 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIoT-based Continuous, Contextualized, and Explainable Driving Assessment for Older Adults
Feb 28, 2026The world is undergoing a major demographic shift as older adults become a rapidly growing share of the population, creating new challenges for driving safety. In car-dependent regions such as the United States, driving remains essential for independence, access to services, and social participation. At the same time, aging can introduce gradual changes in vision, attention, reaction time, and driving control that quietly reduce safety. Today's assessment methods rely largely on infrequent clinic visits or simple screening tools, offering only a brief snapshot and failing to reflect how an older adult actually drives on the road. Our work starts from the observation that everyday driving provides a continuous record of functional ability and captures how a driver responds to traffic, navigates complex roads, and manages routine behavior. Leveraging this insight, we propose AURA, an Artificial Intelligence of Things (AIoT) framework for continuous, real-world assessment of driving safety among older adults. AURA integrates richer in-vehicle sensing, multi-scale behavioral modeling, and context-aware analysis to extract detailed indicators of driving performance from routine trips. It organizes fine-grained actions into longer behavioral trajectories and separates age-related performance changes from situational factors such as traffic, road design, or weather. By integrating sensing, modeling, and interpretation within a privacy-preserving edge architecture, AURA provides a foundation for proactive, individualized support that helps older adults drive safely. This paper outlines the design principles, challenges, and research opportunities needed to build reliable, real-world monitoring systems that promote safer aging behind the wheel.
mmSpyVR: Exploiting mmWave Radar for Penetrating Obstacles to Uncover Privacy Vulnerability of Virtual Reality
Nov 15, 2024



Virtual reality (VR), while enhancing user experiences, introduces significant privacy risks. This paper reveals a novel vulnerability in VR systems that allows attackers to capture VR privacy through obstacles utilizing millimeter-wave (mmWave) signals without physical intrusion and virtual connection with the VR devices. We propose mmSpyVR, a novel attack on VR user's privacy via mmWave radar. The mmSpyVR framework encompasses two main parts: (i) A transfer learning-based feature extraction model to achieve VR feature extraction from mmWave signal. (ii) An attention-based VR privacy spying module to spy VR privacy information from the extracted feature. The mmSpyVR demonstrates the capability to extract critical VR privacy from the mmWave signals that have penetrated through obstacles. We evaluate mmSpyVR through IRB-approved user studies. Across 22 participants engaged in four experimental scenes utilizing VR devices from three different manufacturers, our system achieves an application recognition accuracy of 98.5\% and keystroke recognition accuracy of 92.6\%. This newly discovered vulnerability has implications across various domains, such as cybersecurity, privacy protection, and VR technology development. We also engage with VR manufacturer Meta to discuss and explore potential mitigation strategies. Data and code are publicly available for scrutiny and research at https://github.com/luoyumei1-a/mmSpyVR/
ESP-PCT: Enhanced VR Semantic Performance through Efficient Compression of Temporal and Spatial Redundancies in Point Cloud Transformers
Sep 02, 2024



Semantic recognition is pivotal in virtual reality (VR) applications, enabling immersive and interactive experiences. A promising approach is utilizing millimeter-wave (mmWave) signals to generate point clouds. However, the high computational and memory demands of current mmWave point cloud models hinder their efficiency and reliability. To address this limitation, our paper introduces ESP-PCT, a novel Enhanced Semantic Performance Point Cloud Transformer with a two-stage semantic recognition framework tailored for VR applications. ESP-PCT takes advantage of the accuracy of sensory point cloud data and optimizes the semantic recognition process, where the localization and focus stages are trained jointly in an end-to-end manner. We evaluate ESP-PCT on various VR semantic recognition conditions, demonstrating substantial enhancements in recognition efficiency. Notably, ESP-PCT achieves a remarkable accuracy of 93.2% while reducing the computational requirements (FLOPs) by 76.9% and memory usage by 78.2% compared to the existing Point Transformer model simultaneously. These underscore ESP-PCT's potential in VR semantic recognition by achieving high accuracy and reducing redundancy. The code and data of this project are available at \url{https://github.com/lymei-SEU/ESP-PCT}.
NN-Defined Modulator: Reconfigurable and Portable Software Modulator on IoT Gateways
Mar 14, 2024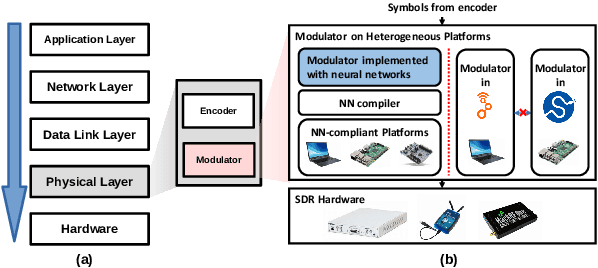
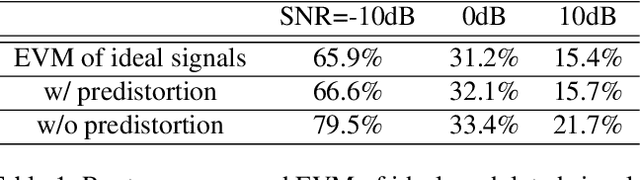
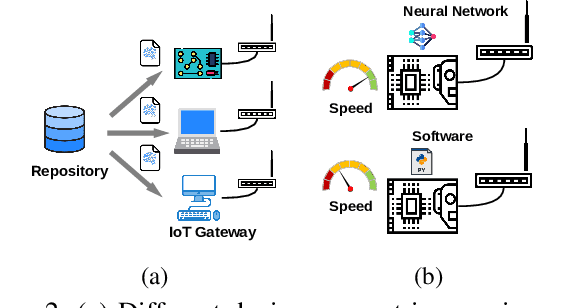

