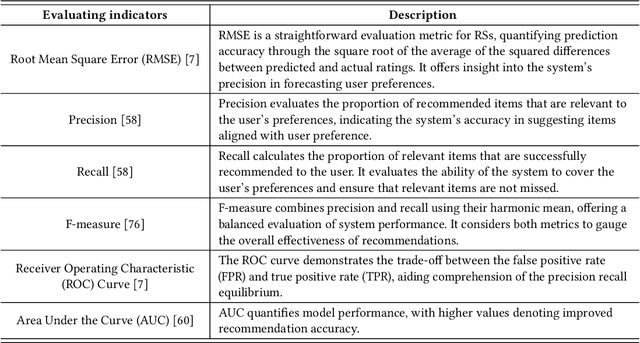
The prevalence of online content has led to the widespread adoption of recommendation systems (RSs), which serve diverse purposes such as news, advertisements, and e-commerce recommendations. Despite their significance, data scarcity issues have significantly impaired the effectiveness of existing RS models and hindered their progress. To address this challenge, the concept of knowledge transfer, particularly from external sources like pre-trained language models, emerges as a potential solution to alleviate data scarcity and enhance RS development. However, the practice of knowledge transfer in RSs is intricate. Transferring knowledge between domains introduces data disparities, and the application of knowledge transfer in complex RS scenarios can yield negative consequences if not carefully designed. Therefore, this article contributes to this discourse by addressing the implications of data scarcity on RSs and introducing various strategies, such as data augmentation, self-supervised learning, transfer learning, broad learning, and knowledge graph utilization, to mitigate this challenge. Furthermore, it delves into the challenges and future direction within the RS domain, offering insights that are poised to facilitate the development and implementation of robust RSs, particularly when confronted with data scarcity. We aim to provide valuable guidance and inspiration for researchers and practitioners, ultimately driving advancements in the field of RS.
Large Language Models in Law: A Survey
Nov 26, 2023The advent of artificial intelligence (AI) has significantly impacted the traditional judicial industry. Moreover, recently, with the development of AI-generated content (AIGC), AI and law have found applications in various domains, including image recognition, automatic text generation, and interactive chat. With the rapid emergence and growing popularity of large models, it is evident that AI will drive transformation in the traditional judicial industry. However, the application of legal large language models (LLMs) is still in its nascent stage. Several challenges need to be addressed. In this paper, we aim to provide a comprehensive survey of legal LLMs. We not only conduct an extensive survey of LLMs, but also expose their applications in the judicial system. We first provide an overview of AI technologies in the legal field and showcase the recent research in LLMs. Then, we discuss the practical implementation presented by legal LLMs, such as providing legal advice to users and assisting judges during trials. In addition, we explore the limitations of legal LLMs, including data, algorithms, and judicial practice. Finally, we summarize practical recommendations and propose future development directions to address these challenges.
Multimodal Large Language Models: A Survey
Nov 22, 2023



The exploration of multimodal language models integrates multiple data types, such as images, text, language, audio, and other heterogeneity. While the latest large language models excel in text-based tasks, they often struggle to understand and process other data types. Multimodal models address this limitation by combining various modalities, enabling a more comprehensive understanding of diverse data. This paper begins by defining the concept of multimodal and examining the historical development of multimodal algorithms. Furthermore, we introduce a range of multimodal products, focusing on the efforts of major technology companies. A practical guide is provided, offering insights into the technical aspects of multimodal models. Moreover, we present a compilation of the latest algorithms and commonly used datasets, providing researchers with valuable resources for experimentation and evaluation. Lastly, we explore the applications of multimodal models and discuss the challenges associated with their development. By addressing these aspects, this paper aims to facilitate a deeper understanding of multimodal models and their potential in various domains.