 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Large Language Models: A Survey
Nov 22, 2023



The exploration of multimodal language models integrates multiple data types, such as images, text, language, audio, and other heterogeneity. While the latest large language models excel in text-based tasks, they often struggle to understand and process other data types. Multimodal models address this limitation by combining various modalities, enabling a more comprehensive understanding of diverse data. This paper begins by defining the concept of multimodal and examining the historical development of multimodal algorithms. Furthermore, we introduce a range of multimodal products, focusing on the efforts of major technology companies. A practical guide is provided, offering insights into the technical aspects of multimodal models. Moreover, we present a compilation of the latest algorithms and commonly used datasets, providing researchers with valuable resources for experimentation and evaluation. Lastly, we explore the applications of multimodal models and discuss the challenges associated with their development. By addressing these aspects, this paper aims to facilitate a deeper understanding of multimodal models and their potential in various domains.
Model-as-a-Service (MaaS): A Survey
Nov 10, 2023Due to the increased number of parameters and data in the pre-trained model exceeding a certain level, a foundation model (e.g., a large language model) can significantly improve downstream task performance and emerge with some novel special abilities (e.g., deep learning, complex reasoning, and human alignment) that were not present before. Foundation models are a form of generative artificial intelligence (GenAI), and Model-as-a-Service (MaaS) has emerged as a groundbreaking paradigm that revolutionizes the deployment and utilization of GenAI models. MaaS represents a paradigm shift in how we use AI technologies and provides a scalable and accessible solution for developers and users to leverage pre-trained AI models without the need for extensive infrastructure or expertise in model training. In this paper, the introduction aims to provide a comprehensive overview of MaaS, its significance, and its implications for various industries. We provide a brief review of the development history of "X-as-a-Service" based on cloud computing and present the key technologies involved in MaaS. The development of GenAI models will become more democratized and flourish. We also review recent application studies of MaaS. Finally, we highlight several challenges and future issues in this promising area. MaaS is a new deployment and service paradigm for different AI-based models. We hope this review will inspire future research in the field of MaaS.
AI-Generated Content (AIGC): A Survey
Mar 26, 2023

To address the challenges of digital intelligence in the digital economy, artificial intelligence-generated content (AIGC) has emerged. AIGC uses artificial intelligence to assist or replace manual content generation by generating content based on user-inputted keywords or requirements. The development of large model algorithms has significantly strengthened the capabilities of AIGC, which makes AIGC products a promising generative tool and adds convenience to our lives. As an upstream technology, AIGC has unlimited potential to support different downstream applications. It is important to analyze AIGC's current capabilities and shortcomings to understand how it can be best utilized in future applications. Therefore, this paper provides an extensive overview of AIGC, covering its definition, essential conditions, cutting-edge capabilities, and advanced features. Moreover, it discusses the benefits of large-scale pre-trained models and the industrial chain of AIGC. Furthermore, the article explores the distinctions between auxiliary generation and automatic generation within AIGC, providing examples of text generation. The paper also examines the potential integration of AIGC with the Metaverse. Lastly, the article highlights existing issues and suggests some future directions for application.
