 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Corrected Labels Learning: Enhancing Labels Quality via Human Correction of VLMs Discrepancies
Nov 14, 2025Vision-Language Models (VLMs), with their powerful content generation capabilities, have been successfully applied to data annotation processes. However, the VLM-generated labels exhibit dual limitations: low quality (i.e., label noise) and absence of error correction mechanisms. To enhance label quality, we propose Human-Corrected Labels (HCLs), a novel setting that efficient human correction for VLM-generated noisy labels. As shown in Figure 1(b), HCL strategically deploys human correction only for instances with VLM discrepancies, achieving both higher-quality annotations and reduced labor costs. Specifically, we theoretically derive a risk-consistent estimator that incorporates both human-corrected labels and VLM predictions to train classifiers. Besides, we further propose a conditional probability method to estimate the label distribution using a combination of VLM outputs and model predictions. Extensive experiments demonstrate that our approach achieves superior classification performance and is robust to label noise, validating the effectiveness of HCL in practical weak supervision scenarios. Code https://github.com/Lilianach24/HCL.git
Multi-Scale Attention for Audio Question Answering
May 29, 2023Audio question answering (AQA), acting as a widely used proxy task to explore scene understanding, has got more attention. The AQA is challenging for it requires comprehensive temporal reasoning from different scales' events of an audio scene. However, existing methods mostly extend the structures of visual question answering task to audio ones in a simple pattern but may not perform well when perceiving a fine-grained audio scene. To this end, we present a Multi-scale Window Attention Fusion Model (MWAFM) consisting of an asynchronous hybrid attention module and a multi-scale window attention module. The former is designed to aggregate unimodal and cross-modal temporal contexts, while the latter captures sound events of varying lengths and their temporal dependencies for a more comprehensive understanding. Extensive experiments are conducted to demonstrate that the proposed MWAFM can effectively explore temporal information to facilitate AQA in the fine-grained scene.Code: https://github.com/GeWu-Lab/MWAFM
TikTalk: A Multi-Modal Dialogue Dataset for Real-World Chitchat
Jan 14, 2023
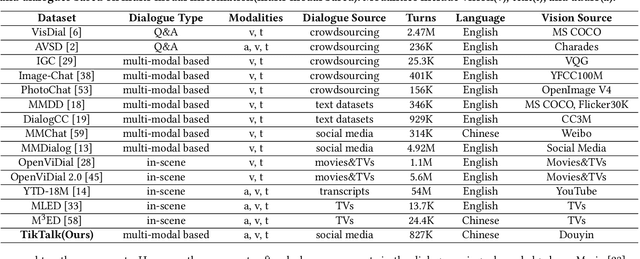

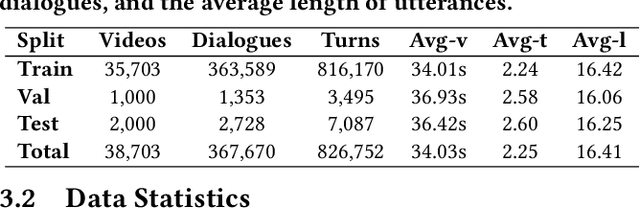
We present a novel multi-modal chitchat dialogue dataset-TikTalk aimed at facilitating the research of intelligent chatbots. It consists of the videos and corresponding dialogues users generate on video social applications. In contrast to existing multi-modal dialogue datasets, we construct dialogue corpora based on video comment-reply pairs, which is more similar to chitchat in real-world dialogue scenarios. Our dialogue context includes three modalities: text, vision, and audio. Compared with previous image-based dialogue datasets, the richer sources of context in TikTalk lead to a greater diversity of conversations. TikTalk contains over 38K videos and 367K dialogues. Data analysis shows that responses in TikTalk are in correlation with various contexts and external knowledge. It poses a great challenge for the deep understanding of multi-modal information and the generation of responses. We evaluate several baselines on three types of automatic metrics and conduct case studies. Experimental results demonstrate that there is still a large room for future improvement on TikTalk. Our dataset is available at \url{https://github.com/RUC-AIMind/TikTalk}.