A physical-layer modulator is a vital component for an IoT gateway to map the symbols to signals. However, due to the soldered hardware chipsets on the gateway's motherboards or the diverse toolkits on different platforms for the software radio, the existing solutions either have limited extensibility or are platform-specific. Such limitation is hard to ignore when modulation schemes and hardware platforms have become extremely diverse. This paper presents a new paradigm of using neural networks as an abstraction layer for physical layer modulators in IoT gateway devices, referred to as NN-defined modulators. Our approach addresses the challenges of extensibility and portability for multiple technologies on various hardware platforms. The proposed NN-defined modulator uses a model-driven methodology rooted in solid mathematical foundations while having native support for hardware acceleration and portability to heterogeneous platforms. We conduct the evaluation of NN-defined modulators on different platforms, including Nvidia Jetson Nano and Raspberry Pi. Evaluations demonstrate that our NN-defined modulator effectively operates as conventional modulators and provides significant efficiency gains (up to $4.7\times$ on Nvidia Jetson Nano and $1.1\times$ on Raspberry Pi), indicating high portability. Furthermore, we show the real-world applications using our NN-defined modulators to generate ZigBee and WiFi packets, which are compliant with commodity TI CC2650 (ZigBee) and Intel AX201 (WiFi NIC), respectively.
Cross Vision-RF Gait Re-identification with Low-cost RGB-D Cameras and mmWave Radars
Jul 16, 2022
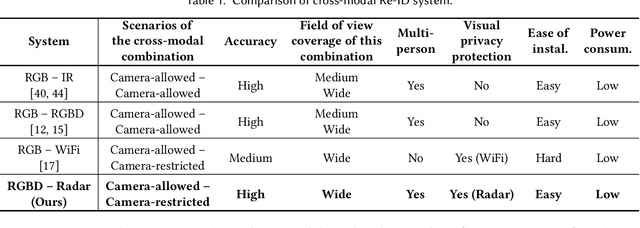
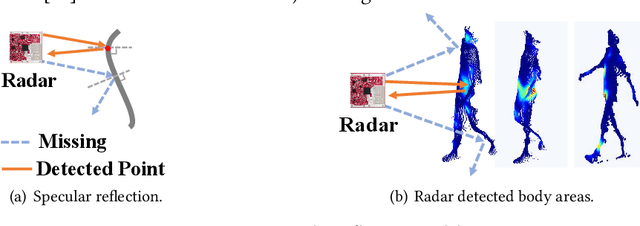
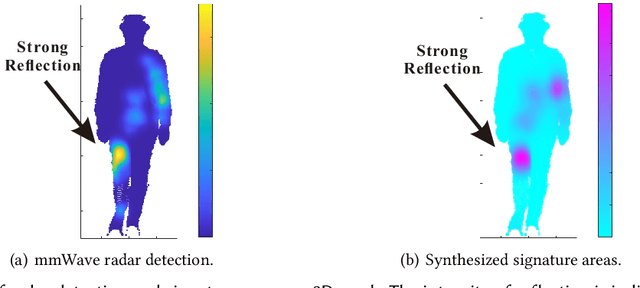
Human identification is a key requirement for many applications in everyday life, such as personalized services, automatic surveillance, continuous authentication, and contact tracing during pandemics, etc. This work studies the problem of cross-modal human re-identification (ReID), in response to the regular human movements across camera-allowed regions (e.g., streets) and camera-restricted regions (e.g., offices) deployed with heterogeneous sensors. By leveraging the emerging low-cost RGB-D cameras and mmWave radars, we propose the first-of-its-kind vision-RF system for cross-modal multi-person ReID at the same time. Firstly, to address the fundamental inter-modality discrepancy, we propose a novel signature synthesis algorithm based on the observed specular reflection model of a human body. Secondly, an effective cross-modal deep metric learning model is introduced to deal with interference caused by unsynchronized data across radars and cameras. Through extensive experiments in both indoor and outdoor environments, we demonstrate that our proposed system is able to achieve ~92.5% top-1 accuracy and ~97.5% top-5 accuracy out of 56 volunteers. We also show that our proposed system is able to robustly reidentify subjects even when multiple subjects are present in the sensors' field of view.