MDL-based Compressing Sequential Rules
Dec 20, 2022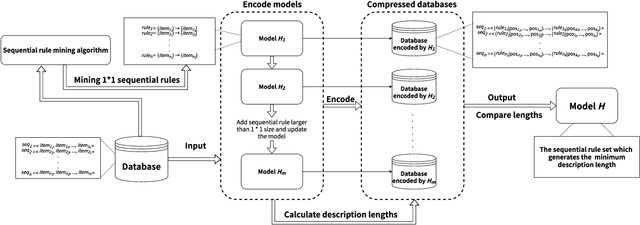
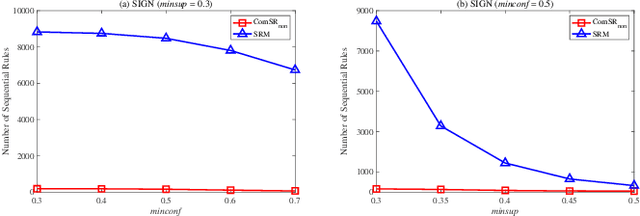

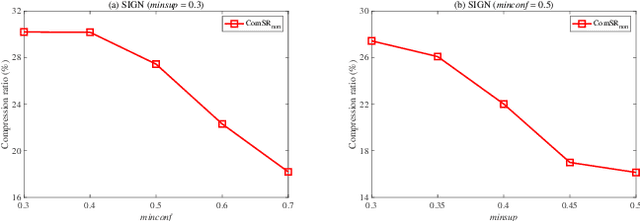
Nowadays, with the rapid development of the Internet, the era of big data has come. The Internet generates huge amounts of data every day. However, extracting meaningful information from massive data is like looking for a needle in a haystack. Data mining techniques can provide various feasible methods to solve this problem. At present, many sequential rule mining (SRM) algorithms are presented to find sequential rules in databases with sequential characteristics. These rules help people extract a lot of meaningful information from massive amounts of data. How can we achieve compression of mined results and reduce data size to save storage space and transmission time? Until now, there has been little research on the compression of SRM. In this paper, combined with the Minimum Description Length (MDL) principle and under the two metrics (support and confidence), we introduce the problem of compression of SRM and also propose a solution named ComSR for MDL-based compressing of sequential rules based on the designed sequential rule coding scheme. To our knowledge, we are the first to use sequential rules to encode an entire database. A heuristic method is proposed to find a set of compact and meaningful sequential rules as much as possible. ComSR has two trade-off algorithms, ComSR_non and ComSR_ful, based on whether the database can be completely compressed. Experiments done on a real dataset with different thresholds show that a set of compact and meaningful sequential rules can be found. This shows that the proposed method works.
Itemset Utility Maximization with Correlation Measure
Aug 26, 2022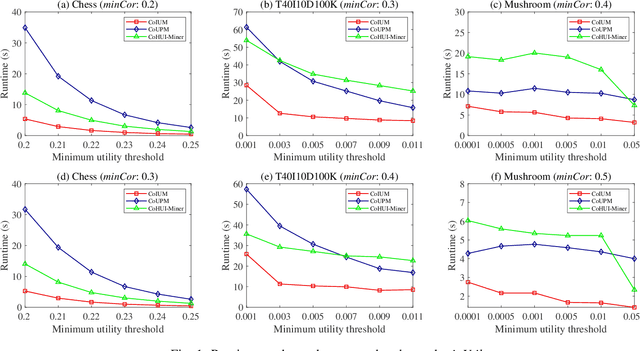
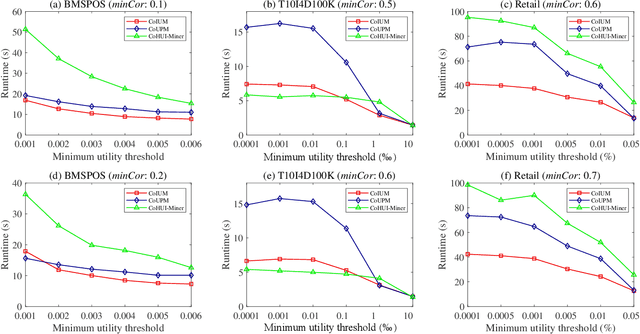
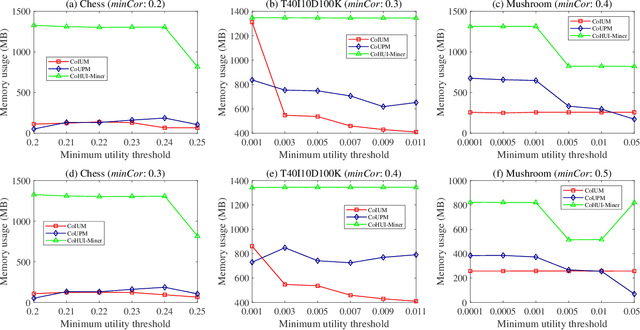
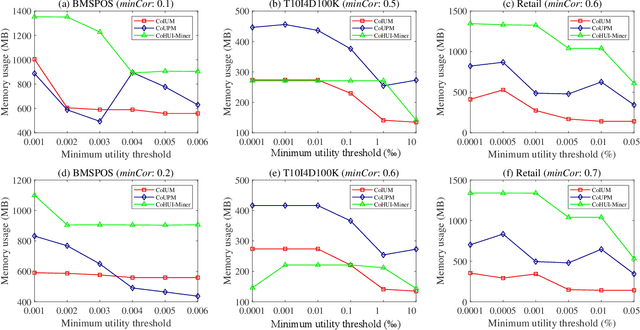
As an important data mining technology, high utility itemset mining (HUIM) is used to find out interesting but hidden information (e.g., profit and risk). HUIM has been widely applied in many application scenarios, such as market analysis, medical detection, and web click stream analysis. However, most previous HUIM approaches often ignore the relationship between items in an itemset. Therefore, many irrelevant combinations (e.g., \{gold, apple\} and \{notebook, book\}) are discovered in HUIM. To address this limitation, many algorithms have