A Nonlinear Sum of Squares Search for CAZAC Sequences
Nov 02, 2022
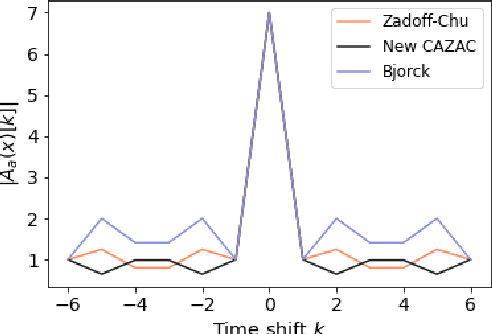
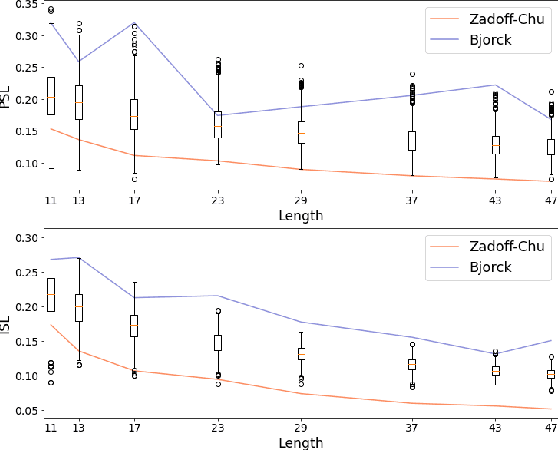
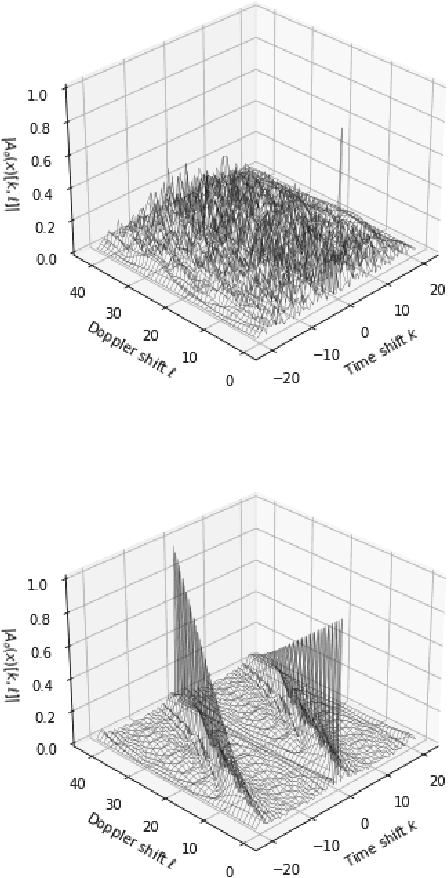
We report on a search for CAZAC sequences by using nonlinear sum of squares optimization. Up to equivalence, we found all length 7 CAZAC sequences. We obtained evidence suggesting there are finitely many length 10 CAZAC sequences with a total of 3040 sequences. Last, we compute longer sequences and compare their aperiodic autocorrelation properties to known sequences. The code and results of this search are publicly available through GitHub.
