 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Pipelines: Learning Dynamic Workflows for Text-to-SQL
Feb 17, 2026Text-to-SQL has recently achieved impressive progress, yet remains difficult to apply effectively in real-world scenarios. This gap stems from the reliance on single static workflows, fundamentally limiting scalability to out-of-distribution and long-tail scenarios. Instead of requiring users to select suitable methods through extensive experimentation, we attempt to enable systems to adaptively construct workflows at inference time. Through theoretical and empirical analysis, we demonstrate that optimal dynamic policies consistently outperform the best static workflow, with performance gains fundamentally driven by heterogeneity across candidate workflows. Motivated by this, we propose SquRL, a reinforcement learning framework that enhances LLMs' reasoning capability in adaptive workflow construction. We design a rule-based reward function and introduce two effective training mechanisms: dynamic actor masking to encourage broader exploration, and pseudo rewards to improve training efficiency. Experiments on widely-used Text-to-SQL benchmarks demonstrate that dynamic workflow construction consistently outperforms the best static workflow methods, with especially pronounced gains on complex and out-of-distribution queries. The codes are available at https://github.com/Satissss/SquRL
ForesightKV: Optimizing KV Cache Eviction for Reasoning Models by Learning Long-Term Contribution
Feb 03, 2026Recently, large language models (LLMs) have shown remarkable reasoning abilities by producing long reasoning traces. However, as the sequence length grows, the key-value (KV) cache expands linearly, incurring significant memory and computation costs. Existing KV cache eviction methods mitigate this issue by discarding less important KV pairs, but often fail to capture complex KV dependencies, resulting in performance degradation. To better balance efficiency and performance, we introduce ForesightKV, a training-based KV cache eviction framework that learns to predict which KV pairs to evict during long-text generations. We first design the Golden Eviction algorithm, which identifies the optimal eviction KV pairs at each step using future attention scores. These traces and the scores at each step are then distilled via supervised training with a Pairwise Ranking Loss. Furthermore, we formulate cache eviction as a Markov Decision Process and apply the GRPO algorithm to mitigate the significant language modeling loss increase on low-entropy tokens. Experiments on AIME2024 and AIME2025 benchmarks of three reasoning models demonstrate that ForesightKV consistently outperforms prior methods under only half the cache budget, while benefiting synergistically from both supervised and reinforcement learning approaches.
FastV-RAG: Towards Fast and Fine-Grained Video QA with Retrieval-Augmented Generation
Jan 07, 2026Vision-Language Models (VLMs) excel at visual reasoning but still struggle with integrating external knowledge. Retrieval-Augmented Generation (RAG) is a promising solution, but current methods remain inefficient and often fail to maintain high answer quality. To address these challenges, we propose VideoSpeculateRAG, an efficient VLM-based RAG framework built on two key ideas. First, we introduce a speculative decoding pipeline: a lightweight draft model quickly generates multiple answer candidates, which are then verified and refined by a more accurate heavyweight model, substantially reducing inference latency without sacrificing correctness. Second, we identify a major source of error - incorrect entity recognition in retrieved knowledge - and mitigate it with a simple yet effective similarity-based filtering strategy that improves entity alignment and boosts overall answer accuracy. Experiments demonstrate that VideoSpeculateRAG achieves comparable or higher accuracy than standard RAG approaches while accelerating inference by approximately 2x. Our framework highlights the potential of combining speculative decoding with retrieval-augmented reasoning to enhance efficiency and reliability in complex, knowledge-intensive multimodal tasks.
RP-CATE: Recurrent Perceptron-based Channel Attention Transformer Encoder for Industrial Hybrid Modeling
Dec 22, 2025Nowadays, industrial hybrid modeling which integrates both mechanistic modeling and machine learning-based modeling techniques has attracted increasing interest from scholars due to its high accuracy, low computational cost, and satisfactory interpretability. Nevertheless, the existing industrial hybrid modeling methods still face two main limitations. First, current research has mainly focused on applying a single machine learning method to one specific task, failing to develop a comprehensive machine learning architecture suitable for modeling tasks, which limits their ability to effectively represent complex industrial scenarios. Second, industrial datasets often contain underlying associations (e.g., monotonicity or periodicity) that are not adequately exploited by current research, which can degrade model's predictive performance. To address these limitations, this paper proposes the Recurrent Perceptron-based Channel Attention Transformer Encoder (RP-CATE), with three distinctive characteristics: 1: We developed a novel architecture by replacing the self-attention mechanism with channel attention and incorporating our proposed Recurrent Perceptron (RP) Module into Transformer, achieving enhanced effectiveness for industrial modeling tasks compared to the original Transformer. 2: We proposed a new data type called Pseudo-Image Data (PID) tailored for channel attention requirements and developed a cyclic sliding window method for generating PID. 3: We introduced the concept of Pseudo-Sequential Data (PSD) and a method for converting industrial datasets into PSD, which enables the RP Module to capture the underlying associations within industrial dataset more effectively. An experiment aimed at hybrid modeling in chemical engineering was conducted by using RP-CATE and the experimental results demonstrate that RP-CATE achieves the best performance compared to other baseline models.
