 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausally Consistent Normalizing Flow
Dec 16, 2024



Causal inconsistency arises when the underlying causal graphs captured by generative models like \textit{Normalizing Flows} (NFs) are inconsistent with those specified in causal models like \textit{Struct Causal Models} (SCMs). This inconsistency can cause unwanted issues including the unfairness problem. Prior works to achieve causal consistency inevitably compromise the expressiveness of their models by disallowing hidden layers. In this work, we introduce a new approach: \textbf{C}ausally \textbf{C}onsistent \textbf{N}ormalizing \textbf{F}low (CCNF). To the best of our knowledge, CCNF is the first causally consistent generative model that can approximate any distribution with multiple layers. CCNF relies on two novel constructs: a sequential representation of SCMs and partial causal transformations. These constructs allow CCNF to inherently maintain causal consistency without sacrificing expressiveness. CCNF can handle all forms of causal inference tasks, including interventions and counterfactuals. Through experiments, we show that CCNF outperforms current approaches in causal inference. We also empirically validate the practical utility of CCNF by applying it to real-world datasets and show how CCNF addresses challenges like unfairness effectively.
mmSpyVR: Exploiting mmWave Radar for Penetrating Obstacles to Uncover Privacy Vulnerability of Virtual Reality
Nov 15, 2024



Virtual reality (VR), while enhancing user experiences, introduces significant privacy risks. This paper reveals a novel vulnerability in VR systems that allows attackers to capture VR privacy through obstacles utilizing millimeter-wave (mmWave) signals without physical intrusion and virtual connection with the VR devices. We propose mmSpyVR, a novel attack on VR user's privacy via mmWave radar. The mmSpyVR framework encompasses two main parts: (i) A transfer learning-based feature extraction model to achieve VR feature extraction from mmWave signal. (ii) An attention-based VR privacy spying module to spy VR privacy information from the extracted feature. The mmSpyVR demonstrates the capability to extract critical VR privacy from the mmWave signals that have penetrated through obstacles. We evaluate mmSpyVR through IRB-approved user studies. Across 22 participants engaged in four experimental scenes utilizing VR devices from three different manufacturers, our system achieves an application recognition accuracy of 98.5\% and keystroke recognition accuracy of 92.6\%. This newly discovered vulnerability has implications across various domains, such as cybersecurity, privacy protection, and VR technology development. We also engage with VR manufacturer Meta to discuss and explore potential mitigation strategies. Data and code are publicly available for scrutiny and research at https://github.com/luoyumei1-a/mmSpyVR/
FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
Nov 18, 2023



Given the capability of mitigating the long-tail deficiencies and intricate-shaped absence prevalent in 3D object detection, occupancy prediction has become a pivotal component in autonomous driving systems. However, the procession of three-dimensional voxel-level representations inevitably introduces large overhead in both memory and computation, obstructing the deployment of to-date occupancy prediction approaches. In contrast to the trend of making the model larger and more complicated, we argue that a desirable framework should be deployment-friendly to diverse chips while maintaining high precision. To this end, we propose a plug-and-play paradigm, namely FlashOCC, to consolidate rapid and memory-efficient occupancy prediction while maintaining high precision. Particularly, our FlashOCC makes two improvements based on the contemporary voxel-level occupancy prediction approaches. Firstly, the features are kept in the BEV, enabling the employment of efficient 2D convolutional layers for feature extraction. Secondly, a channel-to-height transformation is introduced to lift the output logits from the BEV into the 3D space. We apply the FlashOCC to diverse occupancy prediction baselines on the challenging Occ3D-nuScenes benchmarks and conduct extensive experiments to validate the effectiveness. The results substantiate the superiority of our plug-and-play paradigm over previous state-of-the-art methods in terms of precision, runtime efficiency, and memory costs, demonstrating its potential for deployment. The code will be made available.
How ChatGPT is Solving Vulnerability Management Problem
Nov 11, 2023
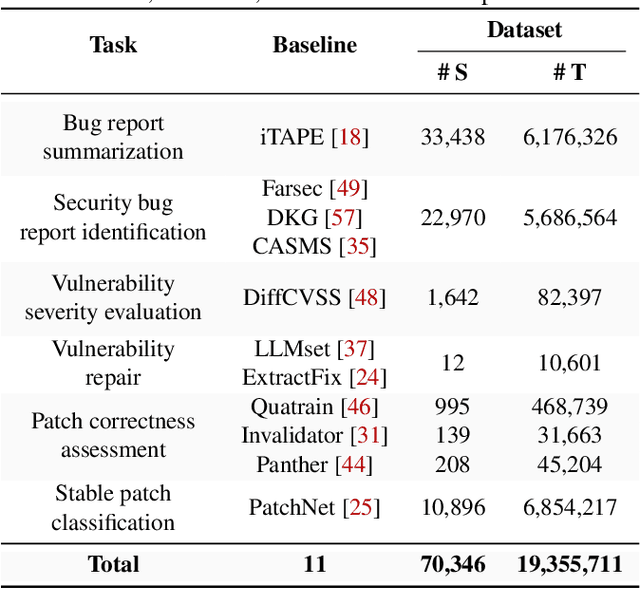


Recently, ChatGPT has attracted great attention from the code analysis domain. Prior works show that ChatGPT has the capabilities of processing foundational code analysis tasks, such as abstract syntax tree generation, which indicates the potential of using ChatGPT to comprehend code syntax and static behaviors. However, it is unclear whether ChatGPT can complete more complicated real-world vulnerability management tasks, such as the prediction of security relevance and patch correctness, which require an all-encompassing understanding of various aspects, including code syntax, program semantics, and related manual comments. In this paper, we explore ChatGPT's capabilities on 6 tasks involving the complete vulnerability management process with a large-scale dataset containing 78,445 samples. For each task, we compare ChatGPT against SOTA approaches, investigate the impact of different prompts, and explore the difficulties. The results suggest promising potential in leveraging ChatGPT to assist vulnerability management. One notable example is ChatGPT's proficiency in tasks like generating titles for software bug reports. Furthermore, our findings reveal the difficulties encountered by ChatGPT and shed light on promising future directions. For instance, directly providing random demonstration examples in the prompt cannot consistently guarantee good performance in vulnerability management. By contrast, leveraging ChatGPT in a self-heuristic way -- extracting expertise from demonstration examples itself and integrating the extracted expertise in the prompt is a promising research direction. Besides, ChatGPT may misunderstand and misuse the information in the prompt. Consequently, effectively guiding ChatGPT to focus on helpful information rather than the irrelevant content is still an open problem.