Itemset Utility Maximization with Correlation Measure
Aug 26, 2022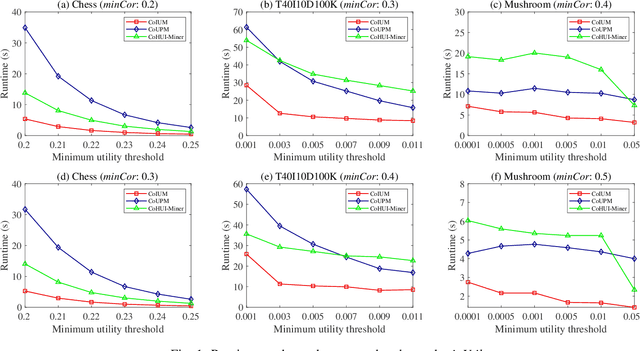
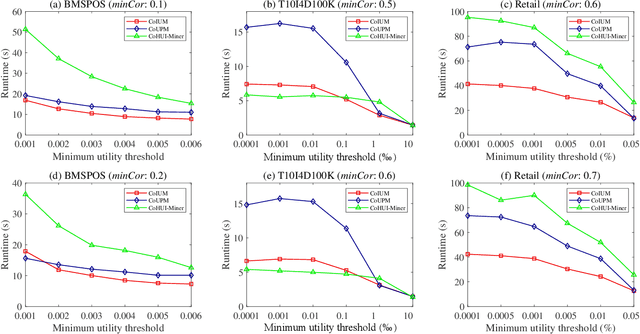
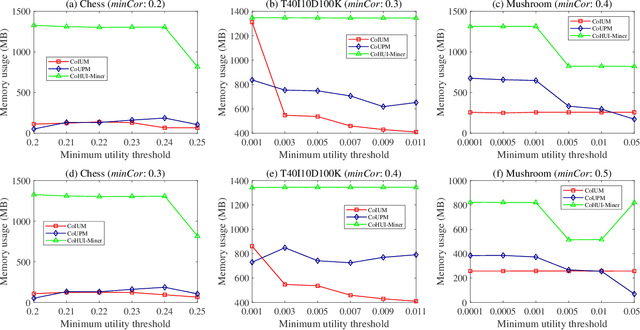
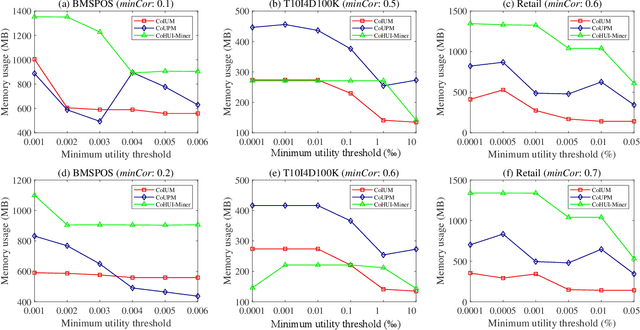
As an important data mining technology, high utility itemset mining (HUIM) is used to find out interesting but hidden information (e.g., profit and risk). HUIM has been widely applied in many application scenarios, such as market analysis, medical detection, and web click stream analysis. However, most previous HUIM approaches often ignore the relationship between items in an itemset. Therefore, many irrelevant combinations (e.g., \{gold, apple\} and \{notebook, book\}) are discovered in HUIM. To address this limitation, many algorithms have been proposed to mine correlated high utility itemsets (CoHUIs). In this paper, we propose a novel algorithm called the Itemset Utility Maximization with Correlation Measure (CoIUM), which considers both a strong correlation and the profitable values of the items. Besides, the novel algorithm adopts a database projection mechanism to reduce the cost of database scanning. Moreover, two upper bounds and four pruning strategies are utilized to effectively prune the search space. And a concise array-based structure named utility-bin is used to calculate and store the adopted upper bounds in linear time and space. Finally, extensive experimental results on dense and sparse datasets demonstrate that CoIUM significantly outperforms the state-of-the-art algorithms in terms of runtime and memory consumption.
Supervised multi-specialist topic model with applications on large-scale electronic health record data