LiveLongBench: Tackling Long-Context Understanding for Spoken Texts from Live Streams
Apr 24, 2025Long-context understanding poses significant challenges in natural language processing, particularly for real-world dialogues characterized by speech-based elements, high redundancy, and uneven information density. Although large language models (LLMs) achieve impressive results on existing benchmarks, these datasets fail to reflect the complexities of such texts, limiting their applicability to practical scenarios. To bridge this gap, we construct the first spoken long-text dataset, derived from live streams, designed to reflect the redundancy-rich and conversational nature of real-world scenarios. We construct tasks in three categories: retrieval-dependent, reasoning-dependent, and hybrid. We then evaluate both popular LLMs and specialized methods to assess their ability to understand long-contexts in these tasks. Our results show that current methods exhibit strong task-specific preferences and perform poorly on highly redundant inputs, with no single method consistently outperforming others. We propose a new baseline that better handles redundancy in spoken text and achieves strong performance across tasks. Our findings highlight key limitations of current methods and suggest future directions for improving long-context understanding. Finally, our benchmark fills a gap in evaluating long-context spoken language understanding and provides a practical foundation for developing real-world e-commerce systems. The code and benchmark are available at https://github.com/Yarayx/livelongbench.
Domain-Specific Pruning of Large Mixture-of-Experts Models with Few-shot Demonstrations
Apr 09, 2025



Mixture-of-Experts (MoE) models achieve a favorable trade-off between performance and inference efficiency by activating only a subset of experts. However, the memory overhead of storing all experts remains a major limitation, especially in large-scale MoE models such as DeepSeek-R1 (671B). In this study, we investigate domain specialization and expert redundancy in large-scale MoE models and uncover a consistent behavior we term few-shot expert localization, with only a few demonstrations, the model consistently activates a sparse and stable subset of experts. Building on this observation, we propose a simple yet effective pruning framework, EASY-EP, that leverages a few domain-specific demonstrations to identify and retain only the most relevant experts. EASY-EP comprises two key components: output-aware expert importance assessment and expert-level token contribution estimation. The former evaluates the importance of each expert for the current token by considering the gating scores and magnitudes of the outputs of activated experts, while the latter assesses the contribution of tokens based on representation similarities after and before routed experts. Experiments show that our method can achieve comparable performances and $2.99\times$ throughput under the same memory budget with full DeepSeek-R1 with only half the experts. Our code is available at https://github.com/RUCAIBox/EASYEP.
LinkAlign: Scalable Schema Linking for Real-World Large-Scale Multi-Database Text-to-SQL
Mar 25, 2025Schema linking is a critical bottleneck in achieving human-level performance in Text-to-SQL tasks, particularly in real-world large-scale multi-database scenarios. Addressing schema linking faces two major challenges: (1) Database Retrieval: selecting the correct database from a large schema pool in multi-database settings, while filtering out irrelevant ones. (2) Schema Item Grounding: accurately identifying the relevant tables and columns from within a large and redundant schema for SQL generation. To address this, we introduce LinkAlign, a novel framework that can effectively adapt existing baselines to real-world environments by systematically addressing schema linking. Our framework comprises three key steps: multi-round semantic enhanced retrieval and irrelevant information isolation for Challenge 1, and schema extraction enhancement for Challenge 2. We evaluate our method performance of schema linking on the SPIDER and BIRD benchmarks, and the ability to adapt existing Text-to-SQL models to real-world environments on the SPIDER 2.0-lite benchmark. Experiments show that LinkAlign outperforms existing baselines in multi-database settings, demonstrating its effectiveness and robustness. On the other hand, our method ranks highest among models excluding those using long chain-of-thought reasoning LLMs. This work bridges the gap between current research and real-world scenarios, providing a practical solution for robust and scalable schema linking. The codes are available at https://github.com/Satissss/LinkAlign.