been proposed to mine correlated high utility itemsets (CoHUIs). In this paper, we propose a novel algorithm called the Itemset Utility Maximization with Correlation Measure (CoIUM), which considers both a strong correlation and the profitable values of the items. Besides, the novel algorithm adopts a database projection mechanism to reduce the cost of database scanning. Moreover, two upper bounds and four pruning strategies are utilized to effectively prune the search space. And a concise array-based structure named utility-bin is used to calculate and store the adopted upper bounds in linear time and space. Finally, extensive experimental results on dense and sparse datasets demonstrate that CoIUM significantly outperforms the state-of-the-art algorithms in terms of runtime and memory consumption.
Temporal Fuzzy Utility Maximization with Remaining Measure
Aug 26, 2022

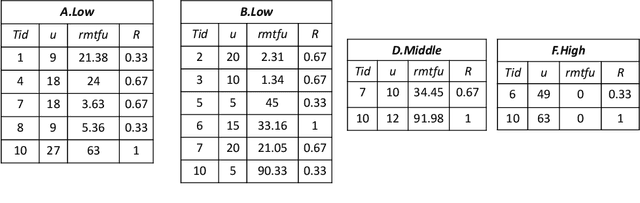
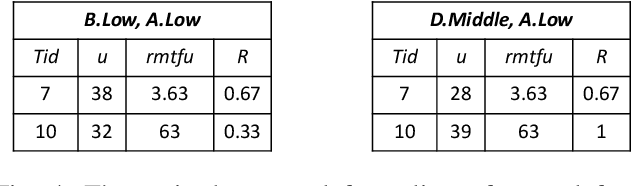
High utility itemset mining approaches discover hidden patterns from large amounts of temporal data. However, an inescapable problem of high utility itemset mining is that its discovered results hide the quantities of patterns, which causes poor interpretability. The results only reflect the shopping trends of customers, which cannot help decision makers quantify collected information. In linguistic terms, computers use mathematical or programming languages that are precisely formalized, but the language used by humans is always ambiguous. In this paper, we propose a novel one-phase temporal fuzzy utility itemset mining approach called TFUM. It revises temporal fuzzy-lists to maintain less but major information about potential high temporal fuzzy utility itemsets in memory, and then discovers a complete set of real interesting patterns in a short time. In particular, the remaining measure is the first adopted in the temporal fuzzy utility itemset mining domain in this paper. The remaining maximal temporal fuzzy utility is a tighter and stronger upper bound than that of previous studies adopted. Hence, it plays an important role in pruning the search space in TFUM. Finally, we also evaluate the efficiency and effectiveness of TFUM on various datasets. Extensive experimental results indicate that TFUM outperforms the state-of-the-art algorithms in terms of runtime cost, memory usage, and scalability. In addition, experiments prove that the remaining measure can significantly prune unnecessary candidates during mining.
