 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTikTalk: A Multi-Modal Dialogue Dataset for Real-World Chitchat
Paper and Code

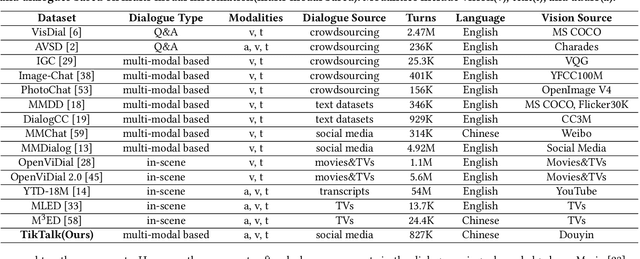

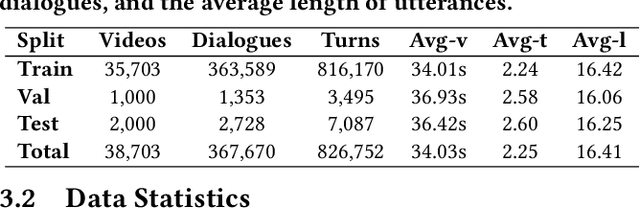
We present a novel multi-modal chitchat dialogue dataset-TikTalk aimed at facilitating the research of intelligent chatbots. It consists of the videos and corresponding dialogues users generate on video social applications. In contrast to existing multi-modal dialogue datasets, we construct dialogue corpora based on video comment-reply pairs, which is more similar to chitchat in real-world dialogue scenarios. Our dialogue context includes three modalities: text, vision, and audio. Compared with previous image-based dialogue datasets, the richer sources of context in TikTalk lead to a greater diversity of conversations. TikTalk contains over 38K videos and 367K dialogues. Data analysis shows that responses in TikTalk are in correlation with various contexts and external knowledge. It poses a great challenge for the deep understanding of multi-modal information and the generation of responses. We evaluate several baselines on three types of automatic metrics and conduct case studies. Experimental results demonstrate that there is still a large room for future improvement on TikTalk. Our dataset is available at \url{https://github.com/RUC-AIMind/TikTalk}.