DoTA: Weight-Decomposed Tensor Adaptation for Large Language Models
Dec 30, 2024



Low-rank adaptation (LoRA) reduces the computational and memory demands of fine-tuning large language models (LLMs) by approximating updates with low-rank matrices. However, low-rank approximation in two-dimensional space fails to capture high-dimensional structures within the target matrix. Recently, tensor decomposition methods have been explored for fine-tuning LLMs, leveraging their ability to extract structured information. Yet, these approaches primarily rely on random initialization, and the impact of initialization on tensor adaptation remains underexplored. In this paper, we reveal that random initialization significantly diverges from the validation loss achieved by full fine-tuning. To address this, we propose Weight-Decomposed Tensor Adaptation (DoTA), which leverages the Matrix Product Operator (MPO) decomposition of pre-trained weights for effective initialization in fine-tuning LLMs. Additionally, we introduce QDoTA, a quantized version of DoTA designed for 4-bit quantization. Experiments on commonsense and arithmetic reasoning tasks show that DoTA outperforms random initialization methods with fewer parameters. QDoTA further reduces memory consumption and achieves comparable performance to DoTA on commonsense reasoning tasks. We will release our code to support future research.
Unlocking Data-free Low-bit Quantization with Matrix Decomposition for KV Cache Compression
May 21, 2024Key-value~(KV) caching is an important technique to accelerate the inference of large language models~(LLMs), but incurs significant memory overhead. To compress the size of KV cache, existing methods often compromise precision or require extra data for calibration, limiting their practicality in LLM deployment. In this paper, we introduce \textbf{DecoQuant}, a novel data-free low-bit quantization technique based on tensor decomposition methods, to effectively compress KV cache. Our core idea is to adjust the outlier distribution of the original matrix by performing tensor decomposition, so that the quantization difficulties are migrated from the matrix to decomposed local tensors. Specially, we find that outliers mainly concentrate on small local tensors, while large tensors tend to have a narrower value range. Based on this finding, we propose to apply low-bit quantization to the large tensor, while maintaining high-precision representation for the small tensor. Furthermore, we utilize the proposed quantization method to compress the KV cache of LLMs to accelerate the inference and develop an efficient dequantization kernel tailored specifically for DecoQuant. Through extensive experiments, DecoQuant demonstrates remarkable efficiency gains, showcasing up to a $\sim$75\% reduction in memory footprint while maintaining comparable generation quality.
How ChatGPT is Solving Vulnerability Management Problem
Nov 11, 2023
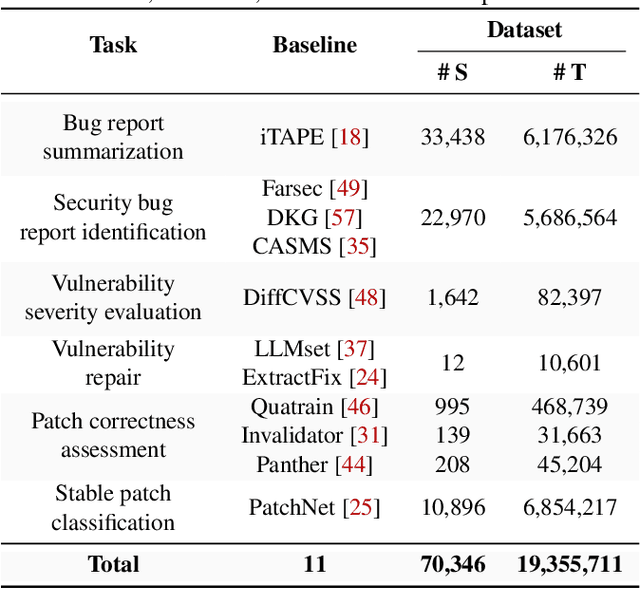


Recently, ChatGPT has attracted great attention from the code analysis domain. Prior works show that ChatGPT has the capabilities of processing foundational code analysis tasks, such as abstract syntax tree generation, which indicates the potential of using ChatGPT to comprehend code syntax and static behaviors. However, it is unclear whether ChatGPT can complete more complicated real-world vulnerability management tasks, such as the prediction of security relevance and patch correctness, which require an all-encompassing understanding of various aspects, including code syntax, program semantics, and related manual comments. In this paper, we explore ChatGPT's capabilities on 6 tasks involving the complete vulnerability management process with a large-scale dataset containing 78,445 samples. For each task, we compare ChatGPT against SOTA approaches, investigate the impact of different prompts, and explore the difficulties. The results suggest promising potential in leveraging ChatGPT to assist vulnerability management. One notable example is ChatGPT's proficiency in tasks like generating titles for software bug reports. Furthermore, our findings reveal the difficulties encountered by ChatGPT and shed light on promising future directions. For instance, directly providing random demonstration examples in the prompt cannot consistently guarantee good performance in vulnerability management. By contrast, leveraging ChatGPT in a self-heuristic way -- extracting expertise from demonstration examples itself and integrating the extracted expertise in the prompt is a promising research direction. Besides, ChatGPT may misunderstand and misuse the information in the prompt. Consequently, effectively guiding ChatGPT to focus on helpful information rather than the irrelevant content is still an open problem.