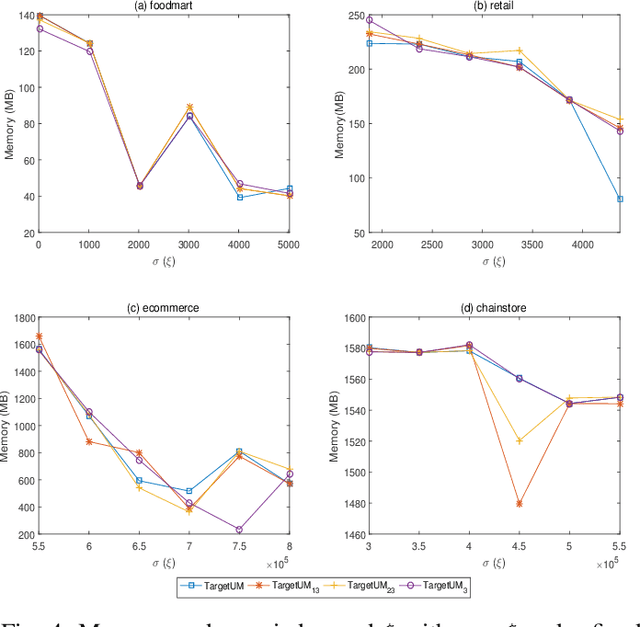
Towards Target High-Utility Itemsets
Jun 09, 2022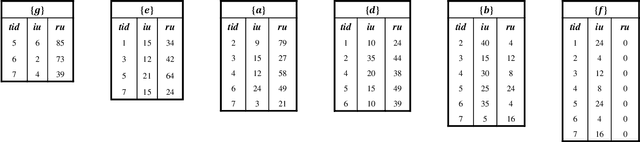

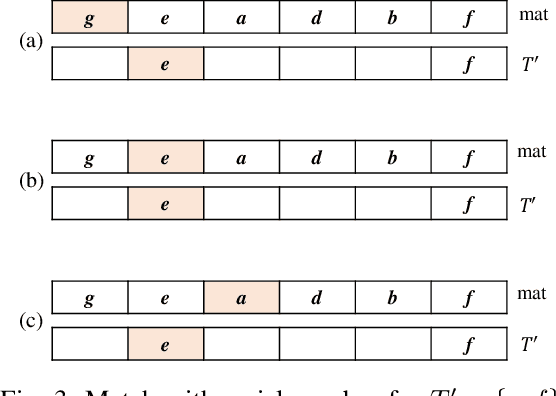
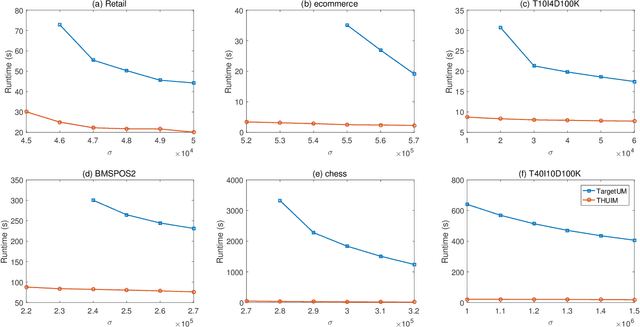
For applied intelligence, utility-driven pattern discovery algorithms can identify insightful and useful patterns in databases. However, in these techniques for pattern discovery, the number of patterns can be huge, and the user is often only interested in a few of those patterns. Hence, targeted high-utility itemset mining has emerged as a key research topic, where the aim is to find a subset of patterns that meet a targeted pattern constraint instead of all patterns. This is a challenging task because efficiently finding tailored patterns in a very large search space requires a targeted mining algorithm. A first algorithm called TargetUM has been proposed, which adopts an approach similar to post-processing using a tree structure, but the running time and memory consumption are unsatisfactory in many situations. In this paper, we address this issue by proposing a novel list-based algorithm with pattern matching mechanism, named THUIM (Targeted High-Utility Itemset Mining), which can quickly match high-utility itemsets during the mining process to select the targeted patterns. Extensive experiments were conducted on different datasets to compare the performance of the proposed algorithm with state-of-the-art algorithms. Results show that THUIM performs very well in terms of runtime and memory consumption, and has good scalability compared to TargetUM.