May 04, 2021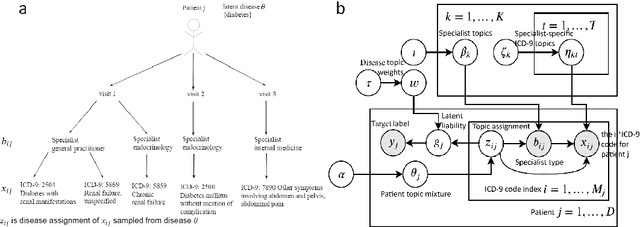
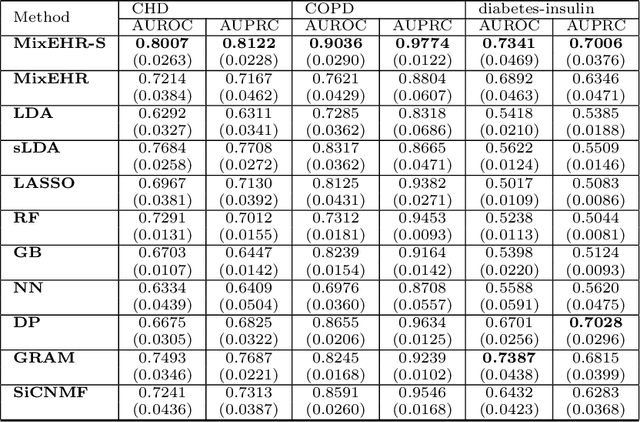
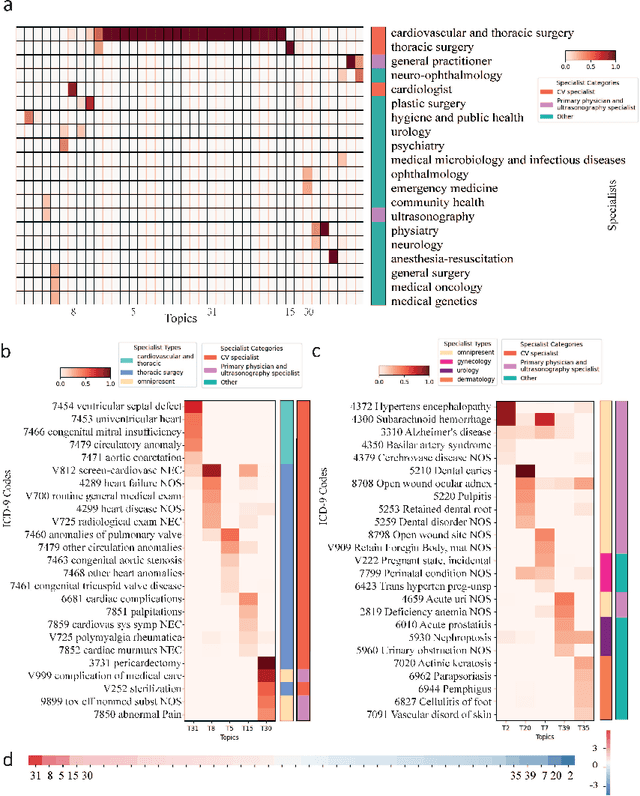
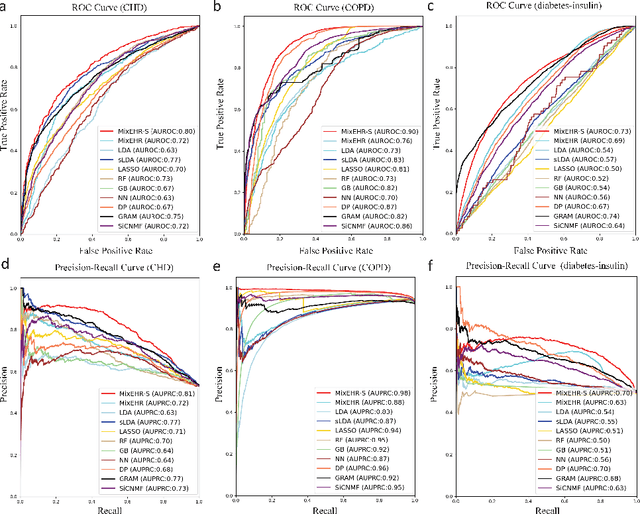
Motivation: Electronic health record (EHR) data provides a new venue to elucidate disease comorbidities and latent phenotypes for precision medicine. To fully exploit its potential, a realistic data generative process of the EHR data needs to be modelled. We present MixEHR-S to jointly infer specialist-disease topics from the EHR data. As the key contribution, we model the specialist assignments and ICD-coded diagnoses as the latent topics based on patient's underlying disease topic mixture in a novel unified supervised hierarchical Bayesian topic model. For efficient inference, we developed a closed-form collapsed variational inference algorithm to learn the model distributions of MixEHR-S. We applied MixEHR-S to two independent large-scale EHR databases in Quebec with three targeted applications: (1) Congenital Heart Disease (CHD) diagnostic prediction among 154,775 patients; (2) Chronic obstructive pulmonary disease (COPD) diagnostic prediction among 73,791 patients; (3) future insulin treatment prediction among 78,712 patients diagnosed with diabetes as a mean to assess the disease exacerbation. In all three applications, MixEHR-S conferred clinically meaningful latent topics among the most predictive latent topics and achieved superior target prediction accuracy compared to the existing methods, providing opportunities for prioritizing high-risk patients for healthcare services. MixEHR-S source code and scripts of the experiments are freely available at https://github.com/li-lab-mcgill/mixehrS