Anomaly Rule Detection in Sequence Data
Nov 29, 2021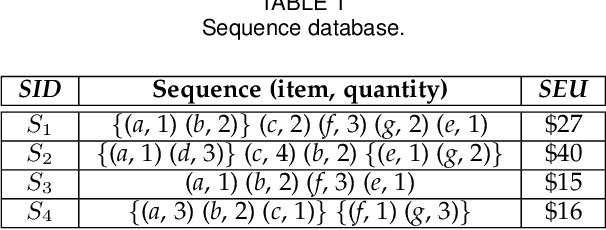
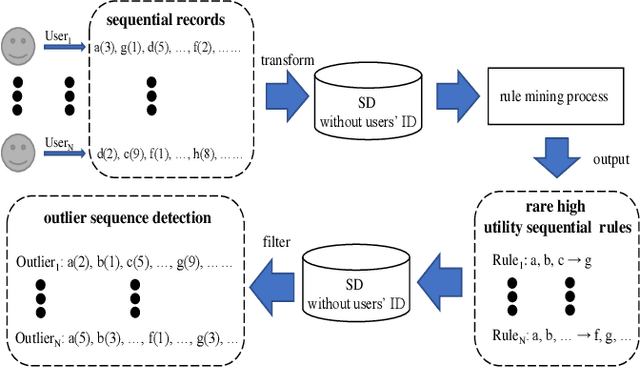


Analyzing sequence data usually leads to the discovery of interesting patterns and then anomaly detection. In recent years, numerous frameworks and methods have been proposed to discover interesting patterns in sequence data as well as detect anomalous behavior. However, existing algorithms mainly focus on frequency-driven analytic, and they are challenging to be applied in real-world settings. In this work, we present a new anomaly detection framework called DUOS that enables Discovery of Utility-aware Outlier Sequential rules from a set of sequences. In this pattern-based anomaly detection algorithm, we incorporate both the anomalousness and utility of a group, and then introduce the concept of utility-aware outlier sequential rule (UOSR). We show that this is a more meaningful way for detecting anomalies. Besides, we propose some efficient pruning strategies w.r.t. upper bounds for mining UOSR, as well as the outlier detection. An extensive experimental study conducted on several real-world datasets shows that the proposed DUOS algorithm has a better effectiveness and efficiency. Finally, DUOS outperforms the baseline algorithm and has a suitable scalability.
TargetUM: Targeted High-Utility Itemset Querying
Oct 30, 2021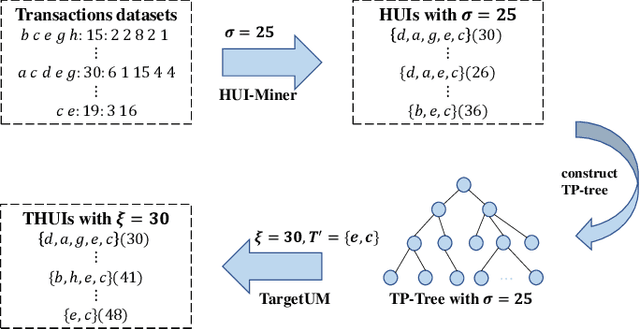
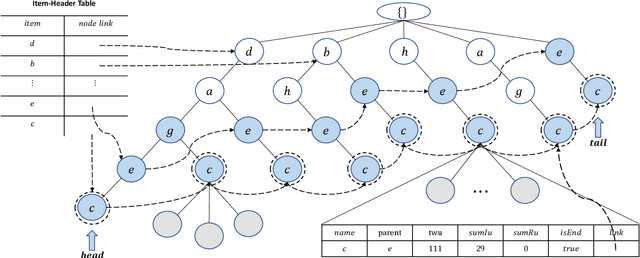

Traditional high-utility itemset mining (HUIM) aims to determine all high-utility itemsets (HUIs) that satisfy the minimum utility threshold (\textit{minUtil}) in transaction databases. However, in most applications, not all HUIs are interesting because only specific parts are required. Thus, targeted mining based on user preferences is more important than traditional mining tasks. This paper is the first to propose a target-based HUIM problem and to provide a clear formulation of the targeted utility mining task in a quantitative transaction database. A tree-based algorithm known as Target-based high-Utility iteMset querying using (TargetUM) is proposed. The algorithm uses a lexicographic querying tree and three effective pruning strategies to improve the mining efficiency. We implemented experimental validation on several real and synthetic databases, and the results demonstrate that the performance of \textbf{TargetUM} is satisfactory, complete, and correct. Finally, owing to the lexicographic querying tree, the database no longer needs to be scanned repeatedly for